
订单统计分析案例

一、案例介绍
有以下数据集:
订单ID |
订单状态 |
支付金额 |
支付方式ID |
用户ID |
操作时间 |
商品分类 |
|---|---|---|---|---|---|---|
id |
status |
pay_money |
payway |
userid |
operation_date |
category |
1 |
已提交 |
4070 |
1 |
4944191 |
2020-04-25 12:09:16 |
手机; |
2 |
已完成 |
4350 |
1 |
1625615 |
2020-04-25 12:09:37 |
家用电器;;电脑; |
3 |
已提交 |
6370 |
3 |
3919700 |
2020-04-25 12:09:39 |
男装;男鞋; |
4 |
已付款 |
6370 |
3 |
3919700 |
2020-04-25 12:09:44 |
男装;男鞋; |
我们需要基于按数据,使用Elasticsearch中的聚合统计功能,实现一些指标统计。
二、创建索引
PUT /order_idx/
{
"mappings": {
"properties": {
"id": {
"type": "keyword",
"store": true
},
"status": {
"type": "keyword",
"store": true
},
"pay_money": {
"type": "double",
"store": true
},
"payway": {
"type": "byte",
"store": true
},
"userid": {
"type": "keyword",
"store": true
},
"operation_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"store": true
},
"category": {
"type": "keyword",
"store": true
}
}
}
}三、导入测试数据
- 上传资料中的order_data.json数据文件到Linux
- 使用bulk进行批量导入命令
curl -H "Content-Type: application/json" -XPOST "node1:9200/order_idx/_bulk?pretty&refresh" --data-binary "@order_data.json"四、统计不同支付方式的的订单数量
1、使用JSON DSL的方式来实现
这种方式就是用Elasticsearch原生支持的基于JSON的DSL方式来实现聚合统计。
GET /order_idx/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "payway"
}
}
}
}统计结果:
"aggregations": {
"group_by_state": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 2,
"doc_count": 1496
},
{
"key": 1,
"doc_count": 1438
},
{
"key": 3,
"doc_count": 1183
},
{
"key": 0,
"doc_count": 883
}
]
}
}这种方式分析起来比较麻烦,如果将来我们都是写这种方式来分析数据,简直是无法忍受。所以,Elasticsearch想要进军OLAP领域,是一定要支持SQL,能够使用SQL方式来进行统计和分析的
2、基于Elasticsearch SQL方式实现
GET /_sql?format=txt
{
"query": "select payway, count(*) as order_cnt from order_idx group by payway"
}这种方式要更加直观、简洁
五、基于JDBC方式统计不同方式的订单数量
Elasticsearch中还提供了基于JDBC的方式来访问数据。我们可以像操作MySQL一样操作Elasticsearch。使用步骤如下:
1、在pom.xml中添加以下镜像仓库
<repositories>
<repository>
<id>elastic.co</id>
<url>https://artifacts.elastic.co/maven</url>
</repository>
</repositories>2、导入Elasticsearch JDBC驱动Maven依赖
<dependency>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>x-pack-sql-jdbc</artifactId>
<version>7.6.1</version>
</dependency>3、驱动
org.elasticsearch.xpack.sql.jdbc.EsDriver
4、JDBC URL
jdbc:es:// http:// host:port
5、开启X-pack高阶功能试用,如果不开启试用,会报如下错误
current license is non-compliant for [jdbc]在node1节点上执行:
curl http://node1:9200/_license/start_trial?acknowledge=true -X POST
{"acknowledged":true,"trial_was_started":true,"type":"trial"}试用期为30天
参考代码:
/**
* 基于JDBC访问Elasticsearch
*/
public class ElasticJdbc {
public static void main(String[] args) throws Exception {
Class.forName("org.elasticsearch.xpack.sql.jdbc.EsDriver");
Connection connection = DriverManager.getConnection("jdbc:es://http://node1:9200");
PreparedStatement ps = connection.prepareStatement("select payway, count(*) as order_cnt from order_idx group by payway");
ResultSet resultSet = ps.executeQuery();
while(resultSet.next()) {
int payway = resultSet.getInt("payway");
