
PostgreSQL10版本一个重量级的新特性是支持内置分区表,在分区表方面前进了一大步,目前支持范围分区和列表分区。
1.1 分区表的意义
分区表主要有以下优势:
当查询或更新一个分区上的大部分数据时,对分区进行索引扫描代价很大,然而,在分区上使用顺序扫描能提升性能。
当需要删除一个分区数据时,通过DROPTABLE删除一个分区,远比DELETE删除数据高效,特别适用于日志数据场景。
由于一个表只能存储在一个表空间上,使用分区表后,可以将分区放到不同的表空间上,例如可以将系统很少访问的分区放到廉价的存储设备上,也可以将系统常访问的分区存储在高速存储上。
分区表的优势主要体现在降低大表管理成本和某些场景的性能提升,相比普通表性能有何差异?本章将对传统分区表、内置分区表做性能测试。
1.2 传统分区表
传统分区表是通过继承和触发器方式实现的,其实现过程步骤多,非常复杂,需要定义父表、定义子表、定义子表约束、创建子表索引、创建分区插入、删除、修改函数和触发器等,可以说是在普通表基础上手工实现的分区表。在介绍传统分区表之前先介绍继承,继承是传统分区表的重要组成部分。
1.2.1 继承表
inherits
create table 子表名(sql text) inherits(父表名);------建立继承表
子表可以继承父表的字段;
向子表与父表分别插入一条数据,父表可以查询到这两条数据,子表仅可以查询的在子表插入的呢一条;
查询父表会将子表的记录数也列出,但子表自定义的字段没有显示,如果想确定数据来源于哪张表,可通过以下SQL查看表的oid
SELECT tableoid,* FROM 父表名;
tableoid是表的隐藏宇段,表示表的om,可通过pg_class系统表关联找到表名
如果只想查询父表的数据,需在父表名称前加上关键字ONLY
select * from only 父表名;
因此,对于UPDATE、DELETE、SELECT操作,如果父表名称前没有加ONLY,则会对父表和所有子表进行DML操作
1.2.2 创建分区表
接下来介绍传统分区表的创建,传统分区表创建过程主要包括以下几个步骤。
步骤1:创建父表,如果父表上定义了约束,子表会继承,因此除非是全局约束,否则不应该在父表上定义约束,另外,父表不应该写人数据。
步骤2:通过INHERITS方式创建继承表,也称之为子表或分区,子表的字段定义应该和父表保持一致。
步骤3:给所有子表创建约束,只有满足约束条件的数据才能写人对应分区,注意分区约束值范围不要有重叠。
步骤4:给所有子表创建索引,由于继承操作不会继承父表上的索引,因此索引需要手工创建。
步骤5:在父表上定义INSERT、DELETE、UPDATE触发器,将SQL分发到对应分区,这步可选,因为应用可以根据分区规则定位到对应分区进行DML操作。
步骤6:启用constraint_exclusion参数,如果这个参数设置成off,则父表上的SQL性能会降低,后面会通过示例解释这个参数。---------8.2.5
注:父表和子表都可以定义主键约束,但会带来一个问题,由于峰和子表的主键约束是分别创建的,那么可能在父表和子表中存在重复的主键数据,这对整个分区表说来做不到主键唯一,举个简单的例子,假如在父表和所有子表的userid字段上创建主键,父表与子表及子表与子表之间可能存在相同的userid,这点需要注意。
1.2.3 使用分区表
1.2.4 查询父表还是子表
根据执行计划可以看出查询子表比查询父表性能会好很多!
