
前言
虚竹哥有个朋友小五,他在数据产品提供商的公司上班。小五的妹夫自己开了家软件工作室,会承接一些软件研发项目。妹夫问小五:有没有成熟的报表插件,可以集成到程序中,最好是开源的,方便根据业务进行适配调整。
主要是有这么几个痛点:
- 简单的报表很多工具可以实现,但复杂的报表就做不到
报表需求很常见,之前做复杂的报表,很多要自行开发,而且工作量也大,开发上也有难度
- 报表开发的难题,并不全在制表上,有些是在数据准备上
应用中的报表,有 80% 的数据来源和计算都比较简单,很多一个简单的 SQL 语句就搞定了,但还有 20% 的情况中,数据准备工作就没有那么好做了,一些过程式的多步骤复杂计算,常常要写很长的多层嵌套的 SQL 或者存储过程才能搞定,如果数据来源再复杂一些,要对各类数据源混算,一些非关系数据库或者文本数据源都不支持 SQL 了,那还得用 JAVA 等语言来写,SQL 10 几行能写完的,JAVA 恨不得写出几百行来,编码难度和效率就更糟糕了
- 不开源,适配很难满足客户的要求
功能和页面需要跟着需求做适配,否则界面风格不匹配,功能不顺手,用起来也很别扭。客户是上帝。哈哈哈
大家一起跟虚竹哥来看看小五是怎么分析和建议的。
分析痛点
简单的报表可以做
格式简单的分组交叉报表,是可以做的。有些能力稍强的工具,对于多层分组交叉,同比环比之类的也可以做
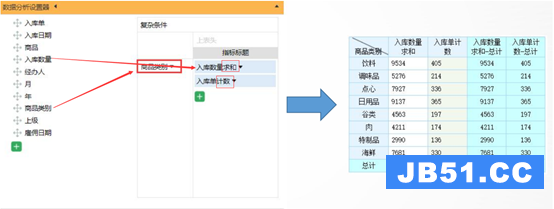
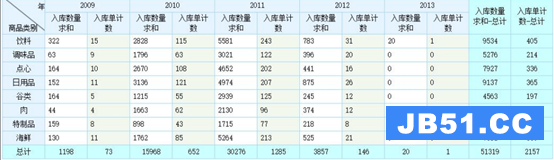
多层分组交叉
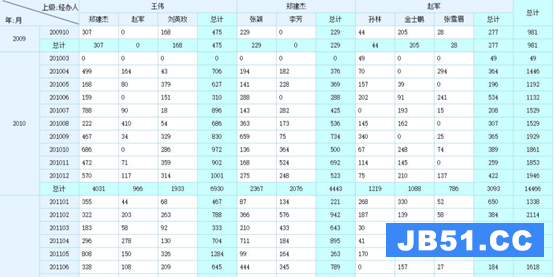
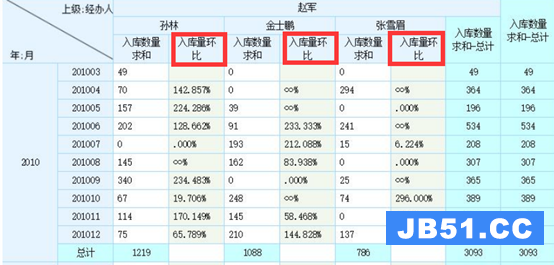
环比
以上这些样式和计算都比较简单的报表,业务用户都可以使用自助报表和BI,通过拖拽方式制作出来,虽然这类简单的报表在大部分的应用中都占比较少,但能由用户自己去做,不仅能给用户一定程度上的自由,也能稍微减轻开发商和技术人员的的一些负担,也是具有一定的业务意义的。
# 复杂的报表做不了
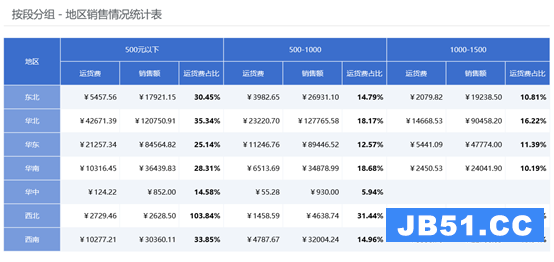
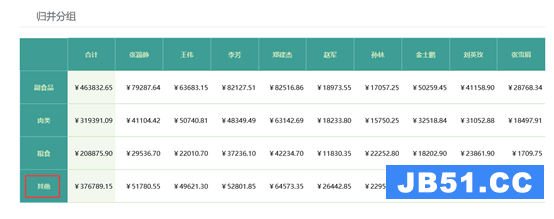
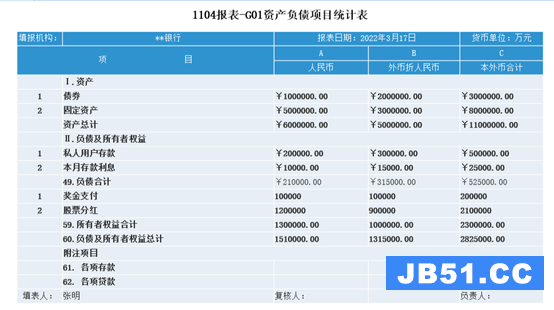
格式和计算稍微复杂一些以后,自助报表和BI就无能为力了,用户自己做报表就指望不上了,
这类复杂报表的制作,在应用中占比又不在少数,而且总是会有新需求,要么做新的,要么改旧的,报表任务用没完没了来形容也不为过,这个重担就只能开发商或技术人员自己来背了,就得选一个高效的报表工具来做这些复杂报表了
但是很多时候,我们发现即使使用了大牌报表工具,也不见得就能把这个重担减轻多少。因为复杂报表的复杂,不仅是报表呈现的复杂,而是数据准备的阶段也很复杂,甚至可以说更复杂,比如做表前要成百上千行的SQL和存储过程来准备数据,而数据准备又不属于报表能力范畴,报表工具也解决不了,这时候要想真正的解决复杂报表这个重担,就得再找一个解决数据准备的工具了。
关联分析做的不好
