

#Postgersql
介绍
原始英文文档:PostgreSQL: Documentation: 15: VACUUM
对应的中文文档:VACUUM (postgres.cn),基本都是机翻建议对照学习,不会迷茫。
VACUUM是什么?
官方只用了一句话介绍VACUUM:
garbage-collect and optionally analyze a database
VACUUM可以认为手动触发Postgresql 垃圾回收的原始命令,需要注意查阅的文档版本为:Postgresql 14。
比VACUUM更为重要的是AUTO_VACUUM,放到本文最后讨论,当然VACUUM是底层实现。
为什么叫 VACUUM?
介绍枯燥的文档内容之前,个人先猜测一波起名垃圾回收为VACUUM的原因:
- 由于VACUUM机制正常参数下只会把死元组的空间重用,不会把申请的空间归还给操作系统,所以类似抽真空的感觉。
- 如果是VACUUM FULL,此时会把空间重用并且把空间还给操作系统,这时候的抽真空又像是把一块空间整个“剥离”出去。
当然以上纯属个人瞎扯,也有可能是这个名字对于开发者来说会觉得很COOL。
相关语法
VACUUM [ ( _`option`_ [, ...] ) ] [ _`table_and_columns`_ [, ...] ]
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ ANALYZE ] [ _`table_and_columns`_ [, ...] ]
where _`option`_ can be one of:
FULL [ _`boolean`_ ]
FREEZE [ _`boolean`_ ]
VERBOSE [ _`boolean`_ ]
ANALYZE [ _`boolean`_ ]
disABLE_PAGE_SKIPPING [ _`boolean`_ ]
SKIP_LOCKED [ _`boolean`_ ]
INDEX_CLEANUP { AUTO | ON | OFF }
PROCESS_TOAST [ _`boolean`_ ]
TruncATE [ _`boolean`_ ]
ParaLLEL _`integer`_
and _`table_and_columns`_ is:
_`table_name`_ [ ( _`column_name`_ [, ...] ) ]注意这种圆括号的用法是官方推荐的,如果要修改参数,就需要使用圆括号,否则会报错无法通过。
作用
既然是回收垃圾进程那么要回收什么东西? 其实很简单,清理死元组,这里根据文档一一分析。
清理死元组
VACUUMreclaims storage occupied by dead tuples。
这里说Postgresql回收的是死元组,元组是Postgresql数据结构的基本组成单位,比较像MysqL的数据页。
那么死元组是怎么来的呢?下面就有一句很关键的话:
tuples that are deleted or obsoleted by an update are not physically removed from their table
好家伙,假更新和假删除是吧,也就是说删除是在元组进行标记,而更新可以认为是先标记删除然后“插入”,是不是觉得非常熟悉?
接下来一句话也比较关键:
they remain present until a
VACUUMis done
VACUUM执行完垃圾回收之后才会把死元组进行回收。这时候垃圾回收的执行频率和垃圾回收执行效果就非常关键了,这里接着往下看:
Without a
table_and_columnslist,VACUUMprocesses every table and materialized view in the current database that the current user has permission to vacuum. With a list,VACUUMprocesses only those table(s).
