

查找是在大量的信息中寻找一个特定的信息元素,在计算机应用中,查找是常用的基本运算,例如编译程序中符号表的查找。
定义:根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)。
分类:
-
静态查找和动态查找
- 静态查找:不对表的数据元素和结构进行任何改变。
- 动态查找:在查找过程同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素。
-
无序查找和有序查找。
- 无序查找:被查找数列有序无序均可
- 有序查找:被查找数列必须为有序数列。
一、线性查找
遍历数组并且依次对比值,相等时返回下标
/**
* 在给定数组中线性查找指定元素
* @param arr
* @param target
* @return
*/
public static int search(int[] arr,int target) {
for (int i = 0; i < arr.length; i++) {
if (arr[i] == target) {
return i;
}
}
return -1;
}
二、二分查找
1.思路分析
- 要查找数target,首先要在给定的有序数组中找到中间位置的数,定义为arr[mid]
- 比较target与arr[mid]大小:
- target < arr[mid]:说明target元素的下标小于mid,向右查找
- target > arr[mid]:说明target元素的下标大于mid,向左查找
- target = arr[mid]:即找到了
- 递归重复以上步骤直到找到或者找不到元素为止
2.代码实现
查找不含有重复数字的情况:
/**
* 二分查找不重复目标
* @param arr 查找的数字
* @param left 左指针
* @param right 右指针
* @param target 查找目标
* @return
*/
public static int search(int[] arr,int left,int right,int target) {
//由于每次遍历右指针总是右移,左指针总是右移
//所以当如果查找的是一个不存在的数时,即右指针小于左指针
if (right < left) {
return -1;
}
//获取中位数
int mid = (right + left) / 2;
//如果目标比中位数小,向左递归
if (arr[mid] > target) {
return search(arr,left,mid - 1,target);
} else if (arr[mid] < target) {
//如果目标表中位数打,向右递归
return search(arr,mid + 1,right,target);
} else {
//中位数即为目标
return mid;
}
}
查找含有重复数字的情况:
/**
* 二分查找重复目标
* @param arr 查找的数字
* @param left 左指针
* @param right 右指针
* @param target 查找目标
* @return
*/
public static List<Integer> search(int[] arr,int target) {
ArrayList<Integer> targets = new ArrayList<>();
//由于每次遍历右指针总是右移,左指针总是右移
//所以当如果查找的是一个不存在的数时,即右指针小于左指针
if (right < left) {
return targets;
}
//获取中位数
int mid = (right + left) / 2;
//如果目标比中位数小,向左递归
if (arr[mid] > target) {
return search(arr,target);
} else {
//如果找到了
//向左查找相同的数
int tempIndex = mid - 1;
while (true){
//到第一个数就不再继续找
if(tempIndex < 0 || arr[tempIndex] != target){
break;
}
targets.add(tempIndex);
tempIndex--;
}
//放入中间值
targets.add(mid);
//向右查找相同的数
tempIndex = mid + 1;
while (true) {
//到最后一个数就不再继续找
if(tempIndex > arr.length - 1 || arr[tempIndex] != target){
break;
}
targets.add(tempIndex);
tempIndex++;
}
return targets;
}
}
三、插值查找
插值查找与二分查找基本一致,但是不一样的是不再像二分那样总是将数组均匀分为两份,而是通过公式将分割的中间点自适应定在目标元素附近。

即将原先的mid计算方式换成这个:
//将原先的1/2换为(key-a[low])/(a[high]-a[low])
mid=low+(high-low)*(key-a[low])/(a[high]-a[low])
由于mid的计算方式改为由查找数动态计算,所以为了防止取arr[mid]时下标越界,我们需要新的边界条件:
- 目标target不能小于有序数组最小数,即arr[0]
- 目标target不能大于于有序数组最大数,即arr[arr.length]
所以代码实现如下:
/**
* 插值查找
* @param arr 查找的数字
* @param left 左指针
* @param right 右指针
