
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站:https://www.captainai.net/dongkelun
前言
参与Apache Hudi开源有一年多的时间了,马上1024了,虽然距离成为Apache Hudi Commiter还有很遥远的距离,但还是想跟大家分享一下自己的开源经验,讲一下自己如何从开源小白成为Apache Hudi Contributor的。
PR
如何提交PR,可以参考我转载的这篇:一行代码成为Apache Contributor,这篇文章讲述了怎么提交PR,怎么邮箱订阅以及Jira准备等,详细过程我就不再阐述了,这篇文章主要想分享自己的经验。
Contributor
我自己之前连Contributor是啥都不知道,其实只要你向社区提交过代码也就是在GitHub上提过PR并且你的代码被merge了,你就是Contributor了,再往上还有Commiter、PMC等,这些我之前都没听过,一般来说你贡献的代码比较多,比如贡献过一个比较大的模块如Hudi Spark SQL,或者你可以负责一个模块,经过PMC的提名、投票等,通过的话就会成为Commiter了,根据我的经验,当贡献代码行数过万时成为Commiter就比较有希望了,当然不是绝对的。Commiter有专门的Apache 账户,有权限merge代码,至于PMC,大家可以自己去了解。
上面提到当我们提交的代码mere后,我们就是Contributor了,那么怎么确认一下呢。一种方法是在PR的界面上,可以看到Contributor的标识

还可以在Contributor贡献列表中看到自己的名字:https://github.com/apache/hudi/graphs/contributors
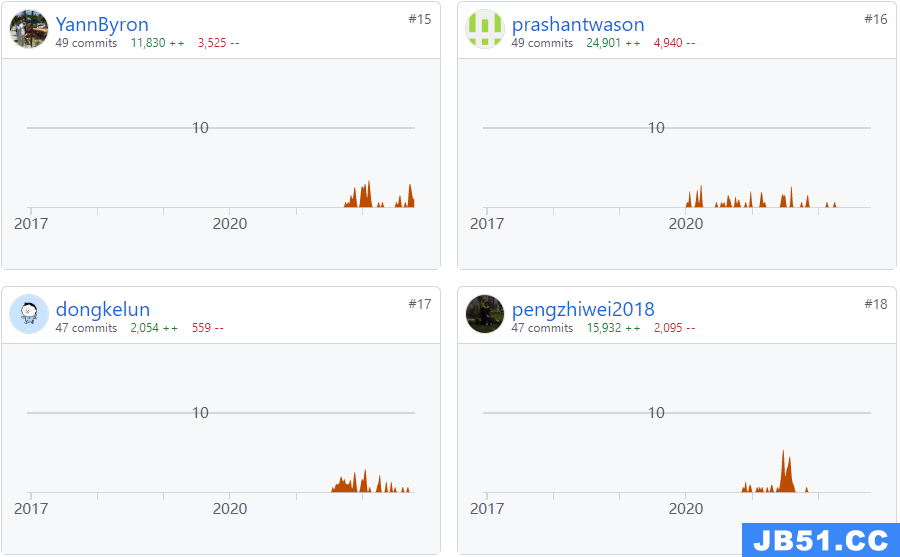
当然这里只显示前100名,对于Contributor比较多的项目,我们只提交了一个PR,在这个页面就看不到自己的名字了,就很遗憾,我们可以拉取master最新代码,通过git log等命令模拟这个列表看到自己的名字,当然也可以在git 提交历史中看到自己的PR。而对于比较早期的项目,比如前几年Hudi的贡献者还不到100个,就可以直接看到自己的名字了,再比如现在的Apache Kyuubi项目https://github.com/apache/incubator-kyuubi/graphs/contributors,我只提交了一个PR,就可以看到自己的名字了。

对于第一次参与开源贡献PR的,能在贡献列表中看到自己的名字,还是非常开心的,反正我当时特别开心。
PR规范
对于修改单词拼写错误的也就是示例中的fix typo,我们是不需要在jira中创建issue的,标题就和示例中一样,前面加个[MINOR]即可,而对于修改代码逻辑的比如bug修复、添加新的特性支持,就要在jira里(https://issues.apache.org/jira/projects/HUDI/summary)先建一个issue,然后再在PR标题的前面加上[HUDI-对应的issueId],比如我的第二个PR:https://github.com/apache/hudi/pull/3415,标题为[HUDI-2279]Support column name matching for insert * and update set *,对应的jira为https://issues.apache.org/jira/browse/HUDI-2279。