在没有table_and_columns列表的情况下,VACUUM会处理当前用户具有清理权限的数据库中的每张表和物化视图。(但是实际用的时候大部分情况需要超级用户,或者具备较高权限的系统管理员,一般用户是没有这个权限的)
table_and_columns是啥? 指的是垃圾回收可以指定表以及列,如果不想对所有表做清理,在手动清理的时候可以进行配置。
此外Postgresql针对垃圾回收开发了另一个子命令 VACUUM ANALYZE, 可以通过此命令对于运行的 Postgresql 实例进行分析,也是实现自动垃圾回收的关键组件之一。
这里不过多讨论 ANALYZE ,我们可以直接看看效果: 命令:
VACUUM VERBOSE ANALYZE(VERBOSE 表示显示分析进度和详细信息) 0 pages are entirely empty. cpu: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.INFO: vacuuming "pg_toast.pg_toast_88998" INFO: index "pg_toast_88998_index" Now contains 0 row versions in 1 pages DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.INFO: "pg_toast_88998": found 0 removable, 0 nonremovable row versions in 0 out of 0 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 3643386
There were 0 unused item identifiers.Skipped 0 pages due to buffer pins, 0 frozen pages.0 pages are entirely empty.INFO: analyzing "public.xxxxxx" INFO: "xxxxxx": scanned 837 of 837 pages, containing 11930 live rows and 0 dead rows; 11930 rows in sample, 11930 estimated total rowsOK 查询时间: 11.3s
收缩
收缩是设计本身附带的好处,这里简单介绍不作为研究重点。收缩更偏向于 VACUUM FULL 这个指令,因为涉及磁盘IO操作,在清理掉过期索引的同时,为接下来的数据流入预分配新的空间进行存储,清理掉过期索引可以实现死元组空间复用,减少磁盘空间的占用浪费。
我们简单并且快速了解 VACUUM 的作用,接着继续根据文档了解更多细节。
参数介绍
个人根据官方文档摘录了部分参数重要的说明同时做了一张表,这张表不必记忆,只需要简单了解然后实战当中进行查阅即可。
Option |
english description |
中文解释 |
|---|---|---|
FULL |
Selects “full” vacuum, which can reclaim more space, but takes much longer and exclusively locks the table |
可以回收更多空间,但是会锁表并且回收时间会变长 |
PROCESS_TOAST |
Specifies that VACUUM should attempt to process the corresponding TOAST table for each relation, if one exists. |
|
INDEX_CLEANUP |
|
|
FREEZE |
Selects aggressive “freezing” of tuples. Specifying FREEZE is equivalent to performing VACUUM with the vacuum_freeze_min_age and vacuum_freeze_table_age parameters set to zero
option is redundant when |
此选项表示会激进冻结元组,指定此参数相当于执行 |
ANALYZE |
Updates statistics used by the planner to determine the most efficient way to execute a query. |
使用此参数可以立即刷新分析器的分析结果,对于某些场景的调优很有帮助。 |
VERBOSE |
Prints a detailed vacuum activity report for each table. |
|
disABLE_PAGE_SKIPPING |
||
SKIP_LOCKED |
Specifies that should not wait for any conflicting locks to be released when beginning work on a relation: if a relation cannot be locked immediately without waiting, the relation is skipped Also, while ordinarily processes all partitions of specified partitioned tables, this option will cause to skip all partitions if there is a conflicting lock on the partitioned table.VACUUMVACUUMVACUUM ANALYZEVACUUMVACUUM |
指定在开始处理关系时不应等待释放任何冲突锁。如果无法在不等待的情况下立即锁定关系,则跳过该关系。 虽然通常会处理指定分区表的所有分区,但是如果分区表上有冲突的锁,这个选项会导致跳过所有分区。 |
TruncATE |
||
ParaLLEL(13版本之后生效) |
Perform index vacuum and index cleanup phases of VACUUM in parallel using integer background workers (for the details of each vacuum phase, please refer to Table 28.39) vacuum which is limited by the number of workers specified with ParaLLEL option if any which is further limited by max_parallel_maintenance_workers An index can participate in parallel vacuum if and only if the size of the index is more than min_parallel_index_scan_size. Only one worker can be used per index. These behaviors might change in a future release. This option can't be used with the FULL option. |
