
pgsql中的行锁
前言
日常的工作中,对于同一个资源的操作,有时候我们难免要加上锁,以防止在操作中被别的进程给删除或者更改掉了,那么更多还是行级锁,那么我们就来探究下。
用户可见的锁
从系统视图pg_locks中可见
用户可见的锁,用户自己能够主动调用的,可以在pg_locks中看到是否grant的锁。包括regular lock和咨询锁。
regular Lock
regular lock分为表级别和行级别两种。
行级别
通过一些数据库操作自动获得一些行锁,行锁并不阻塞数据查询,只阻塞writes和locker,比如如下操作。
FOR UPDATE
FOR NO KEY UPFATE
FOR SHARE
FOR KEY SHARE
FOR UPDATE
FOR UPDATE锁可以使得SELECT语句获取行级锁,用于更新数据。锁定该行可以防止该行在本次的操作过程中,被其他的事务获取锁或者进行更改删除操作。就是说其他事务的操作会被阻塞直到当前事务结束;同样的,SELECT FOR UPDATE命令会等待直
到前一个事务结束。即尝试 UPDATE、DELETE、SELECT FOR UPDATE、SELECT FOR NO KEY UPDATE、SELECT FOR SHARE 或 SELECT FOR KEY SHARE 的其他事务将被阻塞。反过来,SELECT FOR UPDATE将等待已经在相同行上运行以上这些命令的