在实际生产过程中,对于传统分区表分区方式,不建议应用访问父表,而是直接访问子表,也许有人会问,应用如何定位到访问|那张子表呢?可以根据预先的分区约束定义,本节这个例子log_ins是根据时间范围分区,那么应用可以根据时间来判断查询哪张子表,当然,以上是根据分区表分区键查询的场景,如果根据非分区键查询则会扫描分区表的所有分区。
1.2.5 constraint_exclusion参数
constraint_ exclusion参数用来控制优化器是否根据表上的约束来优化查询,参数值为以下值:
on:所有表都通过约束优化查询;
off:所有表都不通过约束优化查询;
partition:只对继承表和UNIONALL子查询通过检索约束来优化查询;
简单地说,如果设置成on或partition,查询父表时优化器会根据子表上的约束判断检索哪些子表,而不需要扫描所有子表,从而提升查询性能;
1.2.6 添加分区
添加分区属于分区表维护的常规操作之一,比如历史表范围分区到期之前需要扩分区,log_ ins表为日志表,每个分区存储当月数据,假如分区’快到期了,可通过以下SQL扩分区,首先创建子表
CREATE TABLE log_ins_201801 (CHECK ( create_tirne >=’2018-01-01『andcreate time <’2018-02-01’)) INHERITS (父表);
通常会多定义一些分区,这个操作要根据具体场景来进行。
之后创建相关索引,如下所示:
CREATE INDEX idx_log_ins_20180l_ctirne ON log_ins一201801USING btree (create time);
然后刷新触发器函数log_ins_insert_ trigger(),添加相应代码,将符合路由规则的数据插入新分区,详见之前定义的这个函数,这步完成后,添加分区操作完成,可通过\d+log_ ins命令查看log_ins的所有分区。
这种方法比较直接,创建分区时就将分区继承到父表,如果中间步骤有错可能对生产系统带来影响,比较推荐的做法是将以上操作分解成以下几个步骤,降低对生产系统的影响,如下所示:
一创建分区CREATE TABLE log_ins_201802(LIKE log_ins INCLUDING ALL);
一添加约束ALTER TABLE log ins 201802 ADD CONSTRAINT log ins 201802_create_ time_check CHECK ( create time >=’2018-02-01’ANDcreate time <’2018-03-01’);
一刷新触发器函数logins insert trigger() 函数刷新前建议先备份函数代码。--所有步骤完成后,将新分区log_ins_201802继承到父表log_ins ALTER TABLE log_ins_201802 INHERIT log_ins;
以上方法是将新分区所有操作完成后,再将分区继承到父表,降低了生产系统添加分区操作的风险
1.2.7 删除分区
删除分区有两种方法:
第一种就是直接删除表,drop table 表名;就可以了;
推荐第二种方法就是将分区的继承关系去掉;alter table 表名 no inherit 父表;
使用第二种方法后,log_ins_ 201802分区不再属于分区表log_ins的分区,但log_ins_201802表依然保留可供查询,这种方式相比方法一提供了一个缓冲时间,属于比较稳妥的删除分区方法,因为在拿掉子表继承关系后,只要没删除这个子表,还可以使子表重新继承父表。
1.2.8 分区表相关查询
\d 父表名 ------可以查询
1.2.9 性能测试
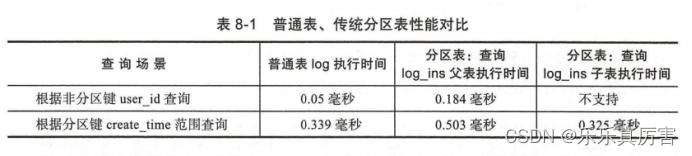
从以上测试结果来看,在根据userid检索的场景下,分区表的性能比普通表性能差了2.68倍;在根据create_time范围检索的场景下,分区表的性能比普通表性能差了0.4倍左右,如果查询能定位到子表,则比普通表性能略有提升,从分区表的角度来看,createtime 作为分区键,userid作为非分区键,从这个测试可以得出以下结论:
1 )分区表根据非分区键查询相比普通表性能差距较大,因为这种场景分区表的执行计划会扫描所有分区;