除了上面的参数之外,接着介绍一些无关紧要的参数:
- boolean:可以是 true、1,选项如果不做指定默认为 true。
- integer:ParaLLEL 指定并行处理器的数量,必须是非负整数。(Postgresql 13 开始生效)
- table_name:支持指定表的垃圾回收。
- column_name:支持指定列的垃圾回收。
ParaLLEL
这里特意拿出来说一下,这个参数官方在Postgresql 13版本才加入,个人感觉是受到MysqL的“刺激”加入的,作用是指定垃圾回收线程的并发数,用户可以手动指定非零值,当然这个值不是自由指定的,官方存在对应的“最大值”限制胡乱传参。
如果参数不存在或者不生效,可以查询一下当前的Postgresql版本。
select version()如果想了解不同的线程并发数对于实际应用的影响对比,可以看看这篇(英文)文章的参数实践介绍:
Parallelism comes to VACUUM - 2ndQuadrant | PostgreSQL
个人挑选了相关结论部分:
I’ve evaluated the performance of parallel vacuum on my laptop (Core i7 2.6GHz, 16GB RAM, 512GB SSD). The table size is 6GB and has eight 3GB indexes. The total relation is 30GB, which doesn’t fit the machine RAM. For each evaluation, I made several percent of the table dirty evenly after vacuuming, then performed vacuum while changing the parallel degree. The graph below shows the vacuum execution time. 我已经评估了笔记本电脑(Core i7 2.6GHz,16GB RAM,512GB SSD)上的(多cpu)并行vacuum的性能。Table 大小为 6GB,有八个 3GB Index。Related为 30GB,不适合机器 RAM。对于每次评估,我在垃圾回收后均匀地制造百分之几的脏元组(类比脏数据页),然后在改变并行度的同时进行vacuum。下图显示了vacuum执行时间。

Result: In all evaluations the execution time of the index vacuum accounted for more than 95% of the total execution time. 显然如果设置合适的cpu并行数量,可以大幅度的减少垃圾回收的执行时间。减小Postgresql抖动情况出现。
FREEZE
在文档中提到了FREEZE参数,说实话不知道官方文档在说啥,属于个人了解目前还不够深入,先翻译放着留个坑,有需要实战或者实验的时候再深入研究。
Translation: vacuum_freeze_min_age(VACUUM 冻结最小年龄): Specifies the cutoff age (in transactions) that VACUUM should use to decide whether to freeze row versions while scanning a table. The default is 50 million transactions 指定VACUUM用来决定是否在扫描表时冻结行版本的截止年龄(以事务为单位)。默认值是5000万个事务。
vacuum_freeze_table_age(触发冻结年龄):VACUUM performs an aggressive scan if the table's pg_class.relfrozenxid field has reached the age specified by this setting. The default is 150 million transactions
如果表的pg_class.relfrozenxid字段达到这个设置所指定的年龄,VACUUM会执行积极的扫描。默认值是1.5亿个记录。
细节
VACCUM 清理阶段介绍
英文文档描述
Phase |
Description |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
中文文档对应的描述,建议凑合着看:
阶段 |
描述 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
无FULL条件回收
Plain
VACUUM(withoutFULL) simply reclaims space and makes it available for re-use, This form of the command can operate in parallel with normal reading and writing of the table, as an exclusive lock is not obtained
通常情况下没有FULL参数的回收,仅仅把那些标记为死元组的空间进行复用。注意整个垃圾回收的操作是没有任何锁操作的,所以可以和用户线程 并行,这就意味着遇到紧急问题可以基本没有副作用的快速对于死元组过多的表清理。
个人补充:虽然官方说这个回收很强并且基本可以无副作用运行,但是依然不建议对整个库这样干,应当先对于当前Postgresql的数据各个表的健康状况分析然后定位对应的表和列进行清理,其次是VACUUM FULL要给表加独占锁,代价很大不能在负载高的时候手动调用。结论:不建议或者禁止对于全库做 VACUUM 和 VACUUM FULL,哪怕官方解释可以和用户进程并行。
无FULL条件回收会导致这些额外的空间不能归还给操作系统重新分配,也就是说空间还是被占用了,只不过里面的空间等待重用而已。
extra space is not returned to the operating system (in most cases);
官方把这种回收方式叫做 parallel vacuum。
应该如何禁用?
