
国外数据集
-
NGSIM数据集
NGSIM数据集采集自美国,数据集中包含两条高速公路(US-101,I-80)及两条城市道路(lankershim,peachtree)的数据,每条道路的采集时间为45min。数据集中包含包含车辆ID、时间、速度、加速度、坐标、车道等信息,数据采样间隔为0.1s,速度单位为英尺/秒。数据集因其精度高、频率高、质量高、覆盖广的特点,被广泛用于模型标定、车辆行为决策等研究。数据集中部分参数说明如下:
| Vehicle_ID | 车辆ID |
| Frame_ID | 帧时间 |
| Global_Time | 全局时间 |
| Local_X | 相对X坐标 |
| Local_Y | 相对Y坐标 |
| Global_X | 绝对X坐标 |
| Global_Y | 绝对Y坐标 |
| v_length | 车长,单位:英尺 |
| v_Width | 车宽,单位:英尺 |
| v_Class | 车辆类型,1:摩托车;2:小型车;3:大型车 |
| v_Vel | 车辆速度,单位:英尺/秒 |
| v_Acc | 车辆加速度,单位:英尺/二次方秒 |
| Lane_ID | 车辆所在车道ID |
| Preceding | 前车ID,若没有前车,则该值为0 |
| Following | 后车ID,若没有后车,则该值为0 |
| Space_Headway | 车头间距,单位:英尺 |
| Time_Headway | 车头时距,单位:秒 |
-
highD数据集
highD数据集采集自德国科隆附近的六个不同地点,包含小型车和大型车两种类型车辆的数据,数据集踪迹采集时长为11.5小时,采集车辆数为110000辆,其中包含逾5000条完整的变道轨迹,需特别说明的是,highD数据集的坐标原点位于采集路段的左上方。数据集中车道类型包括2+2、3+3、3+3+1三种形式,其中2+2、3+3两种车道类型中车道ID编号见下图:


3+3+1的车道类型与六车道编号规则大体一致,车道8下方还存在车道ID为9的一条车道。
数据集总结包含60个子数据集,每个字数据集包含采集路段的航拍图、采集点数据、车辆轨迹数据。其中采集点数据给出了位置ID、时间、采集时长、车辆踪迹行驶距离、车辆数等信息,车辆轨迹数据中主要包括车辆ID、车辆坐标、速度、加速度等信息,车辆轨迹数据中部分参数说明吴如下:
| frame | 帧时间 |
| id | 车辆ID |
| x | 车辆X坐标 |
| y | 车辆Y坐标 |
| xVelocity | 车辆X方向速度 |
| yVelocity | 车辆Y方向速度 |
| xAcceleration | 车辆X方向加速度 |
| yAcceleration | 车辆Y方向加速度 |
| dhw | 车头间距 |
| thw | 车头时距 |
| ttc | 碰撞时间 |
| precedingId | 前车ID,若没有前车,则该值为0 |
| followingId | 后车ID,若没有后车,则该值为0 |