2)分区表根据分区键查询相比普通表性能有小幅降低,而查询分区表子表性能比普通表略有提升;
以上两个场景除了场景二直接检索分区表子表,性能相比普通表略有提升,其他测试项分区表比普通表性能都低,因此出于性能考虑对生产环境业务表做分区表时需慎重,使用分区表不一定能提升性能,如果业务模型90%(估算的百分比,意思是大部分)以上的操作都能基于分区健操作,并且SQL可以定位到子表,这时建议使用分区表。
1.2.10 传统分区表注意事项
传统分区表的使用有以下注意事项:
当往父表上插入数据时,需事先在父表上创建路由函数和触发器,数据才会根据分区键路由规则插入到对应分区中,目前仅支持范围分区和列表分区。
分区表上的索引、约束需要使用单独的命令创建,目前没有办法一次性自动在所有分区上创建索引、约束。
父表和子表允许单独定义主键,因此父表和子表可能存在重复的主键记录,目前不支持在分区表上定义全局主键。
UPDATE时不建议更新分区键数据,特别是会使数据从一个分区移动到另一分区的场景,可通过更新触发器实现,但会带来管理上的成本。
性能方面:根据本节的测试数据和测试场景,传统分区表根据非分区键查询相比普通表性能差距较大,因为这种场景下分区表会扫描所有分区;根据分区键查询相比普通表性能有小幅降低,而查询分区表子表性能相比普通表略有提升;
1.3 内置分区表
PostgreSQL 10一个重量级新特性是支持内置分区表,用户不需要预先在父表上定义INSERT、DELETE、UPDATE触发器,对父表的DML操作会自动路由到相应分区,相比传统分区表大幅度降低了维护成本,目前仅支持范围分区和列表分区,本小节将以创建范围分区表为例,演示PostgreSQLl0内置分区表的创建、使用与性能测试。
1.3.1 创建分区表
创建分区表的主要语法包含两部分:创建主表和创建分区
创建主表语法如下:
create table table_name (...) [ partition by { range | list } ( { column_name | ( expression)}
创建主表时须指定分区方式,可选的分区方式为RANGE范围分区或LIST列表分区,并指定宇段或表达式作为分区键。创建分区的语法如下:
CREATE TABLE table name PARTITION OF parent_table [ ( ) ] FOR VALUES partition_bound_spec
创建分区时必须指定是哪张表的分区,同时指定分区策略partition_bound_ spec,如果是范围分区,partition_bound_spec须指定每个分区分区键的取值范围,如果是列表分区partition_ bound_ spec,需指定每个分区的分区键值。
PostgreSQLlO创建内置分区表主要分为以下几个步骤:
1 )创建父表,指定分区键和分区策略。
2)创建分区,创建分区时须指定分区表的父表和分区键的取值范围,注意分区键的范围不要有重叠,否则会报错。
3)在分区上创建相应索引,通常情况下分区键上的索引是必须的,非分区键的索引可根据实际应用场景选择是否创建。
1.3.2 使用分区表
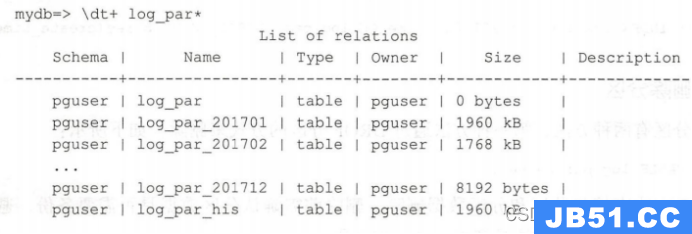
向分区表插入数据,如下所示:

从以上结果可以看出,父表Jog_par没有存储任何数据,数据存储在分区中,通过分区大小也可以证明这一点,
1.3.3 内置分区表原理探索
内置分区表原理实际上和传统分区表一样,也是使用继承方式,分区可称为子表;
1.3.4 添加分区
添加分区的操作比较简单,例如给log_par增加一个分区,如下所示:
CREATE TABLE log_par一201801PARTITION OF log_par FOR VALUES FROM (’2018-01-01')TO (’2018-02-01’);
之后给分区创建索引,如下所示:
CREATE INDEX idx_log_par_201801_ctime ON log_par_201801 USING btree(create time);
1.3.5 删除分区
删除分区的方法有两种,第一种删除分区,和继承分区一样;
推荐第二种解绑分区:
alter table log_par deatch partition log_par_201801;