* @param target 查找目标
* @return
*/
public static List<Integer> search(int[] arr,int target) {
ArrayList<Integer> targets = new ArrayList<>();
//查询大小目标必须在数组范围内,防止arr[mid]时下标越界
if (right < left || target > arr[arr.length - 1] || target < arr[0]) {
return targets;
}
//获取中位数
int mid = left + (right - left) * (target - arr[left]) / (arr[right] - arr[left]);
int midVal = arr[mid];
//如果目标比中位数小,向左递归
if (midVal > target) {
return search(arr,target);
} else if (midVal < target) {
//如果目标表中位数打,向右递归
return search(arr,target);
} else {
//如果找到了
//向左查找相同的数
int tempIndex = mid - 1;
while (true){
//到第一个数就不再继续找
if(tempIndex < 0 || arr[tempIndex] != target){
break;
}
targets.add(tempIndex);
}
//放入中间值
targets.add(mid);
//向右查找相同的数
tempIndex = mid + 1;
while (true) {
//到最后一个数就不再继续找
if(tempIndex > arr.length - 1 || arr[tempIndex] != target){
break;
}
targets.add(tempIndex);
}
return targets;
}
}
四、斐波那契查找
斐波那契查找跟差值查找一样从中位数mid上下文章,但是又有不同之处,要想理解斐波那契查找的思路,需要先了解一下斐波那契数列:
举个例子, {1,1,2,3,5,8,13,21,34,55 } 就是一个斐波那契数列,他有两个特点:
- F[k] = F[k-1] + F[k-2]
- 相邻数之比无限接近黄金分割值0.618
1.思路分析
-
由于F[k] = F[k-1] + F[k-2],我们能推出(F[k]-1)=(F[k-1]-1)+(F[k-2]-1)+1,也就是说:
若数组的长度F[k]-1,则每一数组可以被分成长度为F[k-1]-1和F[k-2]-1的两段,两段的平分点mid即有mid=low+F[k-1]-1
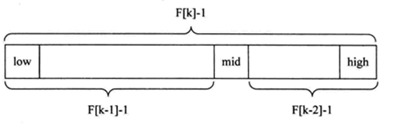
-
但数组长度n不一定刚好等于F[k]-1,所以需要将原来的顺序表长度n增加至F[k]-1。新增的位置(从n+1到F[k]-1位置),都赋为n位置的值即可
举个例子:延长{1,10,89,1000,1234},得到{1,1234,1234},
2.代码实现
/**
* 斐波那契数组长度
*/
public final static int MAXSIZE = 20;
/**
* 获得一个斐波那契数列,用于提供数组分割点位置
* @return
*/
public static int[] getFibonacci() {
int[] f = new int[MAXSIZE];
f[0] = 1;
f[1] = 1;
for (int i = 2; i < MAXSIZE; i++) {
f[i] = f[i - 1] + f[i - 2];
}
return f;
}
/**
* 斐波那契查找
* @param arr
* @param target
* @return
*/
public static int search(int[] arr,int target) {
//数组第一位和最后一位下标
int left = 0;
int right = arr.length - 1;
//斐波那契数列下标
int k = 0;
//生成的斐波那契数列
int[] f = getFibonacci();
//中间值
int mid = 0;
//获取离arr.length-1最近的分割点下标
while (right > f[k] - 1) {
k++;
}
//将数组长度延长到f[k]
int[] temp = Arrays.copyOf(arr,f[k]);
//将延长的那部分用原数组的最后一位填充
for (int i = right + 1; i < f[k]; i++) {
temp[i] = arr[right];
}
//查找目标数字
while (left <= right) {
//获取分割数组的中间点下标
mid = left + f[k - 1] - 1;
//如果元素在分割点的左边
if (target < temp[mid]) {
//向分割点左边查找
right = mid - 1;
//中间点右移到前一个分割点
k--;
} else if (target > temp[mid]) {
//向分割点右边查找
left = mid + 1;
k-=2;
}else {
//找到要查找的数字
//判断要返回的下标
if (mid < right) {
return mid;
}else {
return right;
}
}
}
return -1;
}
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