| laneId | 车辆所在车道 |
国内数据集
-
高速公路车辆汇入、汇出轨迹数据、城市快速路车辆汇入轨迹数据
高速公路汇入数据采集自某市高速公路汇入路口,采集时间为2020年,天气阴天,道路东西走向,左侧两条主干道,匝道位于右侧,路段限速80km/h,采集时长为30分钟,合流轨迹数量62条;高速公路汇出数据采集自某市高速路汇出路口,采集时间为2020年,天气多云,道路南北走向,右侧两条主干道,匝道位于左侧,采集时长为30分钟,分流轨迹数量290条;城市快速路车辆汇入数据采集自某市城市快速路汇入路口,采集时间为2019年,天气多云,道路南北走向,左侧三条主干道,两条汇入匝道位于左侧,采集时长为23.7分钟,含合流轨迹数量175条。
三个数据集中数据构成相同,均包含说明文档、道路及车道信息说明图、轨迹数据、每条轨迹数据的统计信息、采集设备和该时间内车流统计信息。
轨迹数据中部分参数说明如下:
| trackId | 交通参与物编号 |
| frameId | 帧时间 |
| classId | 交通参与物类型,1:行人;2:自行车;3:小型车;4:摩托车;6:公交车;7:货车 |
| localX | 交通参与物相对X坐标,单位:米 |
| localY | 交通参与物相对Y坐标,单位:米 |
| laneId | 所在车道ID |
| xVelocity | X方向速度,单位:米/秒 |
| yVelocity | Y方向速度,单位:米/秒 |
| xAcceleration | X方向加速度,单位:米/二次方秒 |
| yAcceleration | Y方向加速度,单位:米/二次方秒 |
轨迹统计信息中部分参数说明如下:
| trackId | 交通参与无编号 |
| InitialFrame | 出现帧数 |
| TotalFrame | 总出现帧数 |
| Distance | 行程距离,单位:米 |
| minVel | 最低速度,单位:米/秒 |
| maxVel | 最大速度,单位:米/秒 |
| meanVel | 平均速度,单位:米/秒 |
| VehicleClass | 交通参与物类型(person、bicycle、car、NonVehicle、bus、truck) |
| LaneChangeNum | 换道次数 |
| RampVehicle | 是否为匝道交通参与物 |
采集设备和该时间内车流统计信息部分参数说明如下:
| Date | 采集日期 |
| Time | 采集开始时间 |
| DurationTime | 采集时长,单位:分 |
| WeekDay | 是否为工作日 |
| TotalTrajectoryNumber | 追踪的轨迹数量 |
| TotalDistance | 总行程距离,单位:米 |
| TotalDriveTime | 总行程时间,单位:秒 |
| TotalCarNumber | 小型车数量 |
| TotalTruckNumber | 货车数量 |
