

大家好!我是只谈技术不剪发的 Tony 老师。今天我们来聊聊 PostgreSQL 的性能优化;数据库优化是一个系统的工程,本文只专注于服务器的参数配置优化。
默认安装时,PostgreSQL 的配置参数通常都偏小,不太适合作为生产服务器使用。所以,安装 PostgreSQL 数据库之后首先需要执行的操作就是对服务器的配置参数进行调整。
查看/设置参数值
我们使用 PostgreSQL 12,服务器的配置参数有 300 多个,运行时的参数值可以使用 SHOW 命令查看:
show server_version;
server_version|
--------------|
12.3 |
show all;
name |setting |description |
-----------------------------------|-----------------------------------------|----------------------------------------------------------------------------------------------------------|
allow_system_table_mods |off |Allows modifications of the structure of system tables. |
application_name |DBeaver 7.0.5 - SQLEditor <Script-13.sql>|Sets the application name to be reported in statistics and logs. |
archive_cleanup_command | |Sets the shell command that will be executed at every restart point. |
...
这些参数的详细信息也可以使用 pg_settings 视图进行查看:
SELECT name, setting, unit, source, sourcefile, sourceline, short_desc
from pg_settings
where name like '%buffers%';
name |setting|unit|source |sourcefile |sourceline|short_desc |
--------------|-------|----|------------------|--------------------------------------|----------|------------------------------------------------------------------|
shared_buffers|16384 |8kB |configuration file|/var/lib/pgsql/12/data/postgresql.conf| 121|Sets the number of shared memory buffers used by the server. |
temp_buffers |1024 |8kB |default | | |Sets the maximum number of temporary buffers used by each session.|
wal_buffers |512 |8kB |override | | |Sets the number of disk-page buffers in shared memory for WAL. |
通过 pg_settings 视图不仅可以查看运行时的参数值,而且可以知道这些值的来源。
这些参数有些可以在服务器运行时进行修改,有些需要重启服务器之后才能生效;不同修改方式的优先级不同,下图列出了所有可能的修改方式:
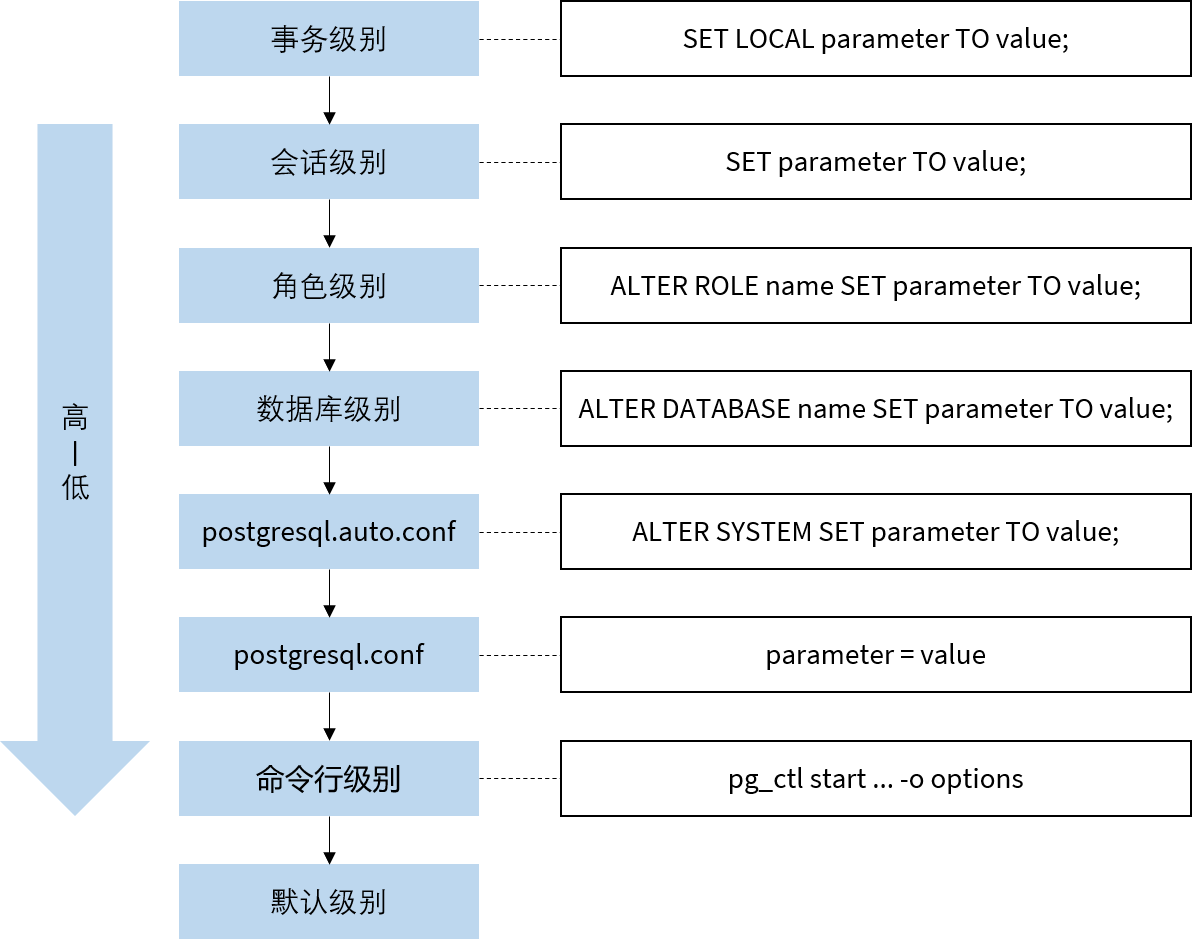
