

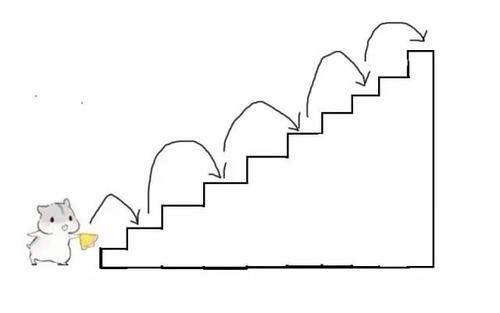
动态规划是什么
动态规划(Dynamic Programming,DP)是运筹学的一个分支,是求解决策过程最优化的过程。20世纪50年代初,美国数学家贝尔曼(R.Bellman)等人在研究多阶段决策过程的优化问题时,提出了著名的最优化原理,从而创立了动态规划。
我们把要解决的一个大问题转换成若干个规模较小的同类型问题,当我们求解出这些小问题的答案,大问题便不攻自破。这就是动态规划。
看一个很经典的介绍 DP 的问题:
“How should i explain Dynamic Programming to a 4-year-old?“
writes down "1+1+1+1+1+1+1+1 =" on a sheet of paper
"What's that equal to?"
counting "Eight!"
writes down another "1+" on the left
"What about that?"
quickly "Nine!"
"How'd you kNow it was nine so fast?"
"You just added one more"
"So you didn't need to recount because you remembered there were eight! Dynamic Programming is just a fancy way to say 'remembering stuff to save time later'"
这个估计大家都能看懂,就不解释了。动态规划其实就是把要解决的一个大问题转换成若干个规模较小的同类型问题。那这里的关键在于小问题的答案,可以进行重复使用,比如经典的爬楼梯问题。
这种思想的本质是:一个规模较大的问题(可以用两三个参数表示),通过若干规模较小的问题的结果来得到的(通常会寻求到一些特殊的计算逻辑,如求最值等)
我们一般看到的状态转移方程,基本类似下面的公式(注:i、j、k 都是在定义DP方程中用到的参数。opt 指代特殊的计算逻辑,大多数情况下为 max 或 min。func 指代逻辑函数):
- dp[i] = opt(dp[i-1])+1
- dp[i][j] = func(i,j,k) + opt(dp[i-1][k])
- dp[i][j] = opt(dp[i-1][j-1],dp[i-1][j])+arr[i][j]
- dp[i][j] = opt(dp[i-1][j] + xi,dp[i][j-1] + yj,...)
- ...
基本思路
动态规划是一个求最值的过程,既然是要求最值,核心问题是什么呢?求解动态规划的核心问题是穷举。因为要求最值,肯定要把所有可行的答案穷举出来,然后在其中找最值。
首先,动态规划的穷举有点特别,因为这类问题存在“重叠子问题”,如果暴力穷举的话效率会极其低下,所以需要“备忘录”或者“DP table”来优化穷举过程,避免不必要的计算。
而且,动态规划问题一定会具备“最优子结构”,才能通过子问题的最值得到原问题的最值。
最后,虽然动态规划的核心思想就是穷举求最值,但是问题可以千变万化,穷举所有可行解其实并不是一件容易的事,只有列出正确的“状态转移方程”才能正确地穷举。
整体框架
- 状态转移方程
- 备忘录存储重复子问题
- 最小子问题
- 求最值
斐波那契数列
斐波那契数列不算动态规划,但是解决问题的思路与动态规划很像,再加上大家上学的时候基本都接触过斐波那契数列,通过它来理解动态规划就很不错了。
int fib(int N) {
if (N == 1 || N == 2) return 1;
return fib(N - 1) + fib(N - 2);
}
这个递归,相信有不少人能看出问题,子问题被不断计算,以N=20为例
fib(20) = fib(19) + fib(18) = fib(18) + fib(17) + fib(18)
写到这里,已经发现,fib(18)已经被计算多次,效率很低下。
所以引入带备忘录的递归算法,把每次计算的子结果的值进行存储,后面就不需要重复计算了。整改之后的代码
int fib(int N) {
int[] dp = int int[N];
// 最小子问题
dp[1] = dp[2] = 1;
for (int i = 3; i <= N; i++) {
// 状态转移方程
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[N];
}
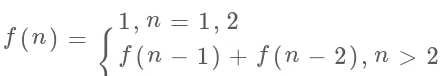
例子:最长回文串
问题:给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
思路:对于一个子串而言,如果它是回文串,并且长度大于2,那么将它首尾的两个字母去除之后,它仍然是个回文串。例如对于字符串“ababa”,如果我们已经知道“bab” 是回文串,那么“ababa” 一定是回文串,这是因为它的首尾两个字母都是“a”。
于是得到我们的状态转移方程:
dp[i][j] 表示i到j之间的字符串是否是回文串
dp[i][j] = dp[i+1][j-1] and (s[i] eq s[j])
最小子问题:当s[i] eq s[j],子串长度是2或3,不需要检查子串是否回文串,即j-i<=2
public String longestpalindrome(String s) {
if (s == null || s.length() <= 1) {
return s;
}
int len = s.length();
int maxLen = 1;
int left = 0;
int right = 0;
boolean[][] dp = new boolean[len][len];
char[] chars = s.tochararray();
// 如果i从0开始,那么对应abba这样的字符串,bb这个子串在遍历过程中没法被当做子问题进行存储
for (int i=len-2; i>=0; i--) {
for (int j=i+1; j<len; j++) {
if (chars[i] == chars[j]) {
if (j-i <= 2) { // 最小字问题
if (j-i+1 > maxLen) {
maxLen = j-i+1;
left = i;
right = j;
}
dp[i][j] = true;
}else if (dp[i+1][j-1]) { // 子问题
if (j-i+1 > maxLen) {
maxLen = j-i+1;
left = i;
right = j;
}
dp[i][j] = true;
}
}
}
}
return s.substring(left,right + 1);
}
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