新建issue时,如下图
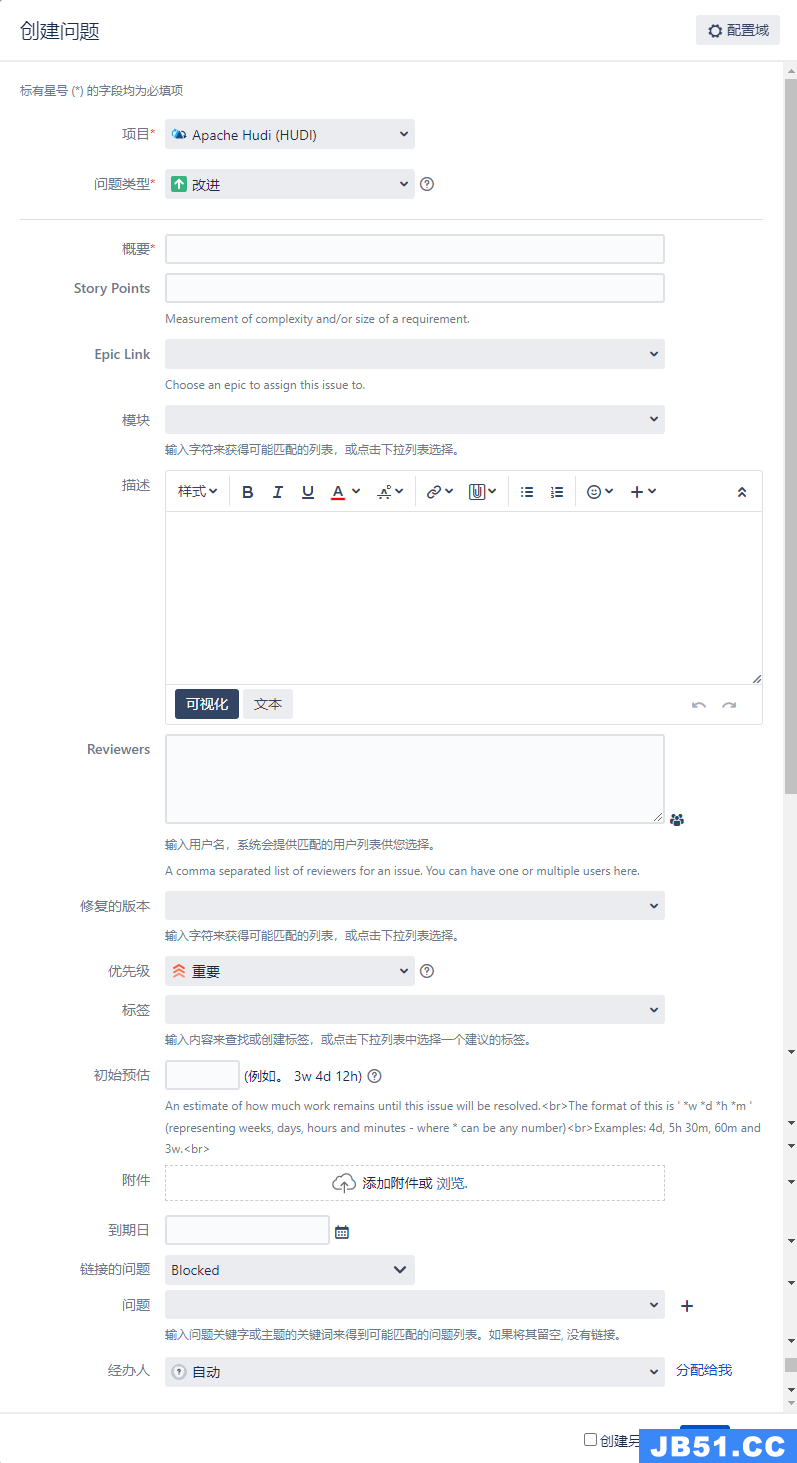
我们要填的有:问题类型、概要、模块、描述,问题类型有改进、故障、新功能等,概要就是标题,描述写具体我们要干啥,可以贴代码、异常信息等,也可以先建好之后再写描述,最后选一下分配给我,意思是我们自己认领这个issue,我们会自己提PR解决,当然也可以认领别人建的没有分配的issue。
对于PR的规范除了标题外,如果我们修改的逻辑比较复杂,我们需要写一下我们大概修改了什么,修改的逻辑是啥,当然这里也可以填写问题复现的过程,支持Markdown语法。
对于其他的Apache 项目,比如Spark,除了JIRA ID外还需要填写模块名称比如 [SPARK-32672][SQL],而有的项目JIRA不是必须的,比如Apache Kyuubi,至少我提交的一个PR是不需要的:https://github.com/apache/incubator-kyuubi/pull/3604
另外PR中的描述和交流都用英语,对于英语不好的,可以通过翻译辅助,开始可能比较困难,有经验了,就不会那么难了 。
代码规范
除了PR规范外,代码格式也是有规范的,每个项目的代码的规范也不太一样,一般的代码格式有空格、tab检查等,还有的import也会检查,Hudi Java代码的import会检查有没有导入.*的,比如java.util.*是不允许的,所以大家修改代码的时候需要注意规范,这样可以提高效率,否则PR的检查不会通过。除了代码格式外,我们还需要添加测试用例来验证我们修改的逻辑,关于怎么写测试用例,我们可以参考源码里其他的测试用例是怎么写的。
PR流程
我们提交了PR后,首先是需要其他的大佬们也就是Commiter或PMC review代码,如果修改的代码逻辑比较简单,且问题比较明显,可能很快就会有人review并且没问题的话就会merge到master了,如果逻辑复杂或者问题不明显或者有争议的可能会比较慢,我们需要慢慢等待,如果比较着急的话,可以主动@一下相关的Commiter或PMC帮忙review。

