

文章目录
一、泛化误差
泛化能力:泛化能力是指由学习方法学习到的模型对未知数据的预测能力,是学习方法本质上重要的性质。
泛化误差:如果学习的模型是
f
^
\hat{f}
f^,那么这个模型对未知数据预测的误差就是泛化误差。
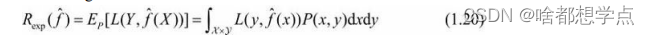
泛化误差越小,方法更有效,实际上,泛化误差就是学习到的模型的期望风险。
二、泛化误差上界
- 概念:学习方法的泛化能力分析往往是通过研究泛化误差的概率上界进行的;
- 性质:
- 它是样本容量的函数,当样本容量增加时,泛化上界趋于0;
- 他是假设空间容量的函数,假设空间容量越大,模型就越难学,泛化误差上界就越大。
定理:对二分类问题,当假设空间是有限个函数的集合 F = f 1 , f 2 , . . . f d F={f_1,f_2,...f_d} F=f1,f2,...fd时,对任意一个函数 f ∈ F f\in F f∈F,至少以概率 1 − δ , 0 < δ < 1 1-\delta,0<\delta<1 1−δ,0<δ<1,以下不等式成立: R ( f ) ⩽ R ^ ( f ) + ε ( d , N , δ ) (1) R(f)\leqslant \hat{R}(f) + \varepsilon (d,N,\delta) \tag{1} R(f)⩽R^(f)+ε(d,N,δ)(1)其中, ε ( d , N , δ ) = 1 2 N ( l o g d + l o g 1 δ ) (2) \varepsilon (d,N,\delta)=\sqrt{\frac{1}{2N}(logd+log\frac{1}{\delta})}\tag{2} ε(d,N,δ)=2N1(logd+logδ1)(2)
在式子(1)中,各因子的意义如下:
- R ( f ) R(f) R(f)为泛化误差,即表示该模型对未知数据预测的误差。
-
R
^
(
f
)
+
ε
(
d
,
N
,
δ
)
\hat{R}(f) + \varepsilon (d,N,\delta)
R^(f)+ε(d,N,δ)为泛化误差上界;
- R ^ ( f ) \hat{R}(f) R^(f)表示训练误差,即通过现有数据训练出来的模型,对于现有数据的误差;
- ε ( d , N , δ ) \varepsilon(d,N,\delta) ε(d,N,δ)是 N N N的递减函数, d d d是指假设空间的函数个数; N N N表示 f N f_N fN所依赖的样本容量。
根据式子(2)可知:
- 当 N N N趋近与无穷时,即训练样本足够多时, ε ( d , N , δ ) \varepsilon(d,N,\delta) ε(d,N,δ)趋近于 0 0 0,
- 当 d d d越大时,即假设空间容量越大, ε ( d , N , δ ) \varepsilon(d,N,\delta) ε(d,N,δ)就越大。
三、生成模型与判别模型
1.基本概念
监督学习的任务就是学习一个模型,应用这一模型,对给定的输入预测相应的输出,这个模型的一般形式为决策函数: Y = f ( X ) Y=f(X) Y=f(X)或者条件概率分布: P ( Y ∣ X ) P(Y|X) P(Y∣X)
监督学习方法又可以分为生成方法和判别方法,所学习到的模型分别称为生成模型(如朴素贝叶斯法)和判别模型(如K邻近法,决策树、支持向量机等)
2.特点
生成方法:
1.能够还原联合概率分布
P
(
X
.
Y
)
P(X.Y)
P(X.Y);
2.收敛速度快;
3.适用于存在隐变量1的数据集;
判别方法:
1.学习的准确率更高,
2.简化学习问题。
-
隐变量可以简单理解为:不能被直接观察到,但是对系统的状态和能观察到的输出存在影响的一种东西。 ↩︎
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。