
