review的过程中,大佬们对于有疑问的地方,会提出问题让我们解答,对于代码逻辑或者代码规范不合适地方需要我们修改代码再次提交,这个过程可能会重复多次。当修改的没有问题的时候,大佬会先approved these changes

证明他觉得没问题了,可能会立即merge也可能会等其他的大佬再看看,再merge。
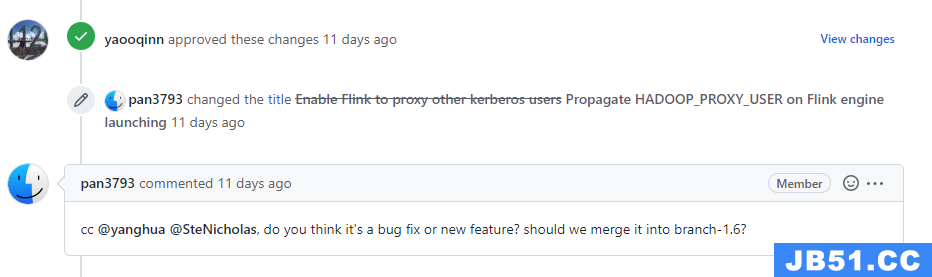
cc的意思是看看的意思,应该是see see的简写吧。
approved前后或者merge前后可能会留言LGTM,它是 look good to me的简写,意思是对我来说看起来不错,这可能对于第一次提交PR的人有点陌生,看到这句话我们可以不用回复。而像这样的简写还有很多,慢慢地我们就能知道它们是什么意思了。

Git经验
对于没有review的代码,如果我们需要修改代码重新提交,可以利用git commit --amend命令然后强制提交代码,这样看起来commit会整洁一些,另外可能项目环境不稳定,本来我们提交的代码没有问题,但是测试用例因为环境问题跑失败了,我们需要重新提交代码触发,这样也需要这个命令,这个命令可以不用修改代码,直接强制提交代码。
git commit --amend
## -f 强制提交
git push origin-dkl HUDI-2279 -f
而对于review后,reviewer需要我们修改相关的代码,我们修改后,最好是不用amend,需要提交一个新的commit,并且描述中填写我们修改了什么内容,方便reviewer查看比较我们修改了哪些内容。(这一点我也是最近才知道~)

另外GitHub国内网络不稳定,并且有的公司网连接不上GitHub、Jira等,我们可以用自己手机的热点,这样就可以连接上了。
其他Git相关的问题,可以自己网上搜索解决方案。比如如何解决冲突问题,虽然自己当时提PR时没有冲突,但是随着别人PR合并,可能就有冲突了,这个时候需要我们自己解决冲突。