int order_cnt = resultSet.getInt("order_cnt");
System.out.println("支付方式: " + payway + " 订单数量: " + order_cnt);
}
resultSet.close();
ps.close();
connection.close();
}
}注意:如果在IDEA中无法下载依赖,请参考以下操作:
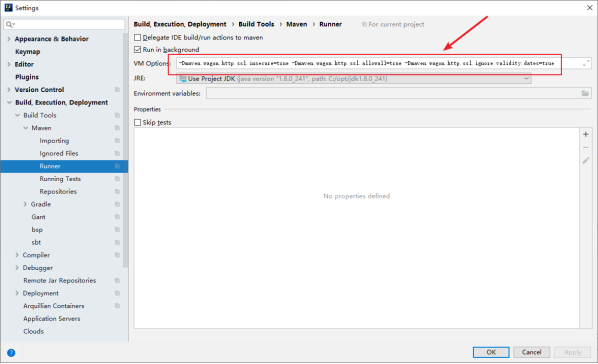
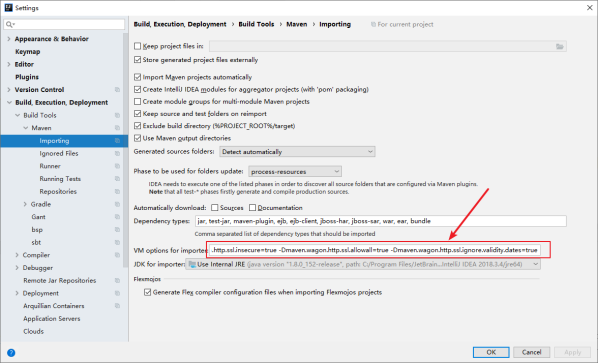
在Idea的File -->settings中,设置Maven的importing和Runner参数,忽略证书检查即可。(Eclipse下解决原理类似,设置maven运行时参数),并尝试手动执行Maven compile执行编译。
具体参数:-Dmaven.multiModuleProjectDirectory=$MAVEN_HOME -Dmaven.wagon.http.ssl.insecure=true -Dmaven.wagon.http.ssl.allowall=true -Dmaven.wagon.http.ssl.ignore.validity.dates=true
六、统计不同支付方式订单数,并按照订单数量倒序排序
GET /_sql?format=txt
{
"query": "select payway, count(*) as order_cnt from order_idx group by payway order by order_cnt desc"七、只统计「已付款」状态的不同支付方式的订单数量
GET /_sql?format=txt
{
"query": "select payway, count(*) as order_cnt from order_idx where status = '已付款' group by payway order by order_cnt desc"
}八、统计不同状态的订单总额、不同支付方式最高、最低订单金额
统计不同状态的订单总额、不同支付方式最高、最低订单金额
GET /_sql?format=txt
{
"query": "select userid, count(1) as cnt, sum(pay_money) as total_money from order_idx group by userid"
}九、Elasticsearch SQL目前的一些限制
目前Elasticsearch SQL还存在一些限制。例如:不支持JOIN、不支持较复杂的子查询。所以,有一些相对复杂一些的功能,还得借助于DSL方式来实现。
十、常见问题处理
1、elasticsearch.keystore AccessDeniedException
Exception in thread "main" org.elasticsearch.bootstrap.BootstrapException: java.nio.file.AccessDeniedException: /export/server/es/elasticsearch-7.6.1/config/elasticsearch.keystore
Likely root cause: java.nio.file.AccessDeniedException: /export/server/es/elasticsearch-7.6.1/config/elasticsearch.keystore
at java.base/sun.nio.fs.UnixException.translateToIOException(UnixException.java:90)
at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:111)
at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:116)
at java.base/sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:219)
at java.base/java.nio.file.Files.newByteChannel(Files.java:374)
at java.base/java.nio.file.Files.newByteChannel(Files.java:425)
at org.apache.lucene.store.SimpleFSDirectory.openInput(SimpleFSDirectory.java:77)
at org.elasticsearch.common.settings.KeyStoreWrapper.load(KeyStoreWrapper.java:219)
at org.elasticsearch.bootstrap.Bootstrap.loadSecureSettings(Bootstrap.java:234)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:305)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:170)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:161)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:125)
at org.elasticsearch.cli.Command.main(Command.java:90)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:126)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:92)解决方案:
将/export/server/es/elasticsearch-7.6.1/config/elasticsearch.keystore owner设置为lanson
chown lanson /export/server/es/elasticsearch-7.6.1/config/elasticsearch.keystore原文地址:https://cloud.tencent.com/developer/article/1915206
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。