以上设置方式的优先级从高到低;也就是说,在一个在事务内部设置的参数值会覆盖其他任何设置,不过该设置只在当前事务中有效。需要注意的是,并非所有参数都可以支持所有的修改方式,具体可以参考官方文档关于 pg_settings 的说明。
接下来我们介绍几个重要的配置参数。
max_connections
max_connections 决定了客户端的最大并发连接数,默认值通常为 100。如果出现连接数过多,无法连接数据库的错误时,可能需要考虑增加最大连接数。不过,修改该参数还需要考虑对其他参数的影响(尤其是 work_mem);因为它们是基于每个连接设置的值,增加连接数也会导致这些内存使用量的增加。
通常来说,商业服务器至少可以支持几百个连接。如果应用的连接数到大上千或者几千,可以考虑使用连接池技术减少连接的消耗。
修改 max_connections 的方式有两种,修改之后必须重启服务器才能生效:
- 修改配置文件 postgresql.conf;
-
alter system set max_connections = N;,该命令会修改配置文件 postgresql.auto.conf。
对于主从复制中的从节点,必须将该参数的值设置为大于等于主节点上的值;否则,从节点将无法执行查询操作。
shared_buffers
除了操作系统的 I/O 缓存之外,PostgreSQL 还会使用自己的内部缓存。PostgreSQL 共享内存缓冲区由参数 shared_buffers 设置,它决定了 PostgreSQL 能够使用的专用缓存大小。
为确保在所有机器和操作系统上的兼容性,PostgreSQL 默认将该值设置得很小,通常是 128 MB。因此,增加 shared_buffers 的值是提高性能最有效的设置之一。
虽然对于 shared_buffers 没有具体的推荐值,但是可以针对具体的系统计算出一个大概的值。一般来说,对于专用的数据库服务器,shared_buffers 大概可以设置为系统内存的 25%。增加 shared_buffers 的值通常可以提高性能,例如,当整个数据库都可以被加载到缓存中时,可以明显减少磁盘的读取操作。由于 PostgreSQL 还依赖于操作系统的缓存,大于内存 40% 的 shared_buffers 并不会带来性能的提示,反而可能会下降。
虽然增加 shared_buffers 的值可以提高以读为主的系统性能,但是可能影响以写为主的系统性能;因为 shared_buffers 的全部内容必须在写入操作时进行处理。
修改 shared_buffers 的方式有两种,修改之后必须重启服务器才能生效:
- 修改配置文件 postgresql.conf;
-
alter system set shared_buffers = 'xxx';,该命令会修改配置文件 postgresql.auto.conf。
另外,增加 shared_buffers 的值通常也需要相应地增加 max_wal_size 的值,以便延长检查点的时间间隔。
wal_buffers
PostgreSQL 使用预写日志(WAL)确保数据的持久性;与 shared_buffers 作用类似,PostgreSQL 将 WAL 日志写入缓冲并且批量写入磁盘。
默认的 WAL 缓冲大小由 wal_buffers 参数进行设置,初始值为 16MB(shared_buffers 的 1/32)。WAL 缓冲区在每次事务提交时都会写入磁盘,因此过大的值并不会带来显着的性能提升。不过,对于大量并发的写入操作,适当增加该参数的值可以提高系统的性能。
修改 wal_buffers 的方式有两种,修改之后必须重启服务器才能生效:
- 修改配置文件 postgresql.conf;
-
alter system set wal_buffers = 'xxx';,该命令会修改配置文件 postgresql.auto.conf。
effective_cache_size
effective_cache_size 参数为 PostgreSQL 提供了一个可供操作系统和数据库使用的缓存估值(考虑了操作系统自身和其他应用之后)。
该参数只是一个评估值,而不是实际的分配值;它仅用于 PostgreSQL 查询计划器判断索引的代价,越大的值越可能使用索引扫描,否则更可能使用表的顺序扫描。