代码
代码我们一定要基于master最新版,这样不会有冲突,也防止我们要改的内容已经被别人提交过了。
我们要首先学会自己打包源码,比如Hudi
## 默认版本
mvn clean package -DskipTests
## 指定Spark版本
mvn clean package -DskipTests -Dspark3.1 -Dscala-2.12
其他相关命令可以在源码中的README中查看,这样我们可以利用自己打的包验证我们修改的代码有没有问题,因为很多代码在本地是无法验证的,比如同步Hive相关的。
如何找到贡献点
对于刚入门的小白来说,比如当时的我,由于工作原因,写代码并不多,主要打杂(作者之前干过Python机器学习、JSP前后端、VUE纯前端等)或者写sql(大数据方向写sql还是比较多的),那么该怎么发现比较简单的自己能够贡献的点呢?分享自己的几点经验
- 1、如果工作中用到了Hudi,那么大概率会发现问题,比如一些异常或者哪里不支持等,这样我们就可以根据异常相关信息,带着问题去看源码,看看是不是bug,如果是自己能看懂,并且比较简单就可以修复的话,我们就可以提交PR了,如果问题比较难解决,也没问题,至少我们对于源码多理解了一点,我们再看其他的问题,等我们有能力了再来解决。
- 2、在自己学习时,比如根据官网文档写demo时,发现一些地方不支持或者有问题,可以debug跟一下代码,看看自己是否可以贡献PR。
- 3、学习时对于自己感兴趣的点,比如预合并或者Clean是如何实现的,可能在学习的时候发现代码里的逻辑有问题或者有优化的地方,就可以提交PR了。其实在我们前面总结的几篇文章里可以发现,我在总结时就发现了问题,顺便提了PR,比如:Hudi DeltaStreamer使用总结
- 4、没事就看看别人提交的自己感兴趣的PR,可以给自己一些灵感,或者发现别人提交的PR有bug,并且已经merge了,这样我们不仅可以学习别人提交的代码,也可以增加自己的贡献数。
- 5、没事就拉一下最新代码,比如新版本发布了,我们测试一下新版本有没有bug,因为我们平时自己用的版本,可能很难发现问题了,但是新版的代码因为加了很多新功能等,就会暴露出一些问题。
- 6、有时间可以在GitHub上看一下别人提交的issue,地址:https://github.com/apache/hudi/issues,如果有自己擅长的,也可以尝试提PR解决一下。
- 7、当自己贡献代码比较多了,对代码理解比较深入了,就可以增加一些新的特性了。
- 8、对于一些大厂来说,本身就基于源码开发了很多特性以支持自己的业务,他们会定期贡献到开源社区。对于很多小厂或者项目上用Hudi用的不多的来说,可能就比较难了,但是也可以作为一种思路,可以试着修改源码适应自己的需求,这样在自己的项目中验证没问题后,就可以贡献到社区了。这也就是为啥很多大佬一个PR就可以上万行代码,很快成为commiter的原因,当然他们本身就很强,可能是多个Apache 项目的Commiter。
开源的好处
首先开源是没有钱赚的~
- 1、可以提升自己的代码水平,大佬的review也可以让自己学到很多。
- 2、可以加深自己所用技术的理解,其实很多功能配置参数或者功能特性,网上包括官网资料很少或者没有(更新延迟),当我们熟悉了源码后,我们可以在源码里找到答案,直接解决我们的问题。
- 3、可以给自己的简历加分,我看到很多招聘需求里提到,如果常用的技术组件有贡献代码的话,会加分或者优先考虑,还有大厂直接招这种开源岗位的。
- 4、会认识很多大厂的大佬,认识很多优秀的人,如果想换工作的话,可以找他们内推。
- 5、如果贡献比较多的话,会有大厂的负责人主动加你好友,问你有意向去他们那吗,比如我就被某大厂数据湖负责人加过好友问过面试意向。当然这并不代表我的水平已经能进大厂了,但起码多了一个机会。另外如果我们成为Commiter(主流开源技术)的话,我们进大厂就比较稳妥了,当然其实能够成为Commiter的,已经妥妥的大佬水平了。
相关阅读
- Apache Hudi 入门学习总结
- Hudi Spark SQL总结
- Hudi preCombinedField 总结
- Hudi Spark SQL源码学习总结-Create Table
- Hudi Spark源码学习总结-df.write.format(“hudi”).save
- Hudi Spark源码学习总结-spark.read.format(“hudi”).load
- Hudi Clean 清理文件实现分析
- Hudi Clean Policy 清理策略实现分析
- Hudi源码|bootstrap源码分析总结(写Hudi)
原文地址:https://kelun.blog.csdn.net
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。