

一,单路快排
1.测试用例:
1 #ifndef INC_06_QUICK_SORT_DEAL_WITH_NEARLY_ORDERED_ARRAY_SORTTESTHELPER_H 2 #define INC_06_QUICK_SORT_DEAL_WITH_NEARLY_ORDERED_ARRAY_SORTTESTHELPER_H 3 #include <iostream> 4 #include <algorithm> 5 #include <string> 6 #include <ctime> 7 #include <cassert> 8 using namespace std; 9 SortTestHelper { 10 // 生成有n个元素的随机数组,每个元素的随机范围为[rangeL,rangeR] 11 int *generaterandomArray(int n,int range_l,1)">int range_r) { 12 int *arr = new [n]; 13 srand(time(NULL)); 14 for (int i = 0; i < n; i++) 15 arr[i] = rand() % (range_r - range_l + 1) + range_l; 16 return arr; 17 } 18 生成一个近乎有序的数组 19 首先生成一个含有[0...n-1]的完全有序数组,之后随机交换swapTimes对数据 20 swapTimes定义了数组的无序程度 21 int *generateNearlyOrderedArray( swapTimes){ 22 23 for(0 ; i < n ; i ++ ) 24 arr[i] = i; 25 26 for( 0 ; i < swapTimes ; i ++ ){ 27 int posx = rand()%n; 28 int posy = rand()%29 swap( arr[posx],arr[posy] ); 30 } 31 32 33 拷贝整型数组a中的所有元素到一个新的数组,并返回新的数组 34 int *copyIntArray(int a[],1)"> n){ 35 36 copy(a,a+n,arr); 37 38 39 打印arr数组的所有内容 40 template<typename T> 41 void printArray(T arr[],1)"> n) { 42 43 cout << arr[i] << " "; 44 cout << endl; 45 46 47 48 判断arr数组是否有序 49 template<typename T> 50 bool isSorted(T arr[],1)">51 0; i < n - 1; i++52 if (arr[i] > arr[i + 1]) 53 return false54 true55 56 测试sort排序算法排序arr数组所得到结果的正确性和算法运行时间 57 template<typename T> 58 void testSort(const string &sortName,1)">void (*sort)(T[],1)">int),T arr[],1)">59 clock_t startTime = clock(); 60 sort(arr,n); 61 clock_t endTime =62 cout << sortName << " : " << double(endTime - startTime) / CLOCKS_PER_SEC << s"<<endl; 63 assert(isSorted(arr,n)); 64 65 66 }; 67 #endif
2.归并排序:
#ifndef INC_06_QUICK_SORT_DEAL_WITH_NEARLY_ORDERED_ARRAY_MERGESORT_H #define INC_06_QUICK_SORT_DEAL_WITH_NEARLY_ORDERED_ARRAY_MERGESORT_H 5 #include InsertionSort.h" 6 7 将arr[l...mid]和arr[mid+1...r]两部分进行归并 8 template<typename T> void __merge(T arr[],1)">int l,1)">int mid,1)"> r){ 10 T aux[r-l+]; T *aux = new T[r-l+1]; 12 int i = l ; i <= r; i ++13 aux[i-l] = arr[i]; 14 初始化,i指向左半部分的起始索引位置l;j指向右半部分起始索引位置mid+1 15 int i = l,j = mid+16 int k = l ; k <= r; k ++17 if( i > mid ){ 如果左半部分元素已经全部处理完毕 18 arr[k] = aux[j-l]; j ++19 20 else if( j > r ){ 如果右半部分元素已经全部处理完毕 21 arr[k] = aux[i-l]; i ++22 if( aux[i-l] < aux[j-l] ) { 左半部分所指元素 < 右半部分所指元素 24 arr[k] = aux[i-l]; i ++else{ 