要禁用Vacuum功能可以使用ParaLLEL选项并将并行线程数指定为零。具体可以参考下面的写法,这样就不会产生任何工作器进垃圾回收动作。
VACUUM(ParaLLEL 0)当然没什么人吃饱了没事干去捯饬这东西,忘掉这个用法即可。
有FULL条件回收
其实大致区别也可以猜出来,VACUUM FULL会将表的整个内容重写到一个新的磁盘文件中,但是因为存在物理磁盘IO所以开销比较大,并且清理过程需要加一个表级的排他锁,此时其他用户线程无法进行读写。
而与之相对的VACUUM FULL的好处是不包含额外的空间,这使得没有被使用的空间被还给操作系统。
注意事项
- 执行垃圾回收的操作的用户必须拥有相关表的权限。
- VACUUM 只允许非事务执行。
- 对具有GIN索引的表,
VACUUM(任何形式)也会通过将待处理索引项移动到主要GIN索引结构中的合适位置来完成任何待处理的索引插入。 - 建议经常清理生产数据库(至少每晚在系统低活跃量的时候执行一次),以保证移除失效的行。(比较套路的方案是定时任务,这里就不过多讨论了)
-
日常使用时,不推荐
FULL选项,但在特殊情况时它会有用。举个例子是当你删除或者更新了一个表中的绝大部分行时,如果你希望在物理上收缩表以减少磁盘空间占用并且允许更快的表扫描,则该选项是比较合适的。 -
ParaLLEL选项控制并行启动的垃圾回收线程数量,如果此选项与ANALYZE选项一起指定,则不会影响ANALYZE。 -
VACUUM会导致I/O流量的大幅度增加,这可能导致数据库其他进程活动受到影响。(涉及底层数据结构的变动)。 - 建议使用基于成本的VACUUM延迟特性,这一个点放到下文补充说明。
- 对于并行清理,建议按照上述讨论设置为cpu的核心数量,此外不建议并行数量超过cpu核心数量。
- Postgresql包括了“autovacuum”守护进程,它可以自动垃圾回收来实现定期维护表。但是注意垃圾回收进程的优先级很低,只在必要的时候出来工作,这和很多高级编程语言有相似之处。
- 每个运行VACUUM但没有FULL选项的后端将在pg_stat_progress_vacuum视图中报告其进度。运行VACUUM FULL的后端将在pg_stat_progress_cluster视图中报告它们的进度。
补充:如果线上的垃圾自动回收无法满足数据库业务增长要求,需要手动调整自动VACUUM参数。
补充
基于成本的VACUUM延迟
During the execution of VACUUM and ANALYZE commands, the system maintains an internal counter that keeps track of the estimated cost of the varIoUs I/O operations that are performed.
The intent of this feature is to allow administrators to reduce the I/O impact of these commands on concurrent database activity.
This feature is disabled by default for manually issued commands. To enable it, set the variable to a nonzero value .VACUUM``vacuum_cost_delay
在执行VACUUM和ANALYZE命令期间,系统维护一个内部计数器,用于跟踪所执行的各种 I/O 操作的估计成本。此功能的目的是允许管理员减少这些命令对并发数据库活动的 I/O 影响。默认情况下,对于手动发出的命令,此功能处于禁用状态,默认情况下,对于手动发出的命令,此功能处于禁用状态.
vacuum_cost_delay (floating point) The amount of time that the process will sleep when the cost limit has been exceeded.
当超过成本限制时,进程将休眠的时间量。(默认值是零)
vacuum_cost_page_hit (integer) The estimated cost for vacuuming a buffer found in the shared buffer cache.
对共享缓冲区缓存中发现的缓冲区进行vacuuming的估计成本。
vacuum_cost_page_miss (integer) The estimated cost for vacuuming a buffer that has to be read from disk.