第二种方法如果后续需要在使用这个分区的话可以再通过连接分区的方式恢复分区即可;
ALTER TABLE log_par ATTACH PARTITION log_par_201801 FOR VALUES FROM (’2018-01-01')TO (’2018-02-01');
1.3.6 性能测试
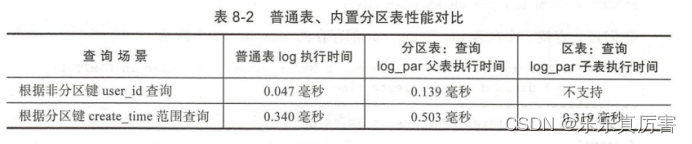

从上表看出传统分区表和内置分区表的在两个查询场景的性能表现一致,根据测试结果同样能得出以下结论:
内置分区表根据非分区键查询相比普通表性能差距较大,因为这种场景分区表的执行计划会扫描所有分区;
内置分区表根据分区键查询相比普通表性能有小幅降低,而查询分区表子表性能比普通表略有提升;
以上两个场景除了场景二直接检索分区表子表,性能相比普通表略有提升,其他测试项分区表比普通表性能都低,因此出于性能考虑对生产环境业务表做分区表时需慎重,使用分区表不一定能提升性能,但内置分区表相比传统分区表省去了创建触发器路由函数、触发器操作,减少了大量维护成本,相比传统分区表有较大管理方面的优势。
1.3.7 constraint_exclusion 参数
内置分区表执行计划依然受constraintexclusion参数影响,关闭此参数后,根据分区键查询时执行计划不会定位到相应分区。
从执行计划看出扫描了分区表上的所有分区,执行时间上升到了0.607毫秒,同样,这个参数建议设置成partition,不建议设置成on,优化器通过检查约束来优化查询的方式本身就带来一定开销,如果所有表都启用这个特性,将加重优化器负担。
1.3.8 更新分区数据
内置分区表UPDATE操作目前不支持新记录跨分区的情况,也就是说只允许分区内的更新,例如以下SQL会报错:
mydb=> SELECT * FROM log par 201701 LIMIT l;
id I user id I create time
---+----------+------------
44641 I 16965492 I 2017-01-01 00:00:00
(1 row)
mydb=> UPDATE log_par SET create_time=’2017-02-02 01:01:01’WHERE user_id=16965492; ERROR: new row for relation ”log_par_201701”violates partition constraint DETAIL: Failing row contains (44641,16965492,2017-02-02 01: 01: 01).
以上user_id等于16965492的记录位于log_par_201701分区,将这条记录的create_time更新为’2017-02-0201:01:01’由于违反了当前分区的约束将报错,如果更新的数据不违反当前分区的约束则可正常更新数据,如下所示:
mydb=> UPDATE log_par SET create_time='2017-01-0101:01:01’ WHERE user_id=16965492;UPDATE 1 目前内置分区表的这一限制对于日志表影响不大,对于业务表有一定影响,使用时需注意。
1.3.9 内置分区表注意事项
本节简单介绍了内置分区表的部署、使用示例,使用内置分区表有以下注意事项:
当往父表上插入数据时,数据会自动根据分区键路由规则插入到分区中,目前仅支持范围分区和列表分区。
分区表上的索引、约束需使用单独的命令创建,目前没有办法一次性自动在所有分区上创建索引、约束。
内置分区表不支持定义(全局)主键,在分区表的分区上创建主键是可以的。
内置分区表的内部实现使用了继承。
如果UPDATE语句的新记录违反当前分区键的约束则会报错,UPDAET语句的新记录目前不支持跨分区的情况。
性能方面:根据本节的测试场景,内置分区表根据非分区键查询相比普通表性能差距较大,因为这种场景分区表的执行计划会扫描所有分区;根据分区键查询相比普通表性能有小幅降低,而查询分区表子表性能相比普通表略有提升。
原文地址:https://blog.csdn.net/qq_58883939/article/details/126636408
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。