左半部分所指元素 >= 右半部分所指元素 27 arr[k] = aux[j-l]; j ++28 30 delete[] aux; 31 } 使用优化的归并排序算法,对arr[l...r]的范围进行排序 33 template<typename T> 34 void __mergeSort(T arr[],1)">35 对于小规模数组,使用插入排序 36 if( r - l <= 1537 insertionSort(arr,l,r); 38 39 40 int mid = (l+r)/241 __mergeSort(arr,mid); 42 __mergeSort(arr,mid+,1)">43 对于arr[mid] <= arr[mid+1]的情况,不进行merge 44 对于近乎有序的数组非常有效,但是对于一般情况,有一定的性能损失 45 if( arr[mid] > arr[mid+] ) 46 __merge(arr,mid,1)">48 template<typename T> 49 void mergeSort(T arr[],1)">50 __mergeSort( arr,0,n- ); 51 52 #endif
3.优化时要用的插入排序:
#ifndef INC_06_QUICK_SORT_DEAL_WITH_NEARLY_ORDERED_ARRAY_INSERTIONSORT_H #define INC_06_QUICK_SORT_DEAL_WITH_NEARLY_ORDERED_ARRAY_INSERTIONSORT_H 5 6 template<typename T> void insertionSort(T arr[],1)"> 8 1 ; i < n ; i ++ ) { 9 T e =10 j; 11 for (j = i; j > 0 && arr[j-1] > e; j--12 arr[j] = arr[j-13 arr[j] = e; 14 16 对arr[l...r]范围的数组进行插入排序 18 template<typename T> int i = l+1 ; i <= r ; i ++21 T e =for (j = i; j > l && arr[j-24 arr[j] = arr[j-25 arr[j] =26 27 #endif
4.单路快排实现:
1 #include <iostream> 2 #include <algorithm> 3 #include <ctime> 4 #include SortTestHelper.hMergeSort.h 6 #include 对arr[l...r]部分进行partition操作 返回p,使得arr[l...p-1] < arr[p] ; arr[p+1...r] > arr[p] 10 template <typename T> 11 int _partition(T arr[],1)"> 随机在arr[l...r]的范围中,选择一个数值作为标定点pivot 13 swap( arr[l],arr[rand()%(r-l+1)+l] ); 14 T v = arr[l]; int j = l; int i = l + if( arr[i] < v ){ 18 j ++ swap( arr[j],arr[i] ); 20 21 swap( arr[l],arr[j]); 22 23 24 对arr[l...r]部分进行快速排序 25 template <typename T> void _quickSort(T arr[],使用插入排序进行优化 28 30 32 int p = _partition(arr,1)">33 _quickSort(arr,p-34 _quickSort(arr,p+35 36 template <typename T> void quickSort(T arr[],1)"> srand(time(NULL)); 39 _quickSort(arr,1)">); 40 比较Merge Sort和Quick Sort两种排序算法的性能效率 42 main() { int n = 100000 测试1 一般性测试(随机数) 45 cout<<Test for random array,size = "<<n<<]46 int* arr1 = SortTestHelper::generaterandomArray(n,1)">047 int* arr2 = SortTestHelper::copyIntArray(arr1,1)">48 SortTestHelper::testSort(Merge Sort49 SortTestHelper::testSort(Quick Sortdelete[] arr1; 51 [] arr2; 52 cout<<53 测试2 测试近乎有序的数组 54 加入了随机选择标定点的步骤后,我们的快速排序可以轻松处理近乎有序的数组 55 但是对于近乎有序的数组,其效率比优化后的归并排序要低,但完全再容忍范围里 int swapTimes = 10057 cout<<Test for nearly ordered array,swap time = "<<swapTimes<<58 arr1 = SortTestHelper::generateNearlyOrderedArray(n,swapTimes); 59 arr2 =60 SortTestHelper::testSort(61 SortTestHelper::testSort(62 63 64 cout<<65 测试3 测试存在包含大量相同元素的数组 66 但此时,对于含有大量相同元素的数组,我们的快速排序算法再次退化成了O(n^2)级别的算法 67 cout<<68 arr1 = SortTestHelper::generaterandomArray(n,1)">1069 arr2 =70 SortTestHelper::testSort(71 SortTestHelper::testSort(72 73 74 return 75 }
