
安装 Zookeeper 单机版
下面安装 Zookeeper,由于它是 Apache 的一个顶级项目,所以域名是 zookeeper.apache.org,所有 Apache 的顶级项目的官网都是以项目名 .apache.org 来命名的。
点击 Download 即可下载,这里我们选择的版本是 3.5.10,下载之后扔到服务器上。由于 Zookeeper 是基于 Java 语言编写的,所以还需要安装 JDK,这里我使用的是 JDK1.8,都已经已经安装好了,并配置了环境变量。

我们安装完毕之后不能直接用,还需要修改一下 Zookeeper 的配置文件。在安装目录的 conf 目录下,里面有一个 zoo_sample.cfg,我们将其重命名为 zoo.cfg,然后打开。
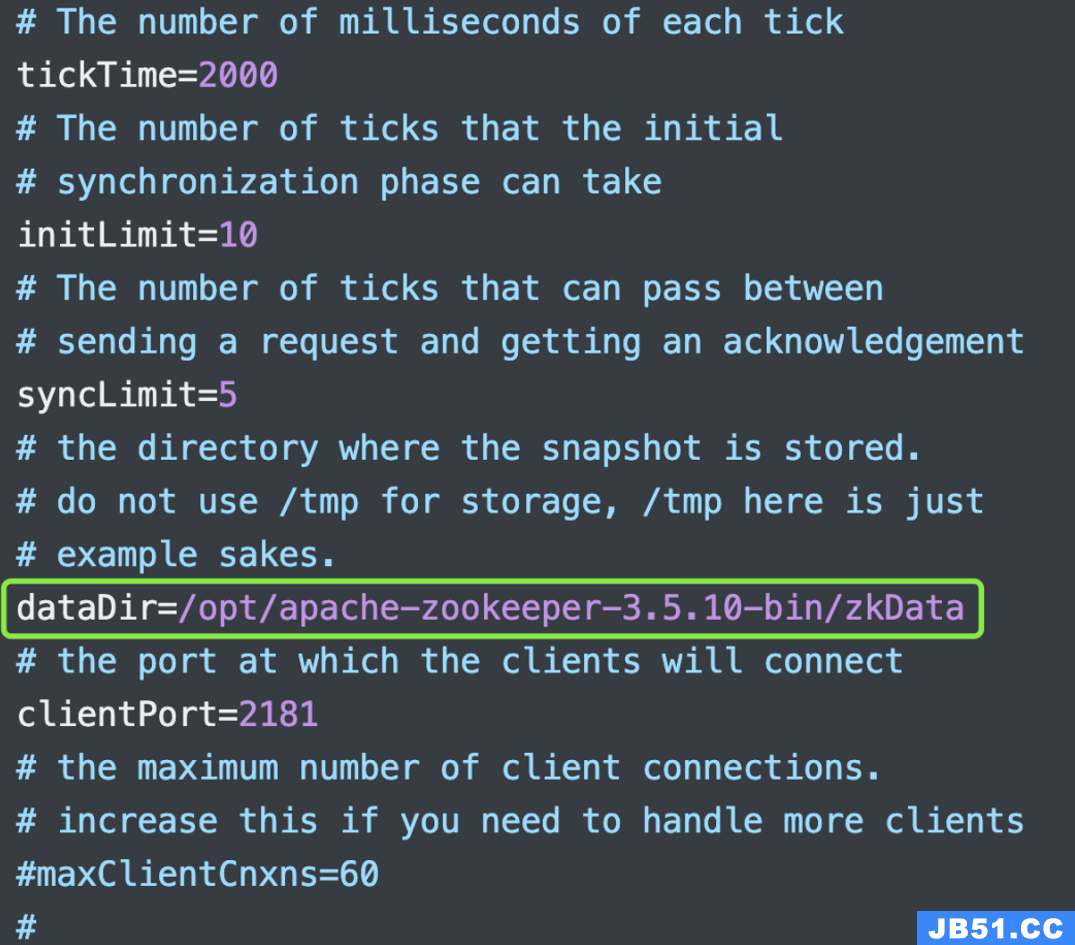
里面有一个 dataDir 参数,表示数据的存储目录,数据在持久化之后会存储在该目录中,以防止数据丢失。但该目录默认位于临时目录 /tmp 下面,这样当节点重启之后数据就没了,所以需要换一个目录(要提前创建好),至于目录名无所谓,我这里叫 zkData。
关于配置文件里的其他参数,我们之后会解读,下面先来启动服务。
bin 目录下有很多脚本,其中 .cmd 文件是在 Windows 上使用的,不用管。然后我们看到有一个 zkServer.sh,它就是负责启动 Zookeeper 服务的。
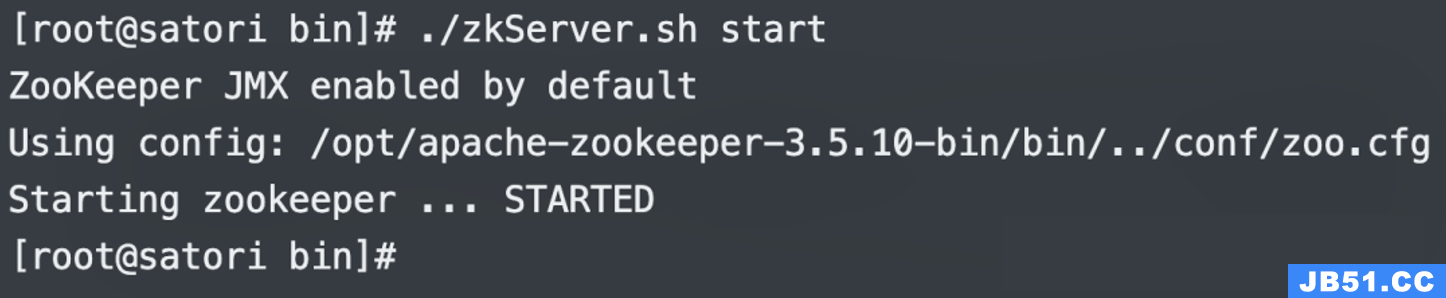
启动成功,我们调用 jps 查看进程。
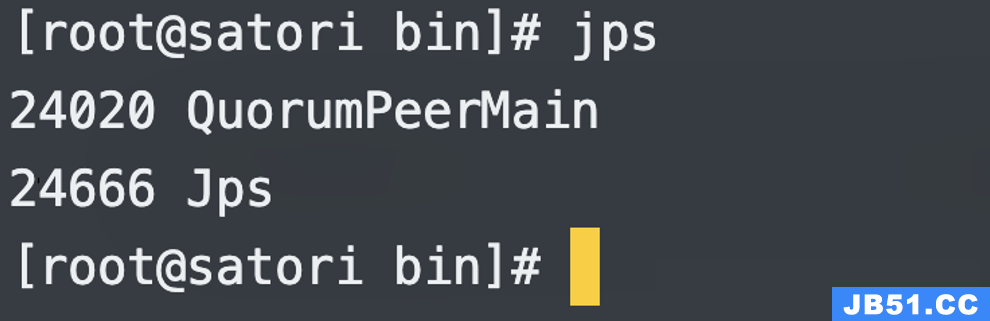
