
文章目录
最近因为一个小需求,需要保存日志到文件中。因为平时调试都只是用print,当不需要的时候又得把print删掉,这样很不方便,而且这样也只能把报错信息输出到控制台。于是上网查了一下,python有一个内置模块logging,用来输出日志信息,可以进行各种配置,看了之后有种相见恨晚的感觉。下面进行一些个人的总结,主要是对自己学习进行的归纳,也希望能对你有所帮助。
1 开始使用 logging
1.1 第一个程序
首先是最简单的使用:
# -*- coding: utf-8 -*-
import logging
logging.debug('debug级别,一般用来打印一些调试信息,级别最低')
logging.info('info级别,一般用来打印一些正常的操作信息')
logging.warning('waring级别,一般用来打印警告信息')
logging.error('error级别,一般用来打印一些错误信息')
logging.critical('critical级别,一般用来打印一些致命的错误信息,等级最高')这样直接就可以在控制台输出日志信息了:
WARNING:root:waring级别,一般用来打印警告信息
ERROR:root:error级别,一般用来打印一些错误信息
CRITICAL:root:critical级别,一般用来打印一些致命的错误信息,等级最高1.2 日志级别
会发现只输出下面三条信息,这是因为logging是分级别的,上面5个级别的信息从上到下依次递增,可以通过设置logging的level,使其只打印某个级别以上的信息。因为默认等级是 WARNING,所以只有 WARNING 以上级别的日志被打印出来。 如果我们想把debug和info也打印出来,可以使用 basicConfig 对其进行配置:
logging.basicConfig(level=logging.DEBUG)这样控制台的输出就会包含上面5条所有信息。
日志级别不是只有python才有,基本上日志都是分级别的,这样可以让我们在不同的时期关注不同的重点,比如我们把一些调试的信息以debug的级别输出,并且把 logging 的 level 设为 DEBUG,这样我们以后不需要显示这些日志的时候,只需要把level设置为info或者更高,不用像 print 一样要去把那条语句注释掉或者删掉。
1.3 输出格式
我们发现上面的日志输出信息很简略,暂时还不能满足我们的需求,比如我们可能需要输出该条信息的时间,所在位置等等,这同样可以通过basicConfig进行配置。
logging.basicConfig(format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s',
level=logging.DEBUG)然后输出就会是这样的格式:
2019-07-19 15:54:26,625 - log_test.py[line:11] - DEBUG: debug级别,一般用来打印一些调试信息,级别最低format 可以指定输出的内容和格式,其内置的参数如下:
%(name)s:Logger的名字
%(levelno)s:打印日志级别的数值
%(levelname)s:打印日志级别的名称
%(pathname)s:打印当前执行程序的路径,其实就是sys.argv[0]
%(filename)s:打印当前执行程序名
%(funcName)s:打印日志的当前函数
%(lineno)d:打印日志的当前行号
%(asctime)s:打印日志的时间
%(thread)d:打印线程ID
%(threadName)s:打印线程名称
%(process)d:打印进程ID
%(message)s:打印日志信息此外,basicConfig 还可以进行许多其他配置,后文继续介绍。
2 输出日志到文件
2.1 使用 basicConfig 配置文件路径
以上我们只是把日志输出到控制台,但很多时候我们可能会需要把日志存到文件,这样程序出现问题时,可以方便我们根据日志信息进行定位。 最简单的方式是使用 basicConfig:
logging.basicConfig(format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s',
level=logging.DEBUG,
filename='test.log',
filemode='a')只是在上面配置的基础上加上filename和 filemode参数,这样就可以把日志输出到 test.log 文件中了,如果没有这个文件的话会自动创建。
其中参数 filemode表示文件打开模式,不设的话默认为’a’,即追加模式,可以不设;也可以设为’w’,每次写日志会覆盖之前的日志。
但是进行这样的操作之后,我们会发现控制台不输出了,怎么做到既输出到控制台又写入到文件呢?
