

一、什么是哈希表
1.概述
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度这个映射函数叫做散列函数,存放记录的数组叫做散列表。
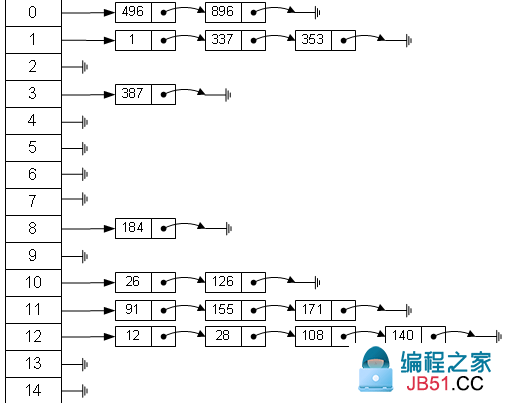
通俗的理解一下:
- 如果我们有n个元素要存储,那我们就用l个内存单元来存储他们
- 然后我们有一个哈希函数f(x),我们把元素n用函数计算得到哈希值,也就是f(n)
- f(n)就是存储元素n的那个内存单位的位置,也就是元素在l中的下标
2.为什么哈希表查询速度快
理解了哈希表的基本思路,我们也就不难理解为什么哈希表查询效率高了:
由于每个元素都能通过哈希函数直接计算获得地址,所以查找消耗时间非常少。
举个例子:
我们有哈希函数f(n)=n%3,现有元素{1,2,3},我们使用哈希函数分别获得其哈希值,并把哈希值作为下标存入一个数组,
也就是放f(1)=1,f(2)=2,f(3)=0,如果使用传统线性查找,需要遍历四次,而使用哈希函数计算并查找,只需要一步就能找到,
可以看得出,理想情况下,哪怕数列再长,找到某个元素都只需要一步。
3.哈希冲突
按照上文的例子,数列{1,3}通过哈希函数f(n)=n%3可以计算出哈希值,但是如果出现两个元素的哈希值相同就会出现哈希冲突,
比如f(1)和f(4)都会算出1,这个时候显然不可能上上面一样通过一个一维数组直接存储。
对此我们有两种方法,即开放地址法和分离链表法:
-
开放地址法:如果某一哈希值对应的位置已经被占用了,就找另一个没被占用的位置。
注:关于开放地址法,具体可以参考这篇文章
-
分离链表法:将散列表的每一个单元都扩展成为一个链表,相同哈希值的元素会被存储在同一个链表中。
- 分离链表法处理冲突简单,且无堆积现象,平均查找长度短
- 链表中的结点是动态申请的
- 相对开放地址法更加节省空间
- 插入与删除结点比较方便
在jdk8中,使用的就是分离链表法,当哈希冲突超过一点的限制,链表会转为红黑树。
二、代码实现
1.节点类
/**
* @Author:huang
* @Date:2020-06-20 10:19
* @Description:节点
*/
public class Node {
//节点序号
int num;
//下一个节点
Node next;
public Node(int num) {
this.num = num;
}
@Override
public String toString() {
return "Node{" + "num=" + num + '}';
}
}
2.单链表
/**
* @Author:黄成兴
* @Date:2020-06-20 10:19
* @Description:单链表
*/
public class SingleLinkList {
private Node head = new Node(0);
public boolean isEmpty() {
return head.next == null;
}
/**
* 添加节点到链表
* @param node 要插入的节点
*/
public void add(Node node) {
Node temp = head;
//遍历链表
while (true) {
if (temp.next == null) {
break;
}
//不是尾节点就继续遍历下一个节点
temp = temp.next;
}
//将尾节点指向即将插入的新节点
temp.next = node;
}
/**
* 展示链表
*/
public void show() {
//判断链表是否为空
if (isEmpty()) {
return;
}
Node temp = head.next;
//遍历链表
while (true) {
if (temp == null) {
break;
}
System.out.println(temp.toString());
temp = temp.next;
}
}
/**
* 根据序号获取节点
* @param num 要获取的节点序号
* @return
*/
public Node get(int num){
//判断链表是否为空
if (isEmpty()) {
return null;
}
Node temp = head.next;
//遍历链表
while (true) {
if (temp == null) {
return null;
}
if (temp.num == num) {
return temp;
}
temp = temp.next;
}
}
/**
* 修改节点
* @param node 要更新的节点
*/
public void update(Node node) {
Node temp = head;
//判断链表是否为空
if (isEmpty()) {
return;
}
//获取要更新的节点序号
int nodeNum = node.num;
//遍历链表
while (true) {
//如果已经遍历完链表
if (temp == null) {
throw new RuntimeException("编号为" + temp.num + "的节点不存在!");
}
//如果找到了该节点
if (temp.num == nodeNum) {
return;
}
//继续遍历下一节点
temp = temp.next;
}
}
/**
* 删除节点
* @param num 要删除的节点编号
*/
public void delete(int num) {
Node temp = head;
//判断链表是否为空
if (isEmpty()) {
return;
}
//遍历链表
while (true) {
//如果链表到底了
if (temp.next == null) {
return;
}
//如果找到了待删除节点的前一个节点
if (temp.next.num == num) {
//判断待删除节点是否为尾节点
if (temp.next.next == null){
temp.next = null;
}else {
temp.next = temp.next.next;
}
return;
}
//继续遍历下一节点
temp = temp.next;
}
}
}
3.哈希表
/**
* @Author:黄成兴
* @Date:2020-07-04 11:36
* @Description:哈希表
*/
public class HashTable {
//数组长度
private int size;
//用于存放数据的数组
private SingleLinkList[] arr;
public HashTable(int size) {
this.size = size;
//初始化数组
arr = new SingleLinkList[size];
//初始化链表
for (int i = 0; i < size; i++) {
arr[i] = new SingleLinkList();
}
}
/**
* 获取哈希值
* @param item
* @return
*/
public int getHashCode(int item) {
return item % 2;
}
/**
* 插入元素
* @param item
*/
public void insert(int item) {
//获取哈希值
int hashCode = getHashCode(item);
//判断哈希值是否超过数组范围
if (hashCode >= size || hashCode < 0) {
throw new RuntimeException("哈希值:" + hashCode + "超出初始化长度!");
}
//如果该元素在链表中不存在就插入
if (arr[hashCode].isEmpty() || arr[hashCode].get(item) == null) {
//插入元素
arr[hashCode].add(new Node(item));
}else {
//否则就更新
arr[hashCode].update(new Node(item));
}
}
/**
* 查找元素
* @param item
*/
public Node get(int item) {
//获取哈希值
int hashCode = getHashCode(item);
//判断哈希值是否超过数组范围
if (hashCode >= size || hashCode < 0) {
return null;
}
//查找元素
return arr[hashCode].get(item);
}
/**
* 删除元素
* @param item
*/
public void delete(int item) {
//获取哈希值
int hashCode = getHashCode(item);
//删除元素
arr[hashCode].delete(item);
}
/**
* 展示某个哈希值对应链表的全部数据
* @param item
*/
public void show(int item) {
//获取哈希值
int hashCode = getHashCode(item);
arr[hashCode].show();
}
/**
* 展示哈希表的所有数据
*/
public void showAll() {
for (int i = 0; i < arr.length; i++) {
//只展示非空链表
if (!arr[i].isEmpty()) {
System.out.println("第"+i+"条链表:");
arr[i].show();
}
}
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