凡是基于 Java 语言编写的框架,在启动之后,都可以通过 jps 查看相应的进程。
要是看到输出了 QuorumPeerMain 就代表 Zookeeper 启动成功了,如果想 停止 服务,可以通过 zkServer.sh stop,重启 则是 zkServer.sh restart。
启动之后,我们也可以查看状态。
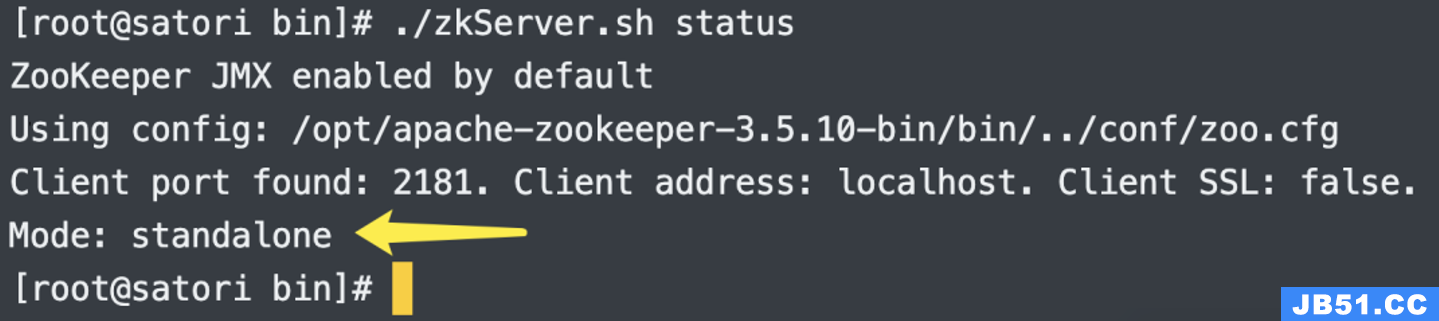
此时的模式是 standalone 模式,表示单机,当然后面我们也会搭建集群。
既然有了服务端,那么是不是也要有客户端呢,对的,类似于 Redis。下面启动客户端,直接 zkCli.sh 即可,不需要 start,出现如下表示启动成功。
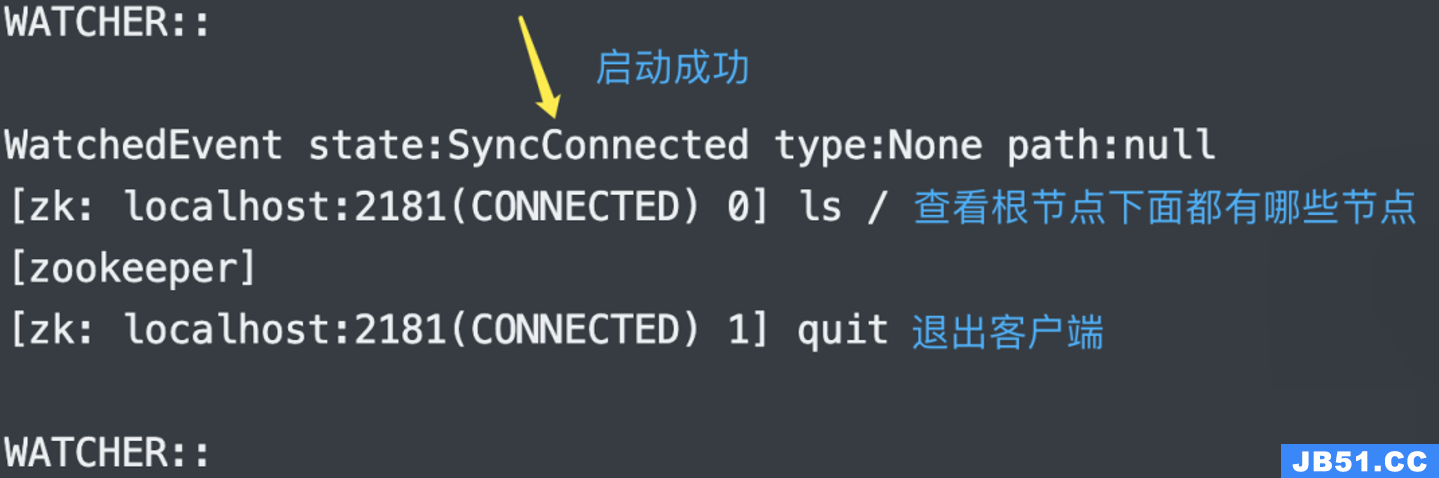
关于 Zookeeper 客户端的命令,后面详细介绍,我们来解读一下 Zookeeper 的配置文件。
配置项还是比较少的,解释一下它们的含义。
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/apache-zookeeper-3.5.10-bin/zkData
clientPort=2181
maxClientCnxns=60
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
-
tickTime:服务端与客户端的心跳时间,默认 2000 2000 2000 毫秒。表示客户端每隔 2 2 2 秒会向服务端发送一个心跳信息,表示自己还活着,服务端不要断开连接。当然,它还表示集群内多个节点之间的心跳时间。 -
