
上文介绍了磁盘管理器中VFD的实现原理,本篇将从上层角度讲解磁盘管理器的工作细节。相关知识见回顾: postgres源码解析52 磁盘管理器–1
关键数据结构说明
本地全局变量
static HTAB *SMgrRelationHash = NULL;
SmgrRelationHash哈希表,存放该进程已打开的SmgrRelation对象,用于后续加速查找。键为RelFileNodeBackend结构体,值为SmgrRelation条目。
static dlist_head unowned_relns;
该变量是一个双向链表结构,用于记录 “unowned” SmgrRelation对象
在磁盘管理器中,每打开一个relation会为其分配一个SMgrRelationData 对象,该结构体记录了relation的存储信息、该对象的引用者以及relation各分支已打开最大文件段号。
每个relation有多种分支,如下:
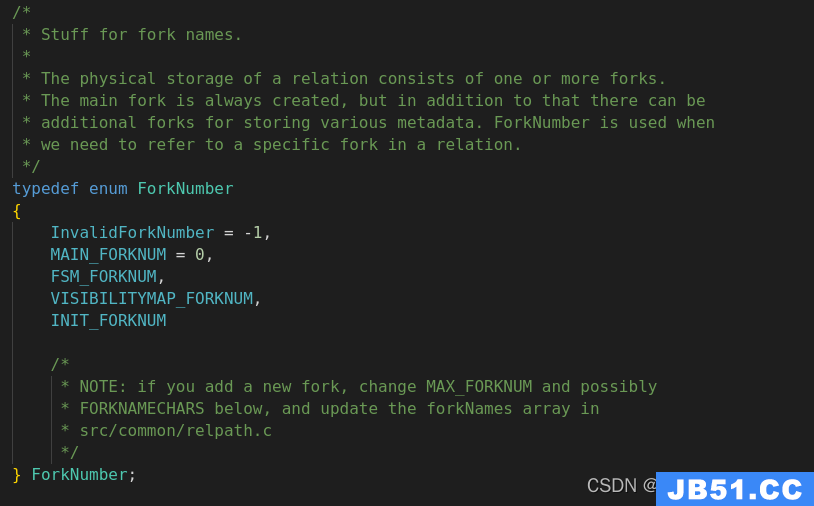
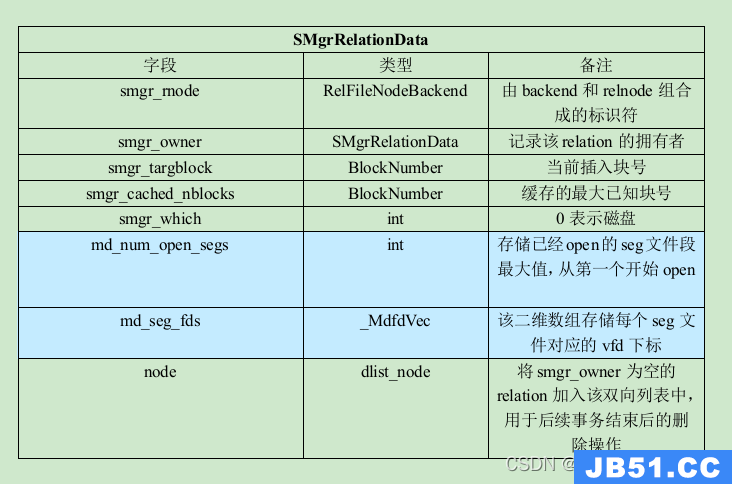
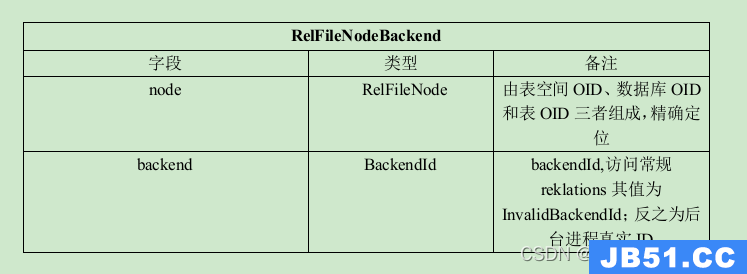
RelFileNodeBackend结构体为用户提供了定位relation物理存储的相关信息。
smgr模块接口函数
f_smgr 该结构体定义了存储管理器模块涉及的函数指针
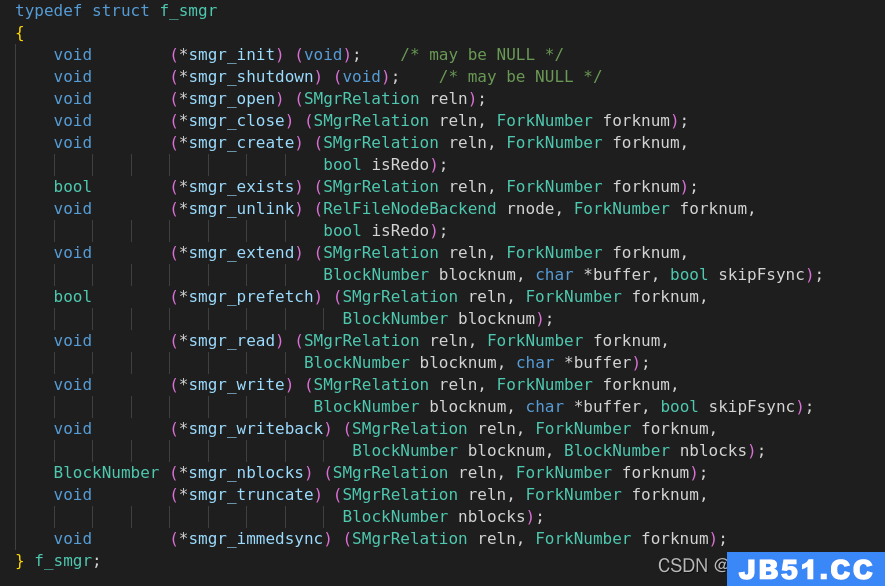
存储管理器与磁盘管理器两者间的关联函数映射关系
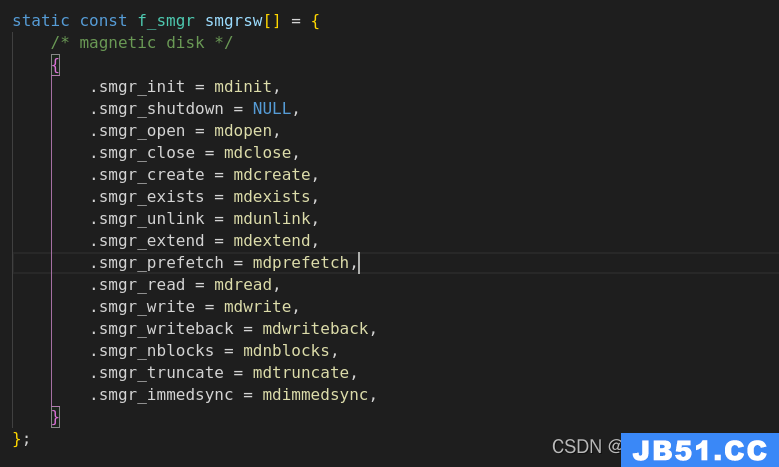
相关函数讲解
1 void smgrinit(void)
该函数的功能是负责初始化存储管理器,在后台进程启动时会调用此函数,而在postmaster启动时并不会负责启动。
void smgrinit(void)
{
int i;
for (i = 0; i < NSmgr; i++)
{
if (smgrsw[i].smgr_init)
smgrsw[i].smgr_init();
}
/* register the shutdown proc */
// 注册退出函数
on_proc_exit(smgrshutdown, 0);
}
2 SMgrRelation smgropen(RelFileNode rnode,BackendId backend)
该函数的功能是打开指定的文件,并返回SMgrRelation对象,必要时需创建。
执行流程:
1)首先查看进程本地SMgrRelationHash哈希表是否已打开此文件,如果已打开,直接返对应的SMgrRelation 对象,反之进入步骤2)。若哈希表未建立,需在动态哈希上下文创建。
2)初始化新的 SMgrRelation对象,填充相关字段为默认值,后调用 smgr_open函数打开对应文件。