对一个必须从磁盘上读取到缓冲区进行vacuuming的预估成本
vacuum_cost_page_dirty (integer) The estimated cost charged when vacuum modifies a block that was prevIoUsly clean.
vacuum_cost_limit (integer) The accumulated cost that will cause the vacuuming process to sleep. The default value is 200.
默认为200,指的是导致VACUUM休眠的累计成本。
上面这些内容都可以在postgresql.conf文件中找到:
# - Cost-Based Vacuum Delay -
#vacuum_cost_delay = 0 # 0-100 milliseconds (0 disables)
#vacuum_cost_page_hit = 1 # 0-10000 credits
#vacuum_cost_page_miss = 2 # 0-10000 credits
#vacuum_cost_page_dirty = 20 # 0-10000 credits
#vacuum_cost_limit = 200 # 1-10000 creditspg_stat_all_tables(重要)
简单来讲这个表存储了当前所有表的“健康状态”,不过比较疑惑的是官方没有在VACUUM文档页面引用这个表的相关内容,个人搜集一些文章才得知这个强的离谱的表,真的是非常坑。
pg_stat_all_tables 表展示了当前系统内所有数据表的健康状态,通过此表可以检查当前某个表被索引扫描次数,插入记录条数,被删除记录条数,更新记录条数等,是一个非常用助于线上问题排查的表(奈何藏得不起眼而且层级也藏得比较深)。
SELECT
relname 表名,
seq_scan 全表扫描次数,
seq_tup_read 全表扫描记录数,
idx_scan 索引扫描次数,
idx_tup_fetch 索引扫描记录数,
n_tup_ins 插入的条数,
n_tup_upd 更新的条数,
n_tup_del 删除的条数,
n_tup_hot_upd 热更新条数,
n_live_tup 活动元组估计数,
n_dead_tup 死亡元组估计数,
last_vacuum 最后一次手动清理时间,
last_autovacuum 最后一次自动清理时间,
last_analyze 最后一次手动分析时间,
last_autoanalyze 最后一次自动分析时间,
vacuum_count 手动清理的次数,
autovacuum_count 自动清理的次数,
analyze_count 手动分析此表的次数,
autoanalyze_count 自动分析此表的次数,
( CASE WHEN n_live_tup > 0 THEN n_dead_tup :: float8 / n_live_tup :: float8 ELSE 0 END ) :: NUMERIC ( 12, 2 ) AS "死/活元组的比例"
FROM
pg_stat_all_tables
WHERE
schemaname = 'public'
ORDER BY n_dead_tup::float8 DESC;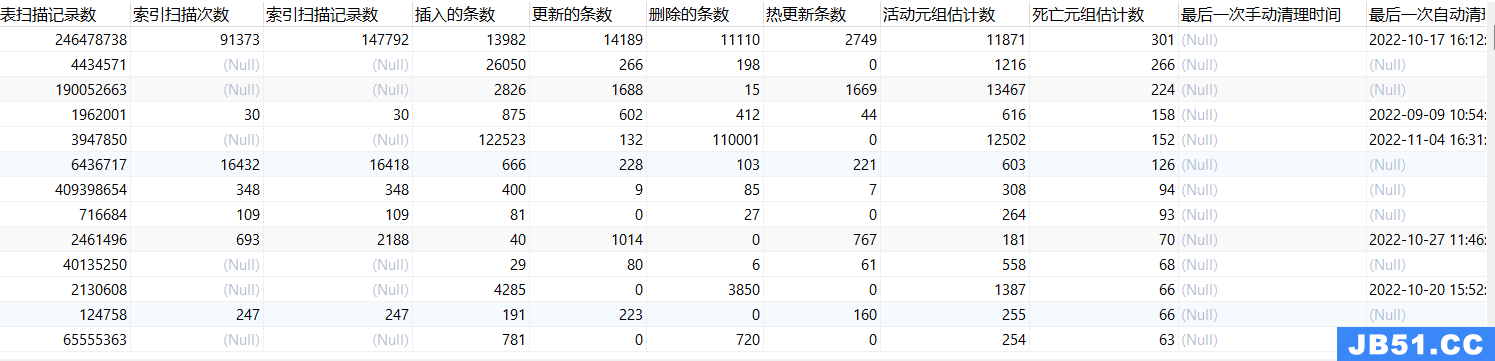
pg_stat_progress_cluster
Progress for
VACUUM FULLcommands is reported viapg_stat_progress_clusterbecause bothVACUUM FULLandCLUSTERrewrite the table
VACUUM FULL命令的进度是通过pg_stat_progress_cluster报告的,因为VACUUM FULL和CLUSTER命令都会重写(这张)表。
所以我们可以通过pg_stat_progress_cluster表查看当前的垃圾回收进度报告。如果我们在执行垃圾回收的时候开启日志参数,也是相当于查询这张表的相关数据。
具体参数这里就不一个个翻译了,对于开发人员来说实战的时候对这个表查一下数据长什么样基本就清楚是干啥的,印象也会更深(没错我就是懒)。
Table 28.40. pg_stat_progress_vacuum View
对应原文链接:PostgreSQL: Documentation: 15: 28.4. Progress Reporting
| Column TypeDescription |
| ------------------------------------------------------------ |
| pid integerProcess ID of backend. |