并发事务,并且接着锁定并且返回被更新的行(或者没有行,因为行可能已被删除)。不过,在一个REPEATABLE READ或SERIALIZABLE事务中,如果一个要被锁定的行在事务开始后被更改,将会抛出一个错误。
任何在一行上的DELETE命令也会获得FOR UPDATE锁模式,在某些列上修改值的UPDATE也会获得该锁模式。当前UPDATE情况中被考虑的列集合是那些具有能用于外键的唯一索引的列(所以部分索引和表达式索引不被考虑),但是这种要求未来有可能会改变。
FOR NO KEY UPDATE
和FOR UPDATE命令类似,但是对于获取锁的要求更加宽松一些,在同一行中不会阻塞SELECT FOR KEY SHARE命令。同样在UPDATE命令的时候如果没有获取到FOR UPDATE锁的情况下会获取到该锁。
FOR SHARE
行为与FOR NO KEY UPDATE类似,不过它在每个检索到的行上获得一个共享锁而不是排他锁。一个共享锁会阻塞其他事务在这些行上执行UPDATE、DELETE、SELECT FOR UPDATE或者SELECT FOR NO KEY UPDATE,但是它不会阻止它们执行SELECT FOR SHARE或者SELECT FOR KEY SHARE。
FOR KEY SHARE