| TotalPedestrianNumber | 行人数量 |
| TotalBusNumber | 公交车数量 |
| TotalNonVehicleNumber | 非机动车数量 |
| LaneChangeNumber | 交通参与物变道行为数量 |
| RampVehicleNumber | 交通参与物经过匝道数量 |
-
交通之眼数据集
交通之眼数据集由无人机航拍获得,车辆轨迹数据库包括车辆编号、位置坐标、车道编号、车辆长度、车辆宽度、行驶速度、车头时距、车头间距、加减速度等参数,时间精度为0.1秒,位置精度为0.01米,覆盖场景包括城市快速路航拍书局、城市交叉口航拍数据、城市快速路路侧检测数据、城市交叉口路侧检测数据等,包含六个子数据集(CKQ4/DATA SQM1/DATA SQM2/KZM5/KZM6/YTA3),交通状况包括自由流、自由流向拥堵演变、双向交织区。每个子数据集中均包括视频数据和车辆轨迹数据,部分子数据集中包含路段线形数据。车辆轨迹数据集中部分参数说明如下:
| Vehicle ID | 车辆ID |
| Lane ID | 车辆所在车道 |
| Time(s) | 时间,单位:秒 |
| LongtitudePosition(meter) | 横向坐标,单位:米 |
| LatitudePostion(meter) | 纵向位置,单位:米 |
| Speed(m/s) | 速度,单位:米/秒 |
| Acceleration(m/s^2) | 加速度,单位:米/二次方秒 |
| VehicleLength(pixel) | 车长,单位:像素 |
| VehicleWidth(pixel) | 车宽,单位:像素 |
车辆轨迹数据以CSV格式存储,截图如下:
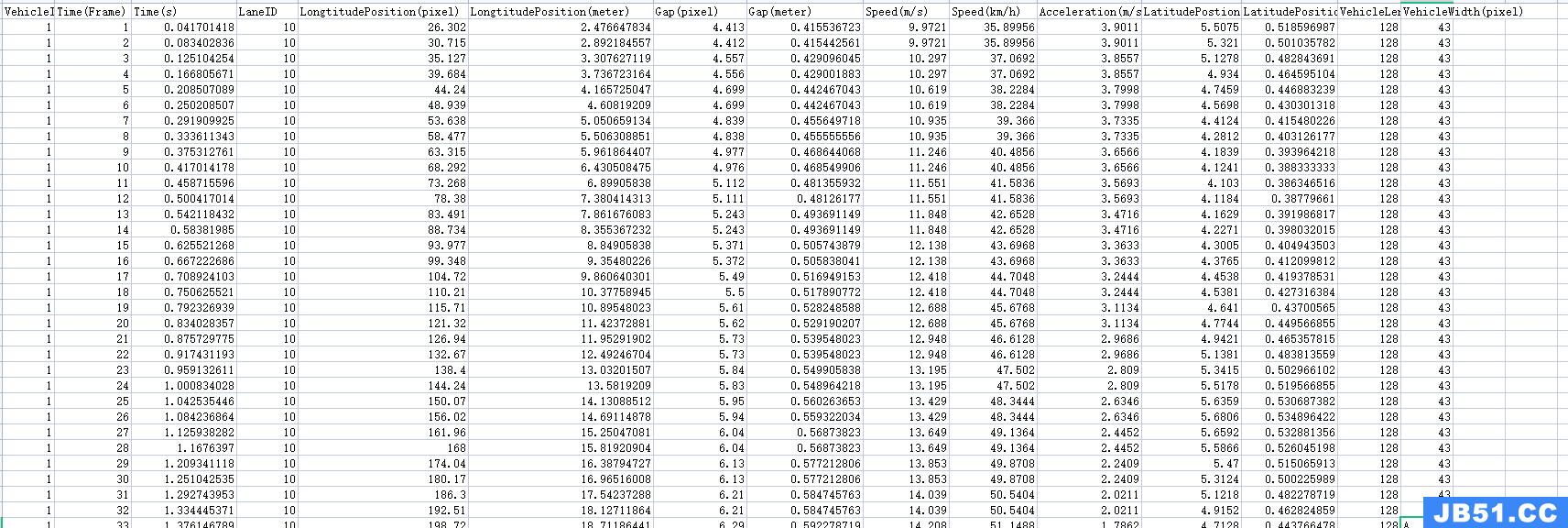
数据集中视频数据运行截图如下:

-
城市地下快速路车辆轨迹数据
数据采集自上海北横通道,使用毫米波雷达和边缘计算单元获取车辆轨迹、交通事件、交通运行状态等信息。北横通道设备安装范围全长435米,单向三车道,设计速度为60公里/小时,路段包括3个车道,车道宽度为3.2米。数据集中包含数据说明、车辆轨迹数据、路段纵断面图、路段平面线形图。车辆轨迹数据中部分参数说明如下:
| GlobalID |
车辆编号 |
| ObjectClass |
车辆类型,0:大货车;1:小客车 |
| BornTime |
车辆进入观测区域时间,单位:毫秒 |
| GoneTime |
车辆离开观测区域时间,单位:毫秒 |
| Timestamp |
时间戳,单位:毫秒 |
| PositionX |
车辆纵向位置,即平行道路方向距离道路起点的长度 |
| PositionY |
车辆所在车道编号,-25:上行方向最外侧车道;-15:上行方向中间车道;-5:上行方向最内侧车道 |
| VelocityX |
纵向车速,单位:米/秒 |
| VelocityY |