| datid oidOID of the database to which this backend is connected. |
| datname nameName of the database to which this backend is connected. |
| relid oidOID of the table being vacuumed. |
| phase textCurrent processing phase of vacuum. See Table 28.41. |
| heap_blks_total bigintTotal number of heap blocks in the table. This number is reported as of the beginning of the scan; blocks added later will not be (and need not be) visited by this VACUUM. |
| heap_blks_scanned bigintNumber of heap blocks scanned. Because the visibility map is used to optimize scans, some blocks will be skipped without inspection; skipped blocks are included in this total, so that this number will eventually become equal to heap_blks_total when the vacuum is complete. This counter only advances when the phase is scanning heap. |
| heap_blks_vacuumed bigintNumber of heap blocks vacuumed. Unless the table has no indexes, this counter only advances when the phase is vacuuming heap. Blocks that contain no dead tuples are skipped, so the counter may sometimes skip forward in large increments. |
| index_vacuum_count bigintNumber of completed index vacuum cycles. |
| max_dead_tuples bigintNumber of dead tuples that we can store before needing to perform an index vacuum cycle, based on maintenance_work_mem. |
| num_dead_tuples bigintNumber of dead tuples collected since the last index vacuum cycle. |
Autovacuum(重要)
这里中英文档差距挺大的,建议看英文原版链接。理解自动垃圾回收的一些特点是有必要的,但是个人不太理解为什么这个东西在文档里面被藏到了一个层级目录比较深的角落里面。
确实是角落,被放到了 Routine Vacuuming 最后一个小节简单提了一下。也许是不想透露过多细节让阅读人员难以理解?
本文也根据PostgreSQL: Documentation: 14: 25.1. Routine Vacuuming接进行简单翻译和理解,会跳过一些内容,抽取关键部分介绍:
Postgresql has an optional but highly recommended feature called autovacuum, whose purpose is to automate the execution of VACUUM and ANALYZE commands.
Postgresql强烈推荐开启可选功能autovacuum(其实是默认开启的),他的底层工作原理是定期执行 VACUUM 和 (VACUUM)ANALYZE 对于当前数据库实例的情况进行分析。
The “autovacuum daemon” actually consists of multiple processes. There is a persistent daemon process, called the autovacuum launcher, which is in charge of starting autovacuum worker processes for all databases.