SMgrRelation smgropen(RelFileNode rnode, BackendId backend)
{
RelFileNodeBackend brnode;
SMgrRelation reln;
bool found;
if (SMgrRelationHash == NULL)
{
/* First time through: initialize the hash table */
HASHCTL ctl;
ctl.keysize = sizeof(RelFileNodeBackend);
ctl.entrysize = sizeof(SMgrRelationData);
SMgrRelationHash = hash_create("smgr relation table", 400,
&ctl, HASH_ELEM | HASH_BLOBS);
dlist_init(&unowned_relns);
}
/* Look up or create an entry */
brnode.node = rnode;
brnode.backend = backend;
reln = (SMgrRelation) hash_search(SMgrRelationHash,
(void *) &brnode,
HASH_ENTER, &found);
/* Initialize it if not present before */
if (!found)
{
/* hash_search already filled in the lookup key */
reln->smgr_owner = NULL;
reln->smgr_targblock = InvalidBlockNumber;
for (int i = 0; i <= MAX_FORKNUM; ++i)
reln->smgr_cached_nblocks[i] = InvalidBlockNumber;
reln->smgr_which = 0; /* we only have md.c at present */
/* implementation-specific initialization */
smgrsw[reln->smgr_which].smgr_open(reln);
/* it has no owner yet */
dlist_push_tail(&unowned_relns, &reln->node);
}
return reln;
}
*3 void smgrsetowner(SMgrRelation owner,SMgrRelation reln)
该函数的功能是为SMgrRelation 对象建立正确的引用关系。
执行流程:
1)首先判断此SMgrRelation 对象是否已有引用关系,有则解除(置为NULL);无则需从unowned链表中移除此对象;
2)紧接着建立正确的引用关系。
void smgrsetowner(SMgrRelation *owner, SMgrRelation reln)