横向车速,单位:米/秒 |
| AbnormalState |
车辆状态,0:正常;1:蛇形行驶;2:超速;4:低速;8:急加速急减速;16:跟车过近;32:路段冲突。其余数字表示叠状态(如:5表示状态1表示4的叠加)。 |
-
成都滴滴数据
数据集中包含2016年11月的成都滴滴平台的车辆轨迹数据和车辆订单数据,字段使用中文字段,因此不再对其中的参数进行赘述,需要特别说明的是,数据类型为string,其中时间戳单位为秒,经纬度使用GCJ-02坐标系。车辆轨迹数据包含:司机ID、订单ID、时间戳、精度、维度,订单数据包含:订单ID、开始计费时间、结束计费时间、上车位置经度、上车位置维度、下车位置经度、下车位置维度。数据以TXT格式保存,以订单数据为例,数据截图见下:

需要注意的是,在对数据进行处理时,一般需要先转化为CSV文件。
-
济南公交数据
数据集提供了2017年6月27日济南56路公交的轨迹数据,数据采样间隔为30秒,数据集中包含数据类型(3:GPS;4:到离站;55:违规;47:DSRC检到离场;71:GPS到离场;53:开关门)、车载机编号、时间、经度、纬度、海拔、GPS速度、方向角、GPS里程等数据。数据集截图见下:

-
上海公交GPS数据
数据集中记录了上海公交71路的GPS行车数据,数据中包含车牌号、公交线路代码、时间、车辆上下行、经度、纬度、速度、行车方向数据,数据集中各参数说明见下表:
| FSTR_BUSID |
车牌 |
| FSTR_LINEID |
公交线路代码 |
| FDT_TIME |
时间,格式:年月日 时:分:秒 |
| FINT_LINEDIR |
上下行 |
| FFLT_LONGITUDE |
经度 |
| FFLT_LATITUDE |
纬度 |
| FFLT_SPEED |
速度,单位:千米/小时 |
| FINT_BUSDIR |
行车方向,以正北为0度 |
数据集以CSV格式存储,截图如下:
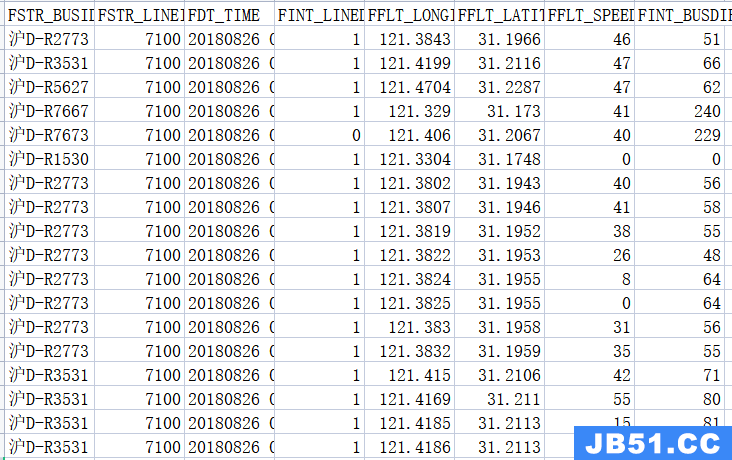
-
上海高架交通事故、流量速度数据
交通事故数据集中保存了上海延安高架在2018年8月和9月的车辆事件数据,包含事件开始时间、事件结束时间、事故所在高架发布段代码、位置描述、高架道路名称、事故描述,数据集中各参数说明见下表:
| FSTR_FINDTIME |
事件开始时间,格式:年/月/日 时:分 |
| FSTR_ACTUAL_ENDTIME |
事件结束时间,格式:年/月/日 时:分 |
| FSTR_EVENT_ISSUESECTID |
事故所在高架发布段代码 |
| FSTR_ROADNUMBER |
位置描述 |
| FSTR_ROADNAME |
高架道路名称 |
| FSTR_ROADASSET_DESC |
事故描述 |
数据集以CSV格式存储,截图如下:
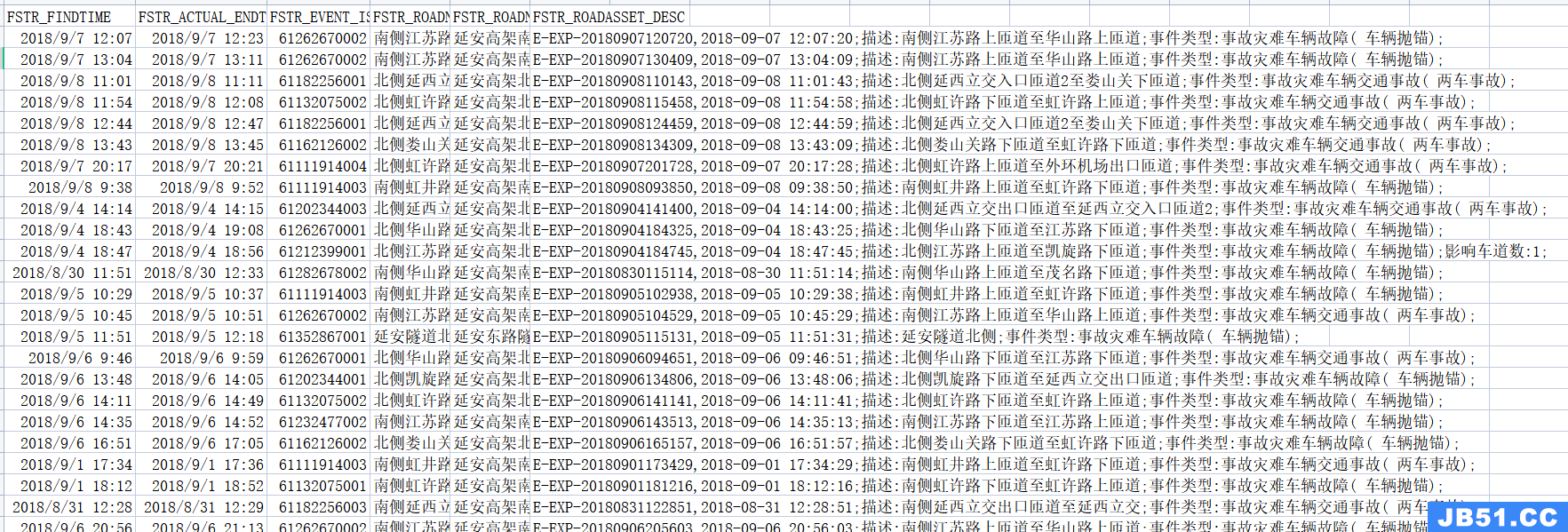