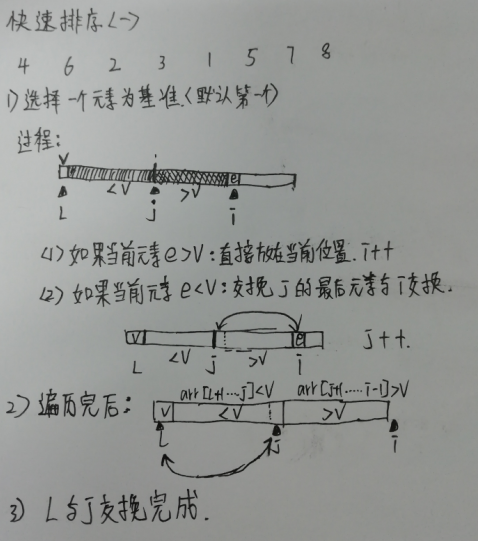
图解单路快排:
5.单路快排的测试结果:
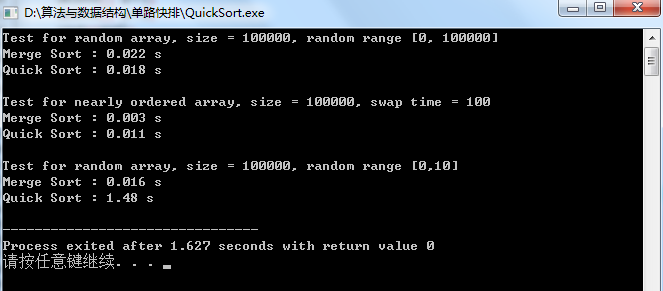
可见单路快排在随机测试和近乎有序的情况下效率是完全可以接受的,但是在存在大量重复的元素中表现不是太好,下面我们进行一步一步的优化:
二,双路快排:
只需改一下主函数:
1 #include <iostream> 2 #include <algorithm> 3 #include <ctime> 4 #include 5 #include 6 #include 7 8 9 10 template <typename T> 11 12 13 swap( arr[l],1)"> 14 T v = 15 16 17 18 j ++ 19 20 21 22 23 24 双路快速排序的partition 25 26 template <typename T> 27 int _partition2(T arr[],1)"> 28 29 swap( arr[l],1)"> 30 T v = 31 arr[l+1...i) <= v; arr(j...r] >= v 32 1,j = r; 33 while( 34 注意这里的边界,arr[i] < v,不能是arr[i] <= v 35 while( i <= r && arr[i] < v ) 36 i ++ 37 38 while( j >= l+1 && arr[j] > 39 j -- 40 if( i > j ) 41 break 42 swap( arr[i],arr[j] ); 43 i ++ 44 j -- 45 46 47 48 49 50 template <typename T> 51 52 53 54 55 56 57 调用双路快速排序的partition 58 _partition2(arr,1)"> 59 _quickSort(arr,1)"> 60 _quickSort(arr,1)"> 61 62 template <typename T> 63 64 65 _quickSort(arr,1)"> 66 67 比较Merge Sort和双路快速排序两种排序算法的性能效率 68 69 70 测试1 一般性测试 71 cout<< 72 73 74 SortTestHelper::testSort( 75 SortTestHelper::testSort( 76 77 78 cout<< 79 80 双路快速排序算法也可以轻松处理近乎有序的数组 81 82 cout<< 83 arr1 = 84 arr2 = 85 SortTestHelper::testSort( 86 SortTestHelper::testSort( 87 88 89 cout<< 90 91 使用双快速排序后,我们的快速排序算法可以轻松的处理包含大量元素的数组 92 cout<< 93 arr1 = SortTestHelper::generaterandomArray(n,1)"> 94 arr2 = 95 SortTestHelper::testSort( 96 SortTestHelper::testSort( 97 98 99 100 }
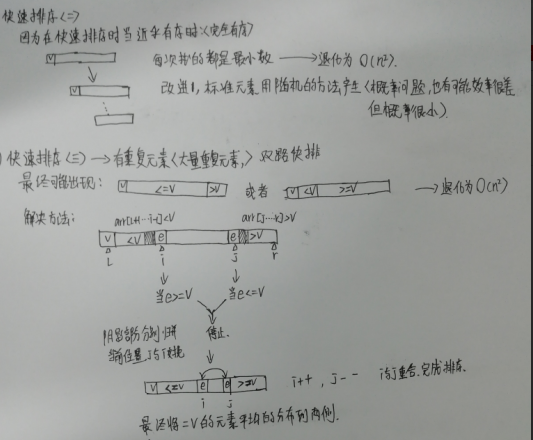
图解双路快排:
双路快排测试结果:
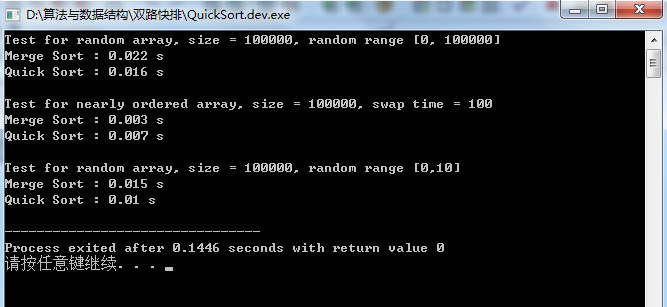
可见优化后的双路快排在大量重复元素的数组测试中速度提升了近乎200倍,接下来让我们在来看看最棒的三路快排:
三,三路快排:
1.我们将刚才的双路快排写到一个头文件中以便等下测试:
#ifndef INC_07_QUICK_SORT_THREE_WAYS_QUICKSORT_H
#define INC_07_QUICK_SORT_THREE_WAYS_QUICKSORT_H
#include <iostream>
#include <ctime>
#include <algorithm>
#include "InsertionSort.h"
using namespace std;
// 对arr[l...r]部分进行partition操作
// 返回p,使得arr[l...p-1] < arr[p] ; arr[p+1...r] > arr[p]
template <typename T>
int _partition(T arr[],int l,int r){