{
/* We don't support "disowning" an SMgrRelation here,use smgrclearowner */
Assert(owner != NULL);
/*
* First,unhook any old owner. (Normally there shouldn't be any,but it
* seems possible that this can happen during swap_relation_files()
* depending on the order of processing. It's ok to close the old
* relcache entry early in that case.)
*
* If there isn't an old owner,then the reln should be in the unowned
* list,and we need to remove it.
*/
if (reln->smgr_owner)
*(reln->smgr_owner) = NULL;
else
dlist_delete(&reln->node);
/* Now establish the ownership relationship. */
reln->smgr_owner = owner;
*owner = reln;
}
*4 void smgrclearowner(SMgrRelation owner,SMgrRelation reln)
该函数的功能是将清除SMgrRelation 对象的引用关系。
执行流程:
1)判断清除的SMgrRelation对象其引用者是否为指定引用者,如果不是直接返回;
2)解除原引用关系,并将其添加至 unowned链表尾部。
void smgrclearowner(SMgrRelation *owner, SMgrRelation reln)
{
/* Do nothing if the SMgrRelation object is not owned by the owner */
if (reln->smgr_owner != owner)
return;
/* unset the owner's reference */
*owner = NULL;
/* unset our reference to the owner */
reln->smgr_owner = NULL;
/* add to list of unowned relations */
dlist_push_tail(&unowned_relns, &reln->node);
}
*5 void smgrclose(SMgrRelation owner,SMgrRelation reln)
该函数的功能是关闭并删除指定的SMgrRelation 对象.