流量速度数据集以以2分钟为统计周期记录延安高架发布段行程车速、流量等基础交通流参数信息,包含时间、高架发布段代码、平均速度、平均车道流量、平均断面流量等数据,数据集中部分参数说明见下表:
| FDT_TIME |
时间 |
| FSTR_BMCODE |
高架发布段代码 |
| SPEED |
平均速度 |
| FINT_LANEVOLUME |
平均车道流量 |
| FINT_SECTVOLUME |
平均断面流量 |
数据集以CSV格式存储,截图如下:
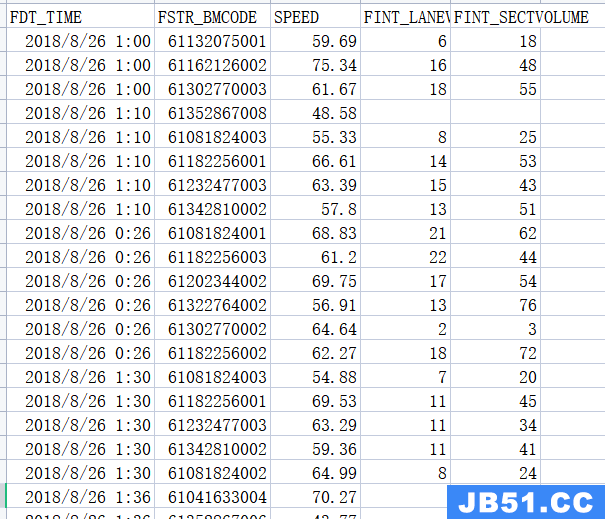
-
上海共享单车数据
数据集中包含上海2018年8月26日至2018年9月8日的共享单车数据,包括单车编号、时间、锁状态、经度、纬度信息,数据集中参数说明见下表:
| BIKE_ID |
单车代码 |
| DATA_TIME |
时间,格式:年/月/日 时:分:秒 |
| LOCK_STATUS |
锁状态,0:开锁;1:关锁 |
| LONGITUDE |
经度 |
| LATITUDE |
纬度 |
数据集以CSV格式存储,截图如下:

-
上海交叉口线圈数据
记录了2018年8月26日至2018年9月8日,上海市地面道路SCATS交叉口各线圈周期时长、流量、饱和度、小时流量等相位历史数据信息,包括四个交叉口(470:延安西路-水城南路交叉口;471:延安西路-虹许路交叉口;472:延安西路-虹梅路交叉口;473:延安西路-剑河路-虹中路交叉口),每个交叉口含相位、相位开始时间、检测器ID、相位号、相位时长、流量、饱和度、折算流量、空闲时间、统计的检测器小时最大流量、当车流处于饱和流量时,每辆车通过检测器所需的平均时间、绿灯时长等信息。数据集中参数说明见下表:
| FDT_STARTTIME |
相位开始时间,格式:年/月/日 时:分:秒 |
| FSTR_DETECTORID |
检测器ID |
| FSTR_PHASIC |
相位号,采用一位英文字母表示 |
| FINT_PHASICLENGTH |
相位时长,单位:秒 |
| FINT_FLOW |
流量,单位:辆 |
| FFLT_SATURATION |
饱和度 |
| FINT_CONVERTFLOW |
折算流量,基于流量折算的标准车流量,单位:秒 |
| FINT_FREETIME |
空闲时间,单位:秒 |
| FINT_MAXFLOW |
统计的检测器小时最大流量,单位:辆/小时 |
| FINT_KP |
当车流处于饱和流量时,每辆车通过检测器所需的平均时间 |
| FINT_GREENTIME |
绿灯时长,单位:秒 |
数据集以CSV格式存储,截图如下:
以上是国内外部分交通数据集的基本介绍及参数说明,若有相关疑问及需求,欢迎留言、私信探讨。
原文地址:https://blog.csdn.net/Mrcomj/article/details/129669166
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。