// 随机在arr[l...r]的范围中,选择一个数值作为标定点pivot
swap( arr[l],arr[rand()%(r-l+1)+l] );
T v = arr[l];
int j = l;
for( int i = l + 1 ; i <= r ; i ++ )
if( arr[i] < v ){
j ++;
swap( arr[j],arr[i] );
}
swap( arr[l],arr[j]);
return j;
}
// 双路快速排序的partition
// 返回p,使得arr[l...p-1] < arr[p] ; arr[p+1...r] > arr[p]
template <typename T>
int _partition2(T arr[],arr[rand()%(r-l+1)+l] );
T v = arr[l];
int i = l+1,j = r;
while( true ){
// 注意这里的边界,不能是arr[i] <= v
while( i <= r && arr[i] < v )
i ++;
// 注意这里的边界,不能是arr[j] >= v
while( j >= l+1 && arr[j] > v )
j --;
if( i > j )
break;
swap( arr[i],arr[j] );
i ++;
j --;
}
swap( arr[l],arr[j]);
return j;
}
// 对arr[l...r]部分进行快速排序
template <typename T>
void _quickSort(T arr[],int r){
// 对于小规模数组,使用插入排序进行优化
if( r - l <= 15 ){
insertionSort(arr,r);
return;
}
// 调用双路快速排序的partition
int p = _partition2(arr,r);
_quickSort(arr,p-1 );
_quickSort(arr,p+1,r);
}
template <typename T>
void quickSort(T arr[],int n){
srand(time(NULL));
_quickSort(arr,n-1);
}
#endif
2.三路快排实现:
7 #include QuickSort.h 递归的三路快速排序算法 void __quickSort3Ways(T arr[],1)">13 15 17 18 swap( arr[l],1)">l ] ); 19 T v =int lt = l; arr[l+1...lt] < v int gt = r + 1; arr[gt...r] > v 1; arr[lt+1...i) == v 23 while( i < gt ){ 24 25 swap( arr[i],arr[lt+]); 26 i ++27 lt ++29 if( arr[i] >30 swap( arr[i],arr[gt-31 gt --33 else{ arr[i] == v 34 i ++36 38 __quickSort3Ways(arr,lt- __quickSort3Ways(arr,gt,1)">41 template <typename T> void quickSort3Ways(T arr[],1)">43 44 __quickSort3Ways( arr,1)">45 49 cout<<一般随机测试:endl; 50 cout<<52 int* arr3 =54 SortTestHelper::testSort(55 SortTestHelper::testSort(56 SortTestHelper::testSort(Quick Sort 3 Ways57 59 [] arr3; 60 cout<<61 测试2 测试近乎有序的数组 62 cout<<测试近乎有序的数组64 cout<<65 arr1 =66 arr2 =67 arr3 =68 SortTestHelper::testSort(69 SortTestHelper::testSort(71 74 cout<<75 测试3 测试存在包含大量相同元素的数组 76 cout<<测试存在包含大量相同元素的数组77 cout<<78 arr1 = SortTestHelper::generaterandomArray(n,1)">79 arr2 =80 arr3 =81 SortTestHelper::testSort(82 SortTestHelper::testSort(83 SortTestHelper::testSort(84 85 86 87 88 }
图解三路快排:

三路快排运行结果:
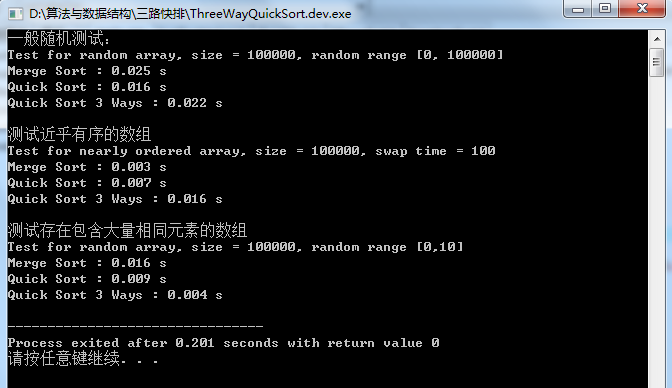
可见性能又进一步提升了:
比较Merge Sort和双路快速排序和三路快排三种排序算法的性能效率
对于包含有大量重复数据的数组,三路快排有巨大的优势
对于一般性的随机数组和近乎有序的数组,三路快排的效率虽然不是最优的,但是在可以接受的范围里
因此,在一些语言中,三路快排是默认的语言库函数中使用的排序算法。比如Java:)
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