这需要更进一步的学习。
2.2 logging 模块化设计
以上我们只是使用logging进行非常简单的操作,但这样作用有限,其实 logging 库采取了模块化的设计,提供了许多组件:记录器、处理器、过滤器和格式化器。
- Logger 暴露了应用程序代码能直接使用的接口。
- Handler 将(记录器产生的)日志记录发送至合适的目的地。
- Filter 提供了更好的粒度控制,它可以决定输出哪些日志记录。
- Formatter 指明了最终输出中日志记录的内容和格式。
简单地说,其中 Logger 是负责记录日志消息的,然后我们要把这些日志消息放到哪里,交给 Handler 处理,Filter 则帮我们过滤信息(不限于通过级别过滤),Formatter 就是跟上面的 format 一个意思,用来设置日志内容和格式。
这样,我们试一下使用模块的方式,重新记录日志:
logger = logging.getLogger('test')
logger.debug('debug级别,一般用来打印一些调试信息,级别最低')
logger.info('info级别,一般用来打印一些正常的操作信息')
logger.warning('waring级别,一般用来打印警告信息')
logger.error('error级别,一般用来打印一些错误信息')
logger.critical('critical级别,一般用来打印一些致命的错误信息,等级最高')首先第一行 getLogger 获取了一个记录器,其中命名标识了这个 Logger。然后下面的输出方式跟我们一开始 logging 的用法是很相似的,看起来是不是很简单。但这样是不行,运行后会报错:
No handlers could be found for logger "test"是说我们没有为这个logger指定handler,它不知道要怎么处理日志,要输出到哪里去。那我们就给他加一个Handler吧,Handler的种类有很多,常用的有4种:
- logging.StreamHandler -> 控制台输出
- logging.FileHandler -> 文件输出
- logging.handlers.RotatingFileHandler -> 按照大小自动分割日志文件,一旦达到指定的大小重新生成文件
- logging.handlers.TimedRotatingFileHandler -> 按照时间自动分割日志文件
现在我们先使用最简单的StreamHandler把日志输出到控制台:
logger = logging.getLogger('test')
stream_handler = logging.StreamHandler()
logger.addHandler(stream_handler)
...这样就可以在控制台看到:
waring级别,一般用来打印警告信息
error级别,一般用来打印一些错误信息
critical级别,一般用来打印一些致命的错误信息,等级最高还是少了几条日志,因为我们没有设置日志级别,我们同样设置一下级别,并且也使用Formatter模块设置一下输出格式。
logger = logging.getLogger('test')
logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
stream_handler = logging.StreamHandler()
stream_handler.setLevel(logging.DEBUG)
stream_handler.setFormatter(formatter)
logger.addHandler(stream_handler)
...我们发现Formatter是给handler设置的,这很好理解,因为handler是负责把日志输出到哪里,所以是给它设置格式,而不是给logger;那为什么level需要设置两次呢?给logger设置是告诉它要记录哪些级别的日志,给handler设是告诉它要输出哪些级别的日志,相当于进行了两次过滤。这样的好处在于,当我们有多个日志去向时,比如既保存到文件,又输出到控制台,就可以分别给他们设置不同的级别;logger 的级别是先过滤的,所以被 logger 过滤的日志 handler 也是无法记录的,这样就可以只改 logger 的级别而影响所有输出。两者结合可以更方便地管理日志记录的级别。
有了handler,我们就可以很方便地同时将日志输出到控制台和文件:
logger = logging.getLogger('test')
logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
file_handler = logging.FileHandler('test2.log')
file_handler.setLevel(level=logging.INFO)
file_handler.setFormatter(formatter)
stream_handler = logging.StreamHandler()
stream_handler.setLevel(logging.DEBUG)
stream_handler.setFormatter(formatter)
logger.addHandler(file_handler)
logger.addHandler(stream_handler)只需要多加一个FileHandler即可。
2.3 自动分割日志文件
有时候我们需要对日志文件进行分割,以方便我们的管理。python 提供了两个处理器,方便我们分割文件:
- logging.handlers.RotatingFileHandler -> 按照大小自动分割日志文件,一旦达到指定的大小重新生成文件
- logging.handlers.TimedRotatingFileHandler -> 按照时间自动分割日志文件
使用方法跟上面的 Handler 类似,只是需要添加一些参数配置,比如when='D'表示以天为周期切分文件,其他参数的意思可以参考:Python + logging 输出到屏幕,将log日志写入文件
from logging import handlers
time_rotating_file_handler = handlers.TimedRotatingFileHandler(filename='rotating_test.log', when='D')
time_rotating_file_handler.setLevel(logging.DEBUG)
time_rotating_file_handler.setFormatter(formatter)
logger.addHandler(time_rotating_file_handler)若改为when='S',则以秒为周期进行切割,运行几次后会生成文件:
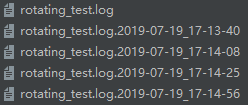
其中没有后缀的为最新日志文件。
参考文章: Python + logging 输出到屏幕,将log日志写入文件 Python标准模块–logging
原文地址:https://cloud.tencent.com/developer/article/2028465
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。