<div id="bodyContent">
<div id="Box">
<div id="Box_inner">
<div id="text">
<div id="pages">
<div id="page1" class="page">
<div class="page_content">
<div id="articleHeader">
<h1 id="articleHeader__title">基本动态规划之硬币问题


<div id="bodyContent">
<div id="Box">
<div id="Box_inner">
<div id="text">
<div id="pages">
<div id="page1" class="page">
<div class="page_content">
<div id="articleHeader">
<h1 id="articleHeader__title">基本动态规划之硬币问题
假设有 1 元,3 元,5 元的硬币若干(无限),现在需要凑出 11 元,问如何组合才能使硬币的数量最少?
乍看之下,我们简单的运用一下心算就能解出需要 2 个 5 元和 1 个 1 元的解。当然这里只是列出了这个问题比较简单的情况。当硬币的币制或者种类变化,并且需要凑出的总价值变大时,就很难靠简单的计算得出结论了。贪心算法可以在一定的程度上得出较优解,但不是每次都能得出最优解。
这里运用动态规划的思路解决该问题。按照一般思路,我们先从最基本的情况来一步一步地推导。
我们先假设一个函数 d(i) 来表示需要凑出 i 的总价值需要的最少硬币数量。
接着就不再举例了,我们来分析一下。可以看出,除了第 1 步这个看似基本的公理外,其他往后的结果都是建立在它之前得到的某一步的最优解上,加上 1 个硬币得到。得出:
d(i) = d(j) + 1
这里 j < i。通俗地讲,我们需要凑出 i 元,就在凑出 j 的结果上再加上某一个硬币就行了。
那这里我们加上的是哪个硬币呢。嗯,其实很简单,把每个硬币试一下就行了:
我们分别计算出 d(i - 1) + 1,d(i - 3) + 1,d(i - 5) + 1 的值,取其中的最小值,即为最优解,也就是 d(i)。
最后公式:
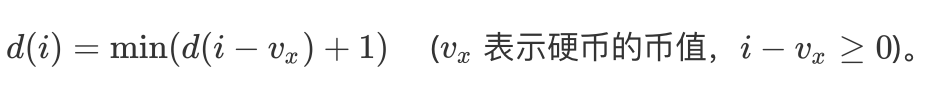
这里用 Java 实现了基本的代码:
public class CoinProblemBasicTest {
private int[] d; // 储存结果
private int[] coins = {1,3,5}; // 硬币种类
privatevoidd_func(int i,int num) {
if (i == 0) {
d[i] = 0;
d_func(i + 1,num);
}
else {
int min = 9999999; // 初始化<a href="/tag/yige/" target="_blank" class="keywords">一个</a>很大的数值。当最后如果得出的结果是这个数时,说明凑不出来。
for (int coin : coins) {
if (i >= coin && d[i - coin] + 1 < min) {
min = d[i - coin] + 1;
}
}
d[i] = min;
if (i < num) {
d_func(i + 1,num);
}
}
}
@Test
publicvoid<a href="/tag/test/" target="_blank" class="keywords">test()</a> throws Exception {
int sum = 11; // 需要凑 11 元
d = new int[sum + 1]; // 初始化数组
d_func(0,sum); // 计算需要凑出 0 ~ sum 元需要的硬币<a href="/tag/shuliang/" target="_blank" class="keywords">数量</a>
for (int i = 0; i <= sum; i++) {
Sy<a href="/tag/stem/" target="_blank" class="keywords">stem</a>.out.println("凑齐 " + i + " 元需要 " + d[i] + " 个硬币");
}
}
}
结果如下:
凑齐 0 元需要 0 个硬币
凑齐 1 元需要 1 个硬币
凑齐 2 元需要 2 个硬币
凑齐 3 元需要 1 个硬币
凑齐 4 元需要 2 个硬币
凑齐 5 元需要 1 个硬币
凑齐 6 元需要 2 个硬币
凑齐 7 元需要 3 个硬币
凑齐 8 元需要 2 个硬币
凑齐 9 元需要 3 个硬币
凑齐 10 元需要 2 个硬币
凑齐 11 元需要 3 个硬币版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