自助报表和BI做分析时候,都会遇到多表和多库关联查询分析的情况,目前市面上的工具,处理这类问题,基本上都处理的不好,要么是给用户做宽表凑合着用,一遇到新分析需求就得去改CUBE或者重新做一个,结果还是要求助于技术人员。要么就是把工程师都难以捋清楚的表间关系暴露给业务用户,让用户自己去关联,美其名曰“自助关联”,连技术人员做起来都困难的事情让业务人员去做,太不现实了
关联查询分析做不好,那就相当于分析只能基于单表,这就会导致原本应用面就窄的自助报表和BI使用面更窄了,只有把这个问题解决好,才能扩大自助报表和BI的应用范围,使得分析更有意义和价值。
开源和集成性不好
需要自助报表和BI功能的用户本身大多都有自己的业务系统,如果用到的BI只能独立部署、独立管理,无疑会增大工作量和后期维护成本,也会存在风险和隐患,这就需要BI是可以被集成的
集成后,功能和页面还需要能随需而动才可以,否则风格不匹配,功能不顺手,用起来也很别扭,所以BI最好还得是开源的。
但目前商用的自助报表和BI,基本没有开源的,也都是很难被集成的,这就导致了不管BI能解决多少事情,用起来都很不舒服的情况。
建议方案
1、 针对 “简单的报表很多工具可以实现,但复杂的报表就做不到”问题
使用了一些大牌报表工具,也不见得就能把这个重担减轻多少。因为复杂报表的复杂,不仅是报表呈现的复杂,而是数据准备的阶段也很复杂。
可以看看专业报表厂商是怎么解决这个难题的:参考于:
http://c.raqsoft.com.cn/article/1643181441924
从文章中把重点提炼一下:
- 简单,补上数据准备环节的工具就可以了:使用集算器
集算器做数据准备写的快算的快:集算器,流行的开源免费数据计算工具。
一:它能对接各类数据源;
二:能轻松写出 SQL 和 JAVA 写起来困难的计算过程,而且还算的快,让数据准备工作变的轻松又高效
- 完全工具化应对没完没了
报表制作的工具化; 数据准备的工具化;
2、 针对“不开源,适配很难满足客户的要求”问题
目前国内主流产品中只有润乾的 BI 是开源的,润乾是专业做报表的,报表在行业里排在前面,开源的 BI 功能也很完善
国外的开源 BI 软件也很多,功能也不比国内的商用的差,也是很好的选择,只是国产化要求高的项目用不了,另外界面不是中文的,改造起来相当费劲,BI和自助报表本来就是个强界面的任务,整体改造界面几乎相当于重做。
润乾报表为了让小伙伴方便快捷使用,特意组建了技术交流群,有兴趣的加小助手(VX号:RUNQIAN_RAQSOFT)。
结语
自助报表和BI,虽然最近几年热度比较高,但经过众多用户实际的使用和验证后,人们对它的认识也开始逐渐变的更科学和客观,它有进步的业务意义所在,也有切实存在的短板,它自由灵活及时简单,但却难以驾驭复杂的局面,它需要能解决数据准备难题的高效报表工具来帮它解决复杂报表的难题,需要能解决关联分析的引擎来支撑它做更多更广的分析,还需要把自己变的开源可集成才能让自己和已有系统配合的更默契
它前进的路上,需要有很多伙伴一路同行才能让它的价值更好的得到体现。
文章参考资料
粉丝福利
送两本《JAVA核心技术》最新版本:原书第12版 卷1 (附带有虚竹哥的推荐小册)



如何免费获得该书呢?
本文优质评论一条,且该评论点赞数是最高的和第二高的!
点赞数并列第一的,例如3条评论点赞数并列第一的,以评论的时间谁早,选前两名!
统计截止时间:2022/07/12 21:59:59
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。