initLimit:领导者和追随者第一次建立连接时的最大通信时限,默认是 10 10 10 个tickTime。如果超时,则表示连接建立失败。 -
syncLimit:领导者和追随者之间响应的最大时限(连接建立之后),单位同样是tickTime。如果领导者在超过syncLimit×tickTime之后没有收到追随者的响应,那么领导者会认为该追随者已经死掉,从而将其从服务器列表中删除。 -
dataDir:数据文件目录 + 数据持久化路径,主要用于保存 Zookeeper 中的数据,我们刚刚已经修改了。 -
clientPort:客户端和服务端通信的端口。 -
maxClientCnxns:服务端最多支持和多少个客户端建立连接,默认是 60 60 60。 -
autopurge.snapRetainCount:在dataDir中要保存的快照数量,多余的要被清除。 -
autopurge.purgeInterval:自动触发清除任务的时间间隔,单位小时。 -
admin.serverPort:这个参数没有写在配置文件中,但有必要说一下。Zookeeper 从 3.5 开始,启动之后会占用 8080 8080 8080 端口,因为内嵌了一个管理控制台。而 8080 8080 8080 端口很常见,如果启动时发现该端口被占用,那么 Zookeeper 会启动失败,此时便可通过该参数将端口改成其它的,比如 8081 8081 8081。
配置文件还是非常简单的,以上我们就完成了 Zookeeper 单机版的安装。
原文地址:https://blog.csdn.net/be_racle/article/details/135398419
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。