行为与FOR SHARE类似,不过锁较弱:SELECT FOR UPDATE会被阻塞,但是SELECT FOR NO KEY UPDATE不会被阻塞。一个键共享锁会阻塞其他事务执行修改键值的DELETE或者UPDATE,但不会阻塞其他UPDATE,也不会阻止SELECT FOR NO KEY UPDATE、SELECT FOR SHARE或者SELECT FOR KEY SHARE。

测试下加锁之后的数据可见性
create table test_lock
(
id serial not null,name text not null
);
alter table test_lock
owner to postgres;
create unique index test_lock_id_uindex
on test_lock (id);
INSERT INTO public.test_lock (id,name) VALUES (1,'小明');
INSERT INTO public.test_lock (id,name) VALUES (2,'小白');
加锁测试(FOR UPDATE)
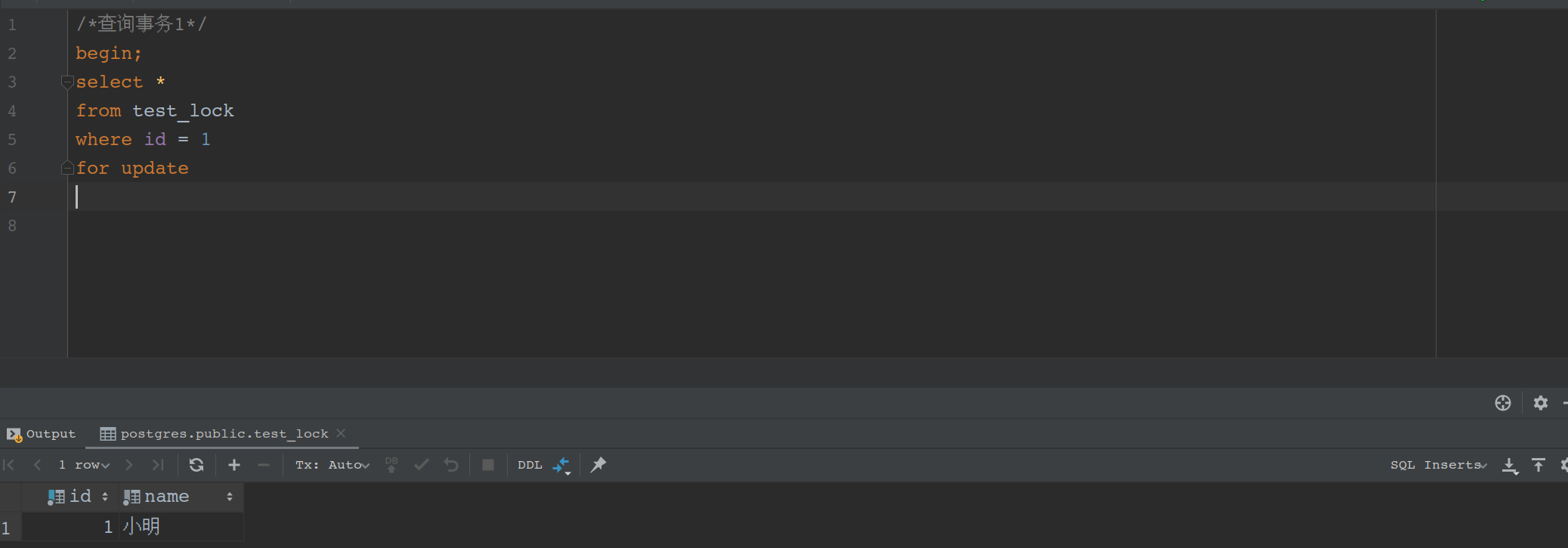
查询1
/*查询事务1*/
begin;
select *
from test_lock