autovacuum daemon "实际上由多个进程组成。内部实际是持久的守护进程,叫做autovacuum launcher,它负责为所有数据库启动autovacuum工作进程。
这里有点像是线程池产生线程分配给请求者使用的思路。
Each worker process will check each table within its database and execute and/or as needed. log_autovacuum_min_duration can be set to monitor autovacuum workers
activity.autovacuum_naptimeautovacuum_max_workersVACUUMANALYZE
每个工作进程将检查其数据库中的每个表并根据需要执行或者不执行。可以设置log_autovacuum_min_duration来监控autovacuum工作者的活动。
PS:最后的参数部分在官方文档模式是有markdown格式的BUG,这里不纠结,不十分影响阅读。
If several large tables all become eligible for vacuuming in a short amount of time, all autovacuum. Note that the number of running workers does not count towards max_connections or superuser_reserved_connections limits.
如果有好几个大表在很短的时间内都有被自动垃圾回收选中,那么很可能导致自动垃圾回收的工作进度被拉长。
此外注意因为Worker线程的数量是有限的,所以对这些大表做清理的时候可能会导致其他的表垃圾无法被及时回收。
需要注意正在运行的worker的数量不计入max_connections or superuser_reserved_connections限制。
Tables whose relfrozenxid value is more than autovacuum_freeze_max_age transactions old are always vacuumed, Otherwise, if the number of tuples obsoleted since the last VACUUM exceeds the “vacuum threshold”, the table is vacuumed.
这里实际解释可以被拆分为两个点:
- relfrozenxid值超过autovacuum_freeze_max_age ,存在旧事务(记录)的表总是被VACUUM。
- 如果自上一次VACUUM以来,淘汰的元组数量超过了 "vacuum threshold" 设置的阈值,则表将被执行VACUUM。
根据这两个点,可以关联出两个计算公式:
垃圾回收阈值计算公式
下面讨论阈值的计算公式。
The vacuum threshold is defined as:
vacuum threshold = vacuum base threshold + vacuum scale factor * number of tuples
清理阈值 = 清理基本阈值 + 清理缩放系数 * 元组数
参数解释:
threshold(阈值):autovacuum_vacuum_threshold
vacuum scale factor(vacuum 比例系数):autovacuum_vacuum_scale_factor
number of tuples:元组(翻译叫图元,个人比较接受元组这个翻译)数量。关联变量pg_class``reltuples
如果自上一次VACUUM以来,淘汰的元组数量超过了 "vacuum threshold" 设置的阈值,则表将被执行VACUUM。
同样有对应的计算公式
vacuum insert threshold = vacuum base insert threshold + vacuum insert scale factor * number of tuples清理插入阈值 = 清理基础插入阈值 + 清理插入缩放系数 * 元组数
autovacuum_vacuum_insert_threshold:基本阈值
autovacuum_vacuum_insert_scale_factor:比例系数
这样的参数考虑是允许部分的表被标识为 all visible,并且也可以允许元组被冻结,可以减小后续清理的工作需要。
中间部分省略大量内容,太长不看。
分析阈值计算
For analyze, a similar condition is used: the threshold, defined as:
对于垃圾回收的分析,Postgresql 也提供对应的计算公式
analyze threshold = analyze base threshold + analyze scale factor * number of tuples分析阈值 = 分析基本阈值 + 分析缩放系数 * 元组数
is compared to the total number of tuples inserted, updated, or deleted since the last .
ANALYZE
比较的依据是最后一次执行VACUUM之后插入、更新或删除的元组总数。
其他注意事项
Partitioned tables are not processed by autovacuum.
分区表不会被自动 VACUUM 处理。如果需要分区表清理,需要手动分析和手动清理。
Temporary tables cannot be accessed by autovacuum. Therefore, appropriate vacuum and analyze operations should be performed via session sql commands.
临时表不能被自动 vacuum 处理,vacuum 和 analyze 操作应该使用Session sql 命令进行处理,这里说的是直接使用非事务的会话操作。
When multiple workers are running, the autovacuum cost delay parameters (see Section 20.4.4) are “balanced” among all the running workers, so that the total I/O impact on the system is the same regardless of the number of workers actually running. However, any workers processing tables whose per-table
autovacuum_vacuum_cost_delayorautovacuum_vacuum_cost_limitstorage parameters have been set are not considered in the balancing algorithm.