effective_cache_size 默认值为 4 GB,保守估可以设置为是系统可用内存的 1/2。通常对于专用数据库服务器可以设置为系统总内存的 75%,可以根据特定的服务器工作负载进行调整。如果 effective_cache_size 设置过低,查询计划器可能会忽略某些索引,即使通过索引可以明显增加查询的性能。
通过操作系统的统计信息可以得到一个更好的估计值。对于 UNIX/LINUX 系统,将 free 或者 top 命令结果中的 free 加上 cached;;对于 Windows 系统,查看任务管理器 Performance 页面中的“System Cache”。
修改 effective_cache_size 不需要重启服务器,通过以下方式修改之后执行pg_ctl reload或者SELECT pg_reload_conf();重新加载即可:
- 修改配置文件 postgresql.conf;
-
alter system set effective_cache_size = 'xxx';,该命令会修改配置文件 postgresql.auto.conf。
work_mem
work_mem 参数用于复杂的排序操作,它决定了中间结果(例如哈希表)或者排序操作可以使用的最大内存。
如果设置了合适的 work_mem 值,大部分的排序操作都在内存中执行,而不需要使用磁盘存储临时结果。对于复杂的查询,可能会执行并发的排序或者哈希操作,每个操作都可以最多使用该参数设置的内存。另外,多个会话可能同时执行排序操作。因此,排序占用的总内存可能是 work_mem 的许多倍;work_mem 的值不能设置的过高,因为它可能导致内存使用瓶颈。
该参数的默认值为 4MB,支持从事务级别到命令行参数的各种修改方式。理想的方式是将全局的 work_mem 参数设置为一个较低的值,然后为具体的查询指定更大的值:
SET LOCAL work_mem = '256MB';
SELECT * FROM db ORDER BY LOWER(name);
涉及排序操作的 SQL 子句包括 ORDER BY、DISTINCT 以及排序合并连接(Sort Merge Join)。使用哈希表的操作包括哈希连接(Hash Join)、基于哈希的聚合以及基于哈希的 IN 子查询实现。
maintenance_work_mem
maintenance_work_mem 参数指定了日常维护操作允许占用的最大内存,例如 VACUUM、CREATE INDEX 以及 ALTER TABLE ADD FOREIGN KEY 等操作。
由于一个数据库会话同时只能执行一个维护操作,一般不会存在并发的维护操作;所以将该参数设置的比 work_mem 大很多也不会有问题,更大的维护内存还能够提高数据库清理和数据导入的性能。
唯一需要注意的是,如果启动了 autovacuum,可能会占用 autovacuum_max_workers(默认为 3)倍 work_mem 设置的内存。我们也可以为此设置单独的 autovacuum_work_mem 参数。
maintenance_work_mem 参数的默认值为 64MB,支持从事务级别到命令行参数的各种修改方式。
总结
调整服务器的配置参数通常是我们在安装 PostgreSQL 之后需要进行优化的第一步,本文介绍了如何进行参数的设置以及几个重要参数的作用和调整目标。PostgreSQL 提供了大量可以调整的参数,PGTune 工具给我们提供了一个很好的尝试起点,wiki.postgresql.org列出了最常见的几个参数优化;不过性能优化的关键是对工作负载进行基准测试并且和已知的基线进行比较。
另外,数据库的配置优化并不是优化的全部。例如,编写不当的查询语句可能无法通过调整参数解决性能问题;此时我们需要通过其他方式进行优化,比如利用索引或者修改查询的连接方式等。
如果觉得文章对你有用,请不要白嫖!欢迎关注❤️、评论
原文地址:https://tonydong.blog.csdn.net
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。