

本文介绍如何使用python实现多变量线性回归,文章参考NG的视频和黄海广博士的笔记
现在对房价模型增加更多的特征,例如房间数楼层等,构成一个含有多个变量的模型,模型中的特征为( x1,x2,...,xn)

表示为:
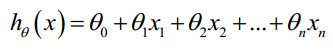
引入 x0=1,则公式
转化为:

1、加载训练数据
数据格式为:
X1,X2,Y
2104,3,399900
1600,329900
2400,369000
1416,2,232000
将数据逐行读取,用逗号切分,并放入np.array
#加载数据
#加载数据
def load_exdata(filename):
data = []
with open(filename,'r') as f:
for line in f.readlines():
line = line.split(',')
current = [int(item) for item in line]
#5.5277,9.1302
data.append(current)
return data
data = load_exdata('ex1data2.txt');
data = np.array(data,np.int64)
x = data[:,(0,1)].reshape((-1,2))
y = data[:,2].reshape((-1,1))
m = y.shape[0]
# Print out some data points
print('First 10 examples from the dataset: \n')
print(' x = ',x[range(10),:],'\ny=',y[range(10),:])
First 10 examples from the dataset:
x = [[2104 3]
[1600 3]
[2400 3]
[1416 2]
[3000 4]
[1985 4]
[1534 3]
[1427 3]
[1380 3]
[1494 3]]
y= [[399900]
[329900]
[369000]
[232000]
[539900]
[299900]
[314900]
[198999]
[212000]
[242500]]
2、通过梯度下降求解theta
(1)在多维特征问题的时候,要保证特征具有相近的尺度,这将帮助梯度下降算法更快地收敛。

解决的方法是尝试将所有特征的尺度都尽量缩放到-1 到 1 之间,最简单的方法就是(X - mu) / sigma,其中mu是平均值, sigma 是标准差。

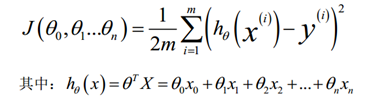
我们的目标和单变量线性回归问题中一样,是要找出使得代价函数最小的一系列参数。多变量线性回归的批量梯度下降算法为:

求导数后得到:

(3)向量化计算
向量化计算可以加快计算速度,怎么转化为向量化计算呢?
在多变量情况下,损失函数可以写为:
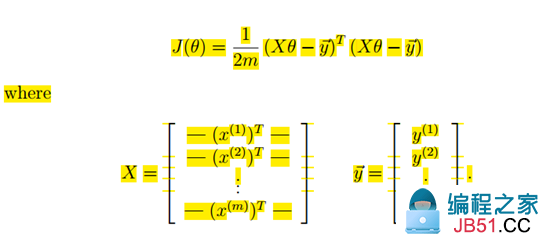
对theta求导后得到:
(1/2*m) * (X.T.dot(X.dot(theta) - y))
因此,theta迭代公式为:
theta = theta (alpha/ y))
(4)完整代码如下:
#特征缩放
def featurenormalize(X):
X_norm = X;
mu = np.zeros((1,X.shape[1]))
sigma = np.zeros((1,X.shape[1]))
for i in range(X.shape[1]):
mu[0,i] = np.mean(X[:,i]) # 均值
sigma[0,i] = np.std(X[:,i]) # 标准差
# print(mu)
# print(sigma)
X_norm = (X - mu) / sigma
return X_norm,mu,sigma
#计算损失
def computeCost(X,y,theta):
m = y.shape[0]
# J = (np.sum((X.dot(theta) - y)**2)) / (2*m)
C = X.dot(theta) - y
J2 = (C.T.dot(C))/ (2*m)
return J2
#梯度下降
def gradientDescent(X,theta,alpha,num_iters):
m = y.shape[0]
#print(m)
# 存储历史误差
J_history = np.zeros((num_iters,1))
for iter in range(num_iters):
# 对J求导,得到 alpha/m * (WX - Y)*x(i), (3,m)*(m,1) X (m,3)*(3,1) = (m,1)
theta = theta - (alpha/m) * (X.T.dot(X.dot(theta) - y))
J_history[iter] = computeCost(X,theta)
return J_history,theta
iterations = 10000 #迭代次数
alpha = 0.01 #学习率
x = data[:,1))
m = y.shape[0]
x,sigma = featurenormalize(x)
X = np.hstack([x,np.ones((x.shape[0],1))])
# X = X[range(2),:]
# y = y[range(2),:]
theta = np.zeros((3,1))
j = computeCost(X,theta)
J_history,theta = gradientDescent(X,iterations)
print('Theta found by gradient descent',theta)
Theta found by gradient descent [[ 109447.79646964]
[ -6578.35485416]
[ 340412.65957447]]
绘制迭代收敛图
plt.plot(J_history)
plt.ylabel('lost');
plt.xlabel('iter count')
plt.title('convergence graph')

使用模型预测结果
def predict(data):
testx = np.array(data)
testx = ((testx - mu) / sigma)
testx = np.hstack([testx,np.ones((testx.shape[0],1))])
price = testx.dot(theta)
print('price is %d ' % (price))
predict([1650,3])
price is 293081
no bb,上代码,代码下载
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