执行流程:
1)调用mdclose关闭该SMgrRelation对象的所有分支;
2)紧接着判断该SMgrRelation对象是否有引用者,如果没有,需要从unowned链表移除;
3)最后从本地的smgr哈希表中移除此SMgrRelation对象,并设置其引用者为NULL;
void smgrclose(SMgrRelation reln)
{
SMgrRelation *owner;
ForkNumber forknum;
for (forknum = 0; forknum <= MAX_FORKNUM; forknum++)
smgrsw[reln->smgr_which].smgr_close(reln, forknum);
owner = reln->smgr_owner;
if (!owner)
dlist_delete(&reln->node);
if (hash_search(SMgrRelationHash,
(void *) &(reln->smgr_rnode),
HASH_REMOVE, NULL) == NULL)
elog(ERROR, "SMgrRelation hashtable corrupted");
/*
* Unhook the owner pointer,if any. We do this last since in the remote
* possibility of failure above,the SMgrRelation object will still exist.
*/
if (owner)
*owner = NULL;
}
*6 void smgrdosyncall(SMgrRelation rels,int nrels)
该函数的功能是将给定的所有SMgrRelation对象的所有分支sync至磁盘 。
执行流程:
1)首先调用FlushRelationsAllBuffers将所有的SMgrRelation对象的所有分支在共享缓冲池的数据页刷出。
2)然后依次将上述所有的SMgrRelation对象刷出的缓冲页sync至磁盘。
void smgrdosyncall(SMgrRelation *rels, int nrels)
{
int i = 0;
ForkNumber forknum;
if (nrels == 0)
return;
FlushRelationsAllBuffers(rels, nrels);
/*
* Sync the physical file(s).
*/
for (i = 0; i < nrels; i++)
{
int which = rels[i]->smgr_which;
for (forknum = 0; forknum <= MAX_FORKNUM; forknum++)
{
if (smgrsw[which].smgr_exists(rels[i], forknum))
smgrsw[which].smgr_immedsync(rels[i], forknum);
}
}
}
*7 void smgrdounlinkall(SMgrRelation rels,int nrels,bool isRedo)
该函数的功能是将给定的所有SMgrRelation对象的所有分支从磁盘中移除。
执行流程:
1)首先将给定的所有SMgrRelation对象的所有分支在共享缓冲池的数据页移除;
2)紧接着关闭所有SMgrRelation对象的所有分支;
3)然后注册SMgrRelation对象与物理文件的无效映射信息,并告知其他进程;
4)最后删除所有SMgrRelation对象的所有分支所对应的物理文件。
void smgrdounlinkall(SMgrRelation *rels, int nrels, bool isRedo)
{
int i = 0;
RelFileNodeBackend *rnodes;
ForkNumber forknum;
if (nrels == 0)
return;
/*
* Get rid of any remaining buffers for the relations. bufmgr will just
* drop them without bothering to write the contents.
*/
DropRelFileNodesAllBuffers(rels, nrels);
/*
* create an array which contains all relations to be dropped,and close
* each relation's forks at the smgr level while at it
*/
rnodes = palloc(sizeof(RelFileNodeBackend) * nrels);
for (i = 0; i < nrels; i++)
{
RelFileNodeBackend rnode = rels[i]->smgr_rnode;
int which = rels[i]->smgr_which;
rnodes[i] = rnode;
/* Close the forks at smgr level */
for (forknum = 0; forknum <= MAX_FORKNUM; forknum++)
smgrsw[which].smgr_close(rels[i], forknum);
}
/*
* It'd be nice to tell the stats collector to forget them immediately,* too. But we can't because we don't know the OIDs.
*/
/*
* Send a shared-inval message to force other backends to close any
* dangling smgr references they may have for these rels. We should do
* this before starting the actual unlinking,in case we fail partway
* through that step. Note that the sinval messages will eventually come
* back to this backend,too,and thereby provide a backstop that we
* closed our own smgr rel.
*/
for (i = 0; i < nrels; i++)
CacheInvalidateSmgr(rnodes[i]);
/*
* Delete the physical file(s).