这段话意味着如果存在并发Worker工作器并行工作,因为内部使用相同的参数,所以内部会自动进行“重平衡”,所以无论Worker线程数量多,对系统的总I/O影响是相同的。
如果在配置文件中对于某个被清理表设置了autovacuum_vacuum_cost_delay 或者 autovacuum_vacuum_cost_limit参数,那么自动VACUUM的重平衡的机制不会涉及这些存在配置的表。
If a process attempts to acquire a lock that conflicts with the lock held by autovacuum, lock acquisition will interrupt the autovacuum.
此外如果一个进程试图获取与autovacuum持有的锁相冲突的锁,autovacuum 将会自动中断自己获取的锁。
下面这一段内容比较重要,建议反复阅读,尤其是加锁的一段内容。
Autovacuum workers generally don't block other commands The default thresholds and scale factors are taken from postgresql.conf, ; see Storage Parameters for more information, If a setting has been changed via a table's storage parameters, that value is used when processing that table; otherwise the global settings are used. See Section 20.10 for more details on the global settings.
自动垃圾回收线程不会干扰其他用户线程的正常工作,默认的阈值和比例因子取自postgresql.conf,更多信息可以查看 Storage Parameters 。如果通过表的存储参数改变了某个设置,那么在处理该表时将使用该值;否则会使用默认的设置,全局设计可以阅读: Section 20.10
最后关于锁冲突的相关概念可以阅读下面的链接:PostgreSQL: Documentation: 14: 13.3. Explicit Locking
Requested Lock Mode |
Current Lock Mode |
|||
|---|---|---|---|---|
FOR KEY SHARE |
FOR SHARE |
FOR NO KEY UPDATE |
FOR UPDATE |
|
FOR KEY SHARE |
X |
|||
FOR SHARE |
X |
X |
||
FOR NO KEY UPDATE |
X |
X |
X |
|
FOR UPDATE |
X |
X |
X |
X |
实践
VACUUM (VERBOSE, ANALYZE) onek;当然不止这一些内容,后续会单独写一篇短文介绍利用垃圾回收和分析器去解决一些生产问题,这里暂时留坑.
小结
理解 VACUUM 机制对于排查大数据量批量修改、插入、删除数据等问题至关重要,Postgresql 在数据清理这一块模仿了现代编程语言比较容易理解的垃圾回收机制(至少浅层上只要稍加学习可以理解),所以这部分文档个人以目前认知水平还能接受的内容给“意译”了。
仔细观察这部分原文会发现涉及了大量的参数配置,这些配置基本上是DBA或者对于Postgresql底层十分感兴趣才需要去探究的,当然有可能在某些特殊业务场景下需要调优参数,所以这里也算是打个预防针等问题来临的时候有个思路索引来排查问题。
个人英文水平抠脚,很多术语按照自己的认知进行翻译了,如果有错误欢迎指出。如果有什么地方不懂欢迎一起讨论,因为我也不是很懂,哈哈,资料实在是太少了,老外讨论这玩意似乎也不多,难顶。
不知道为啥Postgresql这几年就像是坐火箭一样更新换代,但是国内用户问题反馈少的可怜,不过也算是好事情,比隔壁MysqL原地踏步强太多。
写在最后
Postgresql的学习一直是比较头痛的东西,参考资料和书籍都比较老,大多数时候只能以官方文档学习和“猜测”为主,遇到一些项目问题不好排查。
Postgresql十分优秀,也十分受到大厂欢迎,然而实际上“维护成本”非常高,所以更建议多研究研究MysqL,虽然它在国外甚至连MysqL开发者离职后也称“越做越垃”。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。

