
Hadoop

1.什么是Hadoop?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System)。
2.优点
1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖 [3] 。
2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中 [3] 。
3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 [3] 。
4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配 [3] 。
5.低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低 [3] 。
3.核心设计
HDFS(数据存储)和MapReduce(计算)。
HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
4.HDFS构架概述
Hadoop Distributed File System ,简称 HDFS ,是一个分布式文件系统
(1 ) NameNode :存储文件的 元数据 ,如 文件名,文件目录结构,文件属性 (生成时间、副本数、文件权限),以及每个文件的 块列表 和 块所在的 DataNode 等。
(2 ) DataNode:在本地文件系统 存储文件块数据 ,以及 块数据的校验和 。
(3 ) Secondary NameNode: 每隔一段时间对 NameNode 元数据备份 。
简单的说就是NameNode就相当于一个目录,一个索引,负责标记每一个DataNode的存放位置
而DataNode才是真正存放数据的, Secondary NameNode:相当与老板的一个秘书,他会备份 一部分 数据,不会备份全部数据。
5.MapReduce
MapReduce 本身就是用于并行处理大数据集的软件框架。MapReduce 的根源是函数性编程中的 map 和 reduce 函数。Map 函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce 函数接受 Map 函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小键/值对列表 。
6.YARN
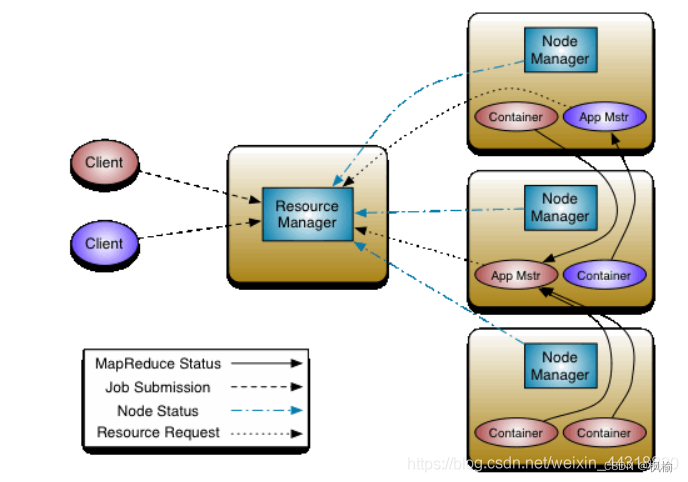
从YARN的架构来看,它由ResourceManager、NodeManager、JobHistoryServer、Containers、Application Master、job、Task、Client组成。
组件的主要功能介绍:
(1)ResourceManager:
处理客户端请求启动、监控ApplicationMaster、监控NodeManager、资源分配与调度
(2)ApplicationMaster:
为应用程序申请资源,并分配给内部任务、任务调度、监控与容错
(3)NodeManager:
单个节点上的资源管理、处理来自ResourceManger的命令、处理来自ApplicationMaster的命令
(4)Container:
对资源抽象和封装,目的是为了让每个应用程序对应的任务完成执行
(5)JobHistoryServer:
负责查询job运行进度及元数据管理。
(6)job:
是需要执行的一个工作单元:它包括输入数据、MapReduce程序和配置信息。job也可以叫作Application。
(7)task:
一个具体做Mapper或Reducer的独立的工作单元。task运行在NodeManager的Container中。
(8)Client:
一个提交给ResourceManager的一个Application程序。
https://blog.csdn.net/weixin_45366499/article/details/106897374
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。