*
* Note: smgr_unlink must treat deletion failure as a WARNING,not an
* ERROR,because we've already decided to commit or abort the current
* xact.
*/
for (i = 0; i < nrels; i++)
{
int which = rels[i]->smgr_which;
for (forknum = 0; forknum <= MAX_FORKNUM; forknum++)
smgrsw[which].smgr_unlink(rnodes[i], forknum, isRedo);
}
pfree(rnodes);
}
*8 void smgrextend(SMgrRelation reln,ForkNumber forknum,BlockNumber blocknum,char buffer,bool skipFsync)
该函数的功能是负责为指定的relation新增一块页,本质是对mdextend函数的进一步封装。
1)调用mdextend函数为指定的relation新增一块页;
2)更新该relation对应分支的块数并加以缓存,加速后续此信息的获取。
void smgrextend(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum,
char *buffer, bool skipFsync)
{
smgrsw[reln->smgr_which].smgr_extend(reln, blocknum,
buffer, skipFsync);
/*
* Normally we expect this to increase nblocks by one,but if the cached
* value isn't as expected,just invalidate it so the next call asks the
* kernel.
*/
if (reln->smgr_cached_nblocks[forknum] == blocknum)
reln->smgr_cached_nblocks[forknum] = blocknum + 1;
else
reln->smgr_cached_nblocks[forknum] = InvalidBlockNumber;
}
*9 void smgrread(SMgrRelation reln,char buffer)
该函数的功能是负责将指定relation的某一数据页加载至缓冲区中,其本质是对mdread函数的进一步封装。
void smgrread(SMgrRelation reln, char *buffer)
{
smgrsw[reln->smgr_which].smgr_read(reln, buffer);
}
*10 void smgrwrite(SMgrRelation reln,bool skipFsync)
该函数的功能是负责将指定relation的某一数据页所对应的缓冲块写至持久化存储中,其本质是对mdwrite函数的进一步封装。
void smgrwrite(SMgrRelation reln,
char *buffer, bool skipFsync)
{
smgrsw[reln->smgr_which].smgr_write(reln,
buffer, skipFsync);
}
11 void smgrwriteback(SMgrRelation reln,BlockNumber nblocks)
该函数的功能是告知内核将指定数目的脏块写至磁盘,本质是对mdwriteback的进一步封装。
void smgrwriteback(SMgrRelation reln, BlockNumber nblocks)
{
smgrsw[reln->smgr_which].smgr_writeback(reln, nblocks);
}
12 BlockNumber smgrnblocks(SMgrRelation reln,ForkNumber forknum)
该函数的功能是计算指定relation对应分支的文件块数目,本质是对mdnblocks的进一步封装。
BlockNumber smgrnblocks(SMgrRelation reln, ForkNumber forknum)
{
BlockNumber result;
// 首先在缓冲里找,没找到需调用 mdnblocks函数进一步获取
/* Check and return if we get the cached value for the number of blocks. */
result = smgrnblocks_cached(reln, forknum);
if (result != InvalidBlockNumber)
return result;
result = smgrsw[reln->smgr_which].smgr_nblocks(reln, forknum);
reln->smgr_cached_nblocks[forknum] = result;
return result;
}
13 void smgrtruncate(SMgrRelation reln,ForkNumber *forknum,int nforks,BlockNumber *nblocks)
该函数的功能是将截断指定文件块前的所有段;
执行流程:
1)首先从共享缓冲池中移除待删除块前的所有缓冲块;
2)紧接着向其他进程发送无效信息以强制关闭其对smgr对象的引用。
3)调用mdtruncate函数进行真正地截断操作。
void smgrtruncate(SMgrRelation reln, ForkNumber *forknum, int nforks, BlockNumber *nblocks)
{
int i;
/*
* Get rid of any buffers for the about-to-be-deleted blocks. bufmgr will
* just drop them without bothering to write the contents.
*/
DropRelFileNodeBuffers(reln, nforks, nblocks);
/*
* Send a shared-inval message to force other backends to close any smgr
* references they may have for this rel. This is useful because they
* might have open file pointers to segments that got removed,and/or
* smgr_targblock variables pointing past the new rel end. (The inval
* message will come back to our backend,causing a
* probably-unnecessary local smgr flush. But we don't expect that this
* is a performance-critical path.) As in the unlink code,we want to be
* sure the message is sent before we start changing things on-disk.
*/
CacheInvalidateSmgr(reln->smgr_rnode);
/* Do the truncation */
for (i = 0; i < nforks; i++)
{
/* Make the cached size is invalid if we encounter an error. */
reln->smgr_cached_nblocks[forknum[i]] = InvalidBlockNumber;
smgrsw[reln->smgr_which].smgr_truncate(reln, forknum[i], nblocks[i]);
/*
* We might as well update the local smgr_cached_nblocks values. The
* smgr cache inval message that this function sent will cause other
* backends to invalidate their copies of smgr_fsm_nblocks and
* smgr_vm_nblocks,and these ones too at the next command boundary.
* But these ensure they aren't outright wrong until then.
*/
reln->smgr_cached_nblocks[forknum[i]] = nblocks[i];
}
}
14 static void mdunlinkfork(RelFileNodeBackend rnode,ForkNumber forkNum,bool isRedo)
该函数的功能是将指定relation的物理文件删除。(先截断后移除),本质上是对do_truncate和unlink函数的进一步封装。
注:对于普通的relation(fsm/vm除外),会保留第一个段文件(只执行do_truncate操作,内容为0)
static void
mdunlinkfork(RelFileNodeBackend rnode, ForkNumber forkNum, bool isRedo)
{
char *path;
int ret;
path = relpath(rnode, forkNum);
/*
* Delete or truncate the first segment.
*/
if (isRedo || forkNum != MAIN_FORKNUM || RelFileNodeBackendIsTemp(rnode))
{
if (!RelFileNodeBackendIsTemp(rnode))
{
/* Prevent other backends' fds from holding on to the disk space */
ret = do_truncate(path);
/* Forget any pending sync requests for the first segment */
register_forget_request(rnode, forkNum, 0 /* first seg */ );
}
else
ret = 0;
/* Next unlink the file,unless it was already found to be missing */
if (ret == 0 || errno != ENOENT)
{
ret = unlink(path);
if (ret < 0 && errno != ENOENT)
ereport(WARNING,
(errcode_for_file_access(),
errmsg("could not remove file \"%s\": %m", path)));
}
}
else
{
/* Prevent other backends' fds from holding on to the disk space */
ret = do_truncate(path);
/* Register request to unlink first segment later */
register_unlink_segment(rnode, 0 /* first seg */ );
}
/*
* Delete any additional segments.
*/
if (ret >= 0)
{
char *segpath = (char *) palloc(strlen(path) + 12);
BlockNumber segno;
/*
* Note that because we loop until getting ENOENT,we will correctly
* remove all inactive segments as well as active ones.
*/
for (segno = 1;; segno++)
{
sprintf(segpath, "%s.%u", path, segno);
if (!RelFileNodeBackendIsTemp(rnode))
{
/*
* Prevent other backends' fds from holding on to the disk
* space.
*/
if (do_truncate(segpath) < 0 && errno == ENOENT)
break;
/*
* Forget any pending sync requests for this segment before we
* try to unlink.
*/
register_forget_request(rnode, segno);
}
if (unlink(segpath) < 0)
{
/* ENOENT is expected after the last segment... */
if (errno != ENOENT)
ereport(WARNING,
(errcode_for_file_access(),
errmsg("could not remove file \"%s\": %m", segpath)));
break;
}
}
pfree(segpath);
}
pfree(path);
}
原文地址:https://blog.csdn.net/qq_52668274/article/details/129430775
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。