where id = 1
for update
查询2
/*查询事务2*/
begin;
select *
from test_lock
where id = 1
for update
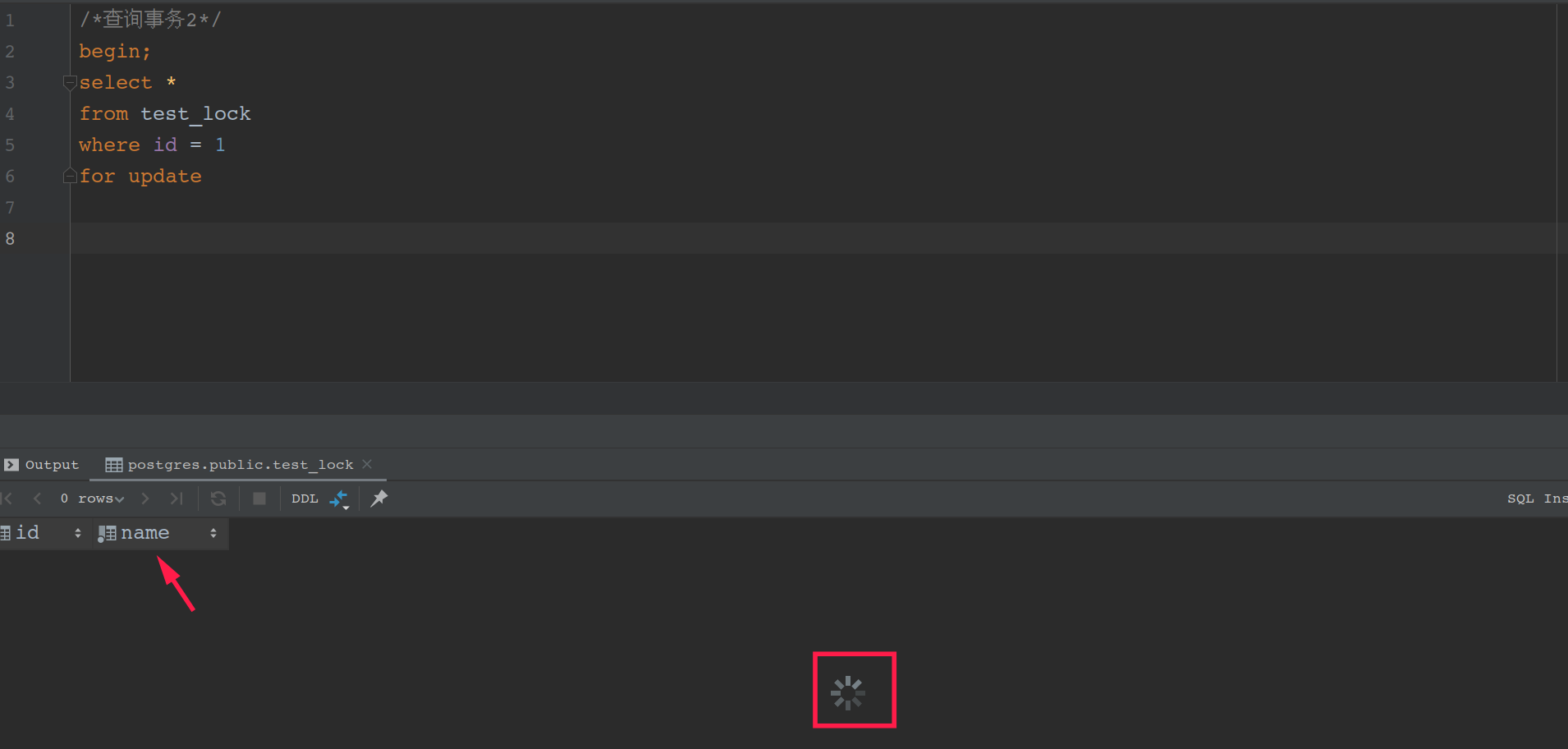
当事务1在查询中锁住资源的时候,事务2就一直查不到数据,等待事务1提交
查询1事务提交
commit
事务2的查询马上结束等待,查询出当前的数据
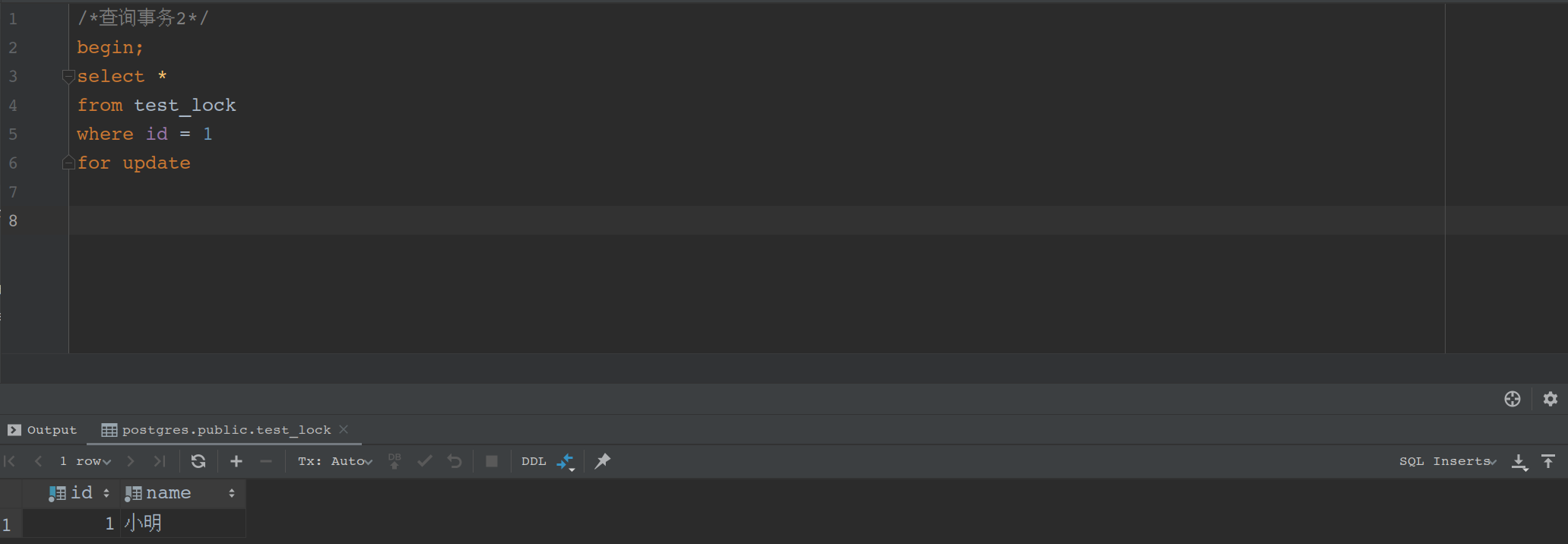
别忘了事务2的commit提交
加锁测试(FOR UPDATE,UPDATE)
UPDATE和DELETE,操作也是带锁的,测试下和FOR UPDATE的阻塞情况
查询1
/*查询事务1*/
begin;
update test_lock set name='mignming' where id=1
查询2
/*查询事务2*/
begin;
select *
from test_lock
where id = 1
for update
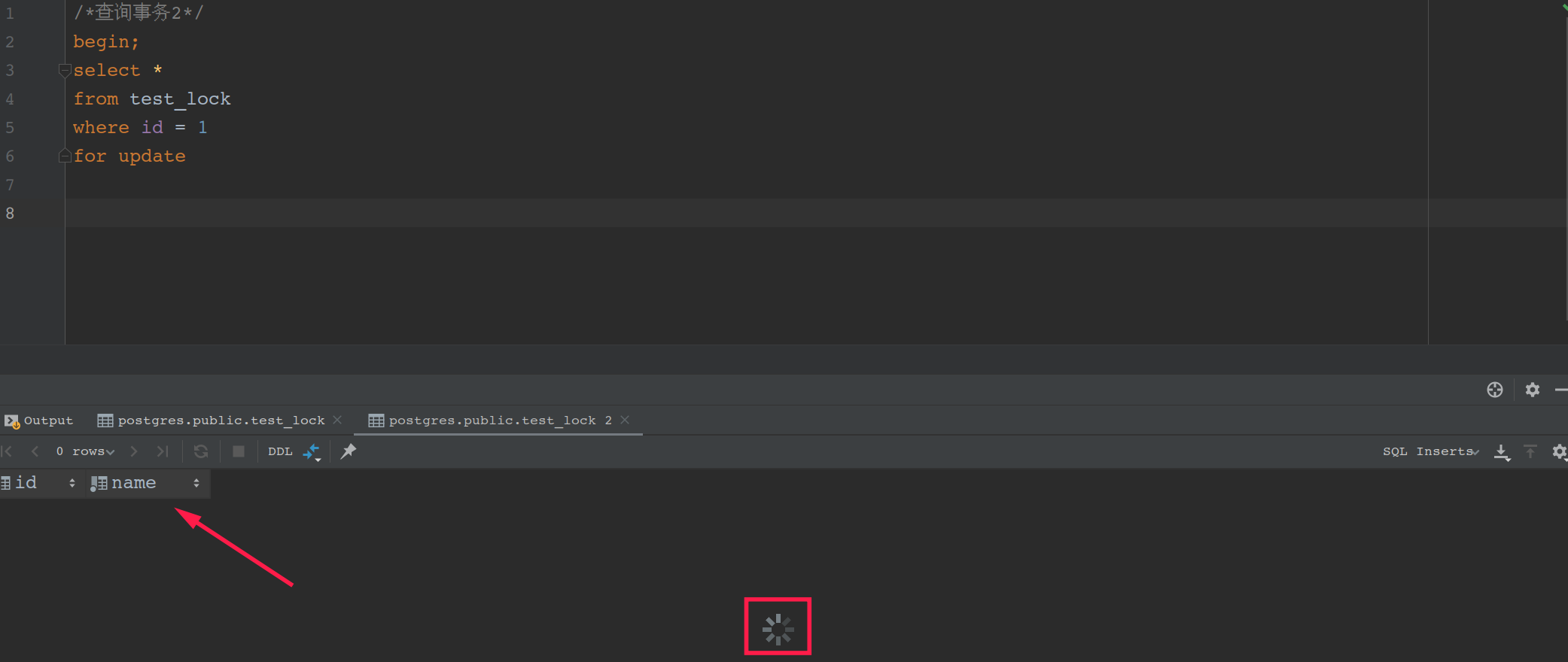
发现SELECT FOR UPDATE被阻塞了
提交查询1,update的事务
commit
然后查询2结束阻塞,获取到了事务1更新的数据
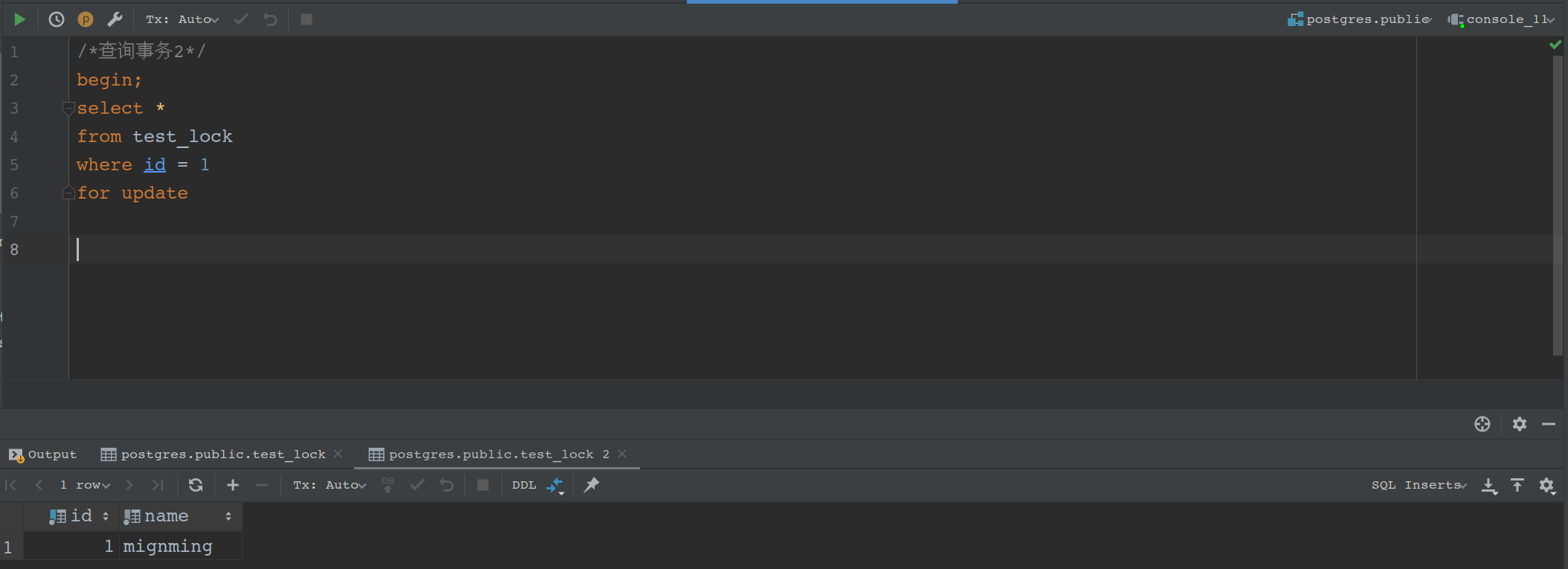
别忘了事务2的commit提交
命令说明
begin;--开启事务
begin transaction;--开启事务
commit;--提交
rollback;--回滚
set lock_timeout=5000;--设置超时时间
需要注意的点
连表查询加锁时,不支持单边连接形式,例如:
select u.*,r.* from db_user u left join db_role r on u.roleid=r.id for update;
支持以下形式,并锁住了两个表中关联的数据:
select u.*,r.* from db_user u,db_role r where u.roleid=r.id for update;
举个栗子
有一个分类表category,有一个文档表document。一个分类对应多个文档,删除分类的时候有一个限制,分类下面必须没有文档才能删除。这时候删除可能出现这样的场景,当删除分类的时候,后面新建了一个文档,两事务并行,根据pgsql默认的事务隔离级别,读已提交。新建文档,通过分类id获取到的分类信息,是进行分类删除之前的信息,也就是查询到这个分类存在。当两个事物一起执行了,有可能出现新建的文档的分类id不存在的情况。那就出现了脏数据了。
如何解决呢?
首先想到的肯定是加锁了。
如果一个资源加锁了,后面的操作必须要等到前面资源操作结束才能获取到资源信息。
这是pgsq文档对读已提交隔离中行锁的查询描述,需要注意的是UPDATE,DELETE也是会锁住资源的
UPDATE、DELETE、SELECT FOR UPDATE和SELECT FOR SHARE命令在搜索目标行时的行为和SELECT一样: 它们将只找到在命令开始时已经被提交的行。 不过,在被找到时,这样的目标行可能已经被其它并发事务更新(或删除或锁住)。在这种情况下, 即将进行的更新将等待第一个更新事务提交或者回滚(如果它还在进行中)。 如果第一个更新事务回滚,那么它的作用将被忽略并且第二个事务可以继续更新最初发现的行。 如果第一个更新事务提交,若该行被第一个更新者删除,则第二个更新事务将忽略该行,否则第二个更新者将试图在该行的已被更新的版本上应用它的操作。该命令的搜索条件(WHERE子句)将被重新计算来看该行被更新的版本是否仍然符合搜索条件。如果符合,则第二个更新者使用该行的已更新版本继续其操作。在SELECT FOR UPDATE和SELECT FOR SHARE的情况下,这意味着把该行的已更新版本锁住并返回给客户端。
所以,解决方法就是在,添加文档的时候对分类id加锁,这样删除分类的锁就和下面查询的锁互斥了,两者必须有个先后执行的顺序,会避免脏数据的产生。
WITH lock_document_categories_cte AS (
SELECT id
FROM document_categories
WHERE id = ${categoryId}
AND enterprise_id = ${enterpriseId}
FOR UPDATE
),lock_document_directories_cte AS (
SELECT id
FROM document_directories
WHERE id = ${directoryId}
AND enterprise_id = ${enterpriseId}
FOR UPDATE
)
INSERT INTO documents (
enterprise_id,directory_id,category_id,code,name,author_id
) VALUES (
${enterpriseId},(SELECT * FROM lock_document_directories_cte),(SELECT * FROM lock_document_categories_cte),${code},${name},${authorId}
)
RETURNING id
通过lock_document_categories_cte中的FOR UPDATE,锁住资源,这样就和delete中的锁互斥了。
总结
UPDATE、DELETE、SELECT FOR UPDATE和SELECT FOR SHARE。都会对资源加锁。当加锁的资源在被执行的时候。后面的操作,要等前面资源操作执行完成才能进行操作, 即将进行的更新将等待第一个更新事务提交或者回滚(如果它还在进行中)。 如果第一个更新事务回滚,那么它的作用将被忽略并且第二个事务可以继续更新最初发现的行。 如果第一个更新事务提交,若该行被第一个更新者删除,则第二个更新事务将忽略该行,否则第二个更新者将试图在该行的已被更新的版本上应用它的操作。该命令的搜索条件(WHERE子句)将被重新计算来看该行被更新的版本是否仍然符合搜索条件。如果符合,则第二个更新者使用该行的已更新版本继续其操作。在SELECT FOR UPDATE和SELECT FOR SHARE的情况下,这意味着把该行的已更新版本锁住并返回给客户端。
参考
【Postgresql锁机制(表锁和行锁)】https://blog.csdn.net/turbo_zone/article/details/84036511
【postgresql行级锁for update测试】https://blog.csdn.net/shuoyu816/article/details/80086810
【PostgreSQL 锁解密 】https://www.oschina.net/translate/postgresql-locking-revealed
【显式锁定】http://postgres.cn/docs/11/explicit-locking.html
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。