
Airflow单机搭建
Airflow是基于Python的,就是Python中的一个包。安装要求Python3.6版本之上,Metadata DataBase支持PostgreSQL9.6+,MySQL5.7+,SQLLite3.15.0+。
一、安装Anconda及python3.7
1、官网下载Anconda ,选择linux版本,并安装
下载官网地址:https://www.anaconda.com/products/individual#macos

2、将下载好的anconda安装包上传至mynode4节点,进行安装
sh Anaconda3-2020.02-Linux-x86_64.sh 【一路回车即可】
Do you accept the license terms? [yes|no]
Yes【继续回车】
... ...
Anaconda3 will now be installed into this location:
/root/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/root/anaconda3] >>> 【回车即可,安装到/root/anaconda3路径下】
... ...
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>>yes【输入yes,回车即可】
... ...
【安装完成】3、配置Anconda的环境变量
在 /etc/profile中加入以下语句:
export PATH=$PATH:/root/anaconda3/bin
#使环境变量生效
source /etc/profile4、安装python3.7 python环境
conda create -n python37 python=3.75、激活使用python37 python环境
conda activate python37【激活使用python37环境,需要先执行下source activate】相关命令如下:
source activate 【初始化conda,必须执行,执行之后可以使用conda命令激活环境】
conda deactivate 【退出当前base环境】
conda activate python37【激活使用python37环境】
conda deactivate 【退出当前使用python37环境】
conda remove -n python37 --all 【删除python37环境】二、单机安装Airflow
单节点部署airflow时,所有airflow 进程都运行在一台机器上,架构图如下:
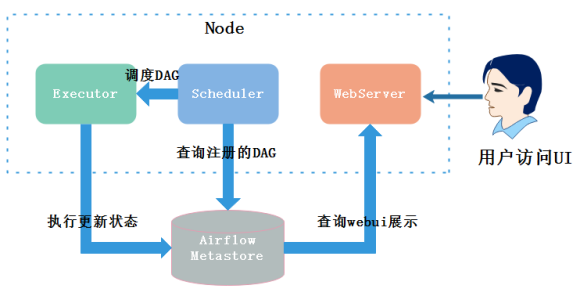
1、安装Airflow必须需要的系统依赖
Airflow正常使用必须需要一些系统依赖,在mynode4节点上安装以下依赖:
yum -y install mysql-devel gcc gcc-devel python-devel gcc-c++ cyrus-sasl cyrus-sasl-devel cyrus-sasl-lib 2、在MySQL中创建对应的库并设置参数
aiflow使用的Metadata database我们这里使用mysql,在node2节点的mysql中创建airflow使用的库及表信息。
CREATE DATABASE airflow CHARACTER SET utf8;
create user 'airflow'@'%' identified by '123456';
grant all privileges on airflow.* to 'airflow'@'%';
flush privileges;在mysql安装节点node2上修改”/etc/my.cnf”,在mysqld下添加如下内容:
[mysqld]
explicit_defaults_for_timestamp=1注意:以上配置explicit_defaults_for_timestamp 系统变量决定MySQL服务端对timestamp列中的默认值和NULL值的不同处理方法。此变量自MySQL 5.6.6 版本引入,默认值为0,在默认情况下,如果timestamp列没有显式的指明null属性,那么该列会被自动加上not null属性,如果往这个列中插入null值,会自动的设置该列的值为current timestamp值。当这个值被设置为1时,如果timestamp列没有显式的指定not null属性,那么默认的该列可以为null,此时向该列中插入null值时,会直接记录null,而不是current timestamp,如果指定not null 就会报错。
在Airflow中需要对应mysql这个参数设置为1。以上修改完成“my.cnf”值后,重启Mysql即可,重启之后,可以查询对应的参数是否生效:
#重启mysql
[root@node2 ~]# service mysqld restart
#重新登录mysql查询
mysql> show variables like 'explicit_defaults_for_timestamp';
3、安装Airflo
在node4上切换python37环境,安装airflow,指定版本为2.1.3
(python37) [root@node4 ~]# conda activate python37
(python37) [root@node4 ~]# pip install apache-airflow==2.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple默认Airflow安装在$ANCONDA_HOME/envs/python37/lib/python3.7/site-packages/airflow目录下。Airflow文件存储目录默认在/root/airflow目录下,但是这个目录需要执行下“airflow version”后自动创建,查看安装Airflow版本信息:
(python37) [root@node4 ~]# airflow version
2.1.3注意:如果不想使用默认的“/root/airflow”目录当做文件存储目录,也可以在安装airflow之前设置环境变量:
(python37) [root@node4 ~]# vim /etc/profile
export AIRFLOW_HOME=/software/airflow
#使配置的环境变量生效
source /etc/profile这样安装完成的airflow后,查看对应的版本会将“AIRFLOW_HOME”配置的目录当做airflow的文件存储目录。
4、配置Airflow使用的数据库为MySQL
打开配置的airflow文件存储目录,默认在$AIRFLOW_HOME目录“/root/airflow”中,会有“airflow.cfg”配置文件,修改配置如下:
[core]
dags_folder = /root/airflow/dags
#修改时区
default_timezone = Asia/Shanghai
# 配置数据库
sql_alchemy_conn=mysql+mysqldb://airflow:123456@node2:3306/airflow?use_unicode=true&charset=utf8
[webserver]
#设置时区
default_ui_timezone = Asia/Shanghai
#设置DAG显示方式
# Default DAG view. Valid values are: ``tree``, ``graph``, ``duration``, ``gantt``, ``landing_times``
dag_default_view = graph
[scheduler]
#设置默认发现新任务周期,默认是5分钟
# How often (in seconds) to scan the DAGs directory for new files. Default to 5 minutes.
dag_dir_list_interval = 305、安装需要的python依赖包
初始化Airflow数据库时需要使用到连接mysql的包,执行如下命令来安装mysql对应的python包。
(python37) [root@node4 ~]# pip install mysqlclient -i https://pypi.tuna.tsinghua.edu.cn/simple6、初始化Airflow 数据库
(python37) [root@node4 airflow]# airflow db init初始化之后在MySQL airflow库下会生成对应的表。
7、创建管理员用户信息
在node4节点上执行如下命令,创建操作Airflow的用户信息:
airflow users create \
--username airflow \
--firstname airflow \
--lastname airflow \
--role Admin \
--email xx@qq.com执行完成之后,设置密码为“123456”并确认,完成Airflow管理员信息创建。
三、启动Airflow
1、启动webserver
#前台方式启动webserver
(python37) [root@node4 airflow]# airflow webserver --port 8080
#以守护进程方式运行webserver,端口默认8080。 ps aux|grep webserver查看后台进程
airflow webserver --port 8080 -D2、启动scheduler
新开窗口,切换python37环境,启动Schduler:
#前台方式启动scheduler
(python37) [root@node4 ~]# airflow scheduler
#以守护进程方式运行Scheduler,ps aux|grep scheduler 查看后台进程
airflow scheduler -D3、访问Airflow webui
浏览器访问:http://node4:8080

输入前面创建的用户名:airflow 密码:123456
原文地址:https://cloud.tencent.com/developer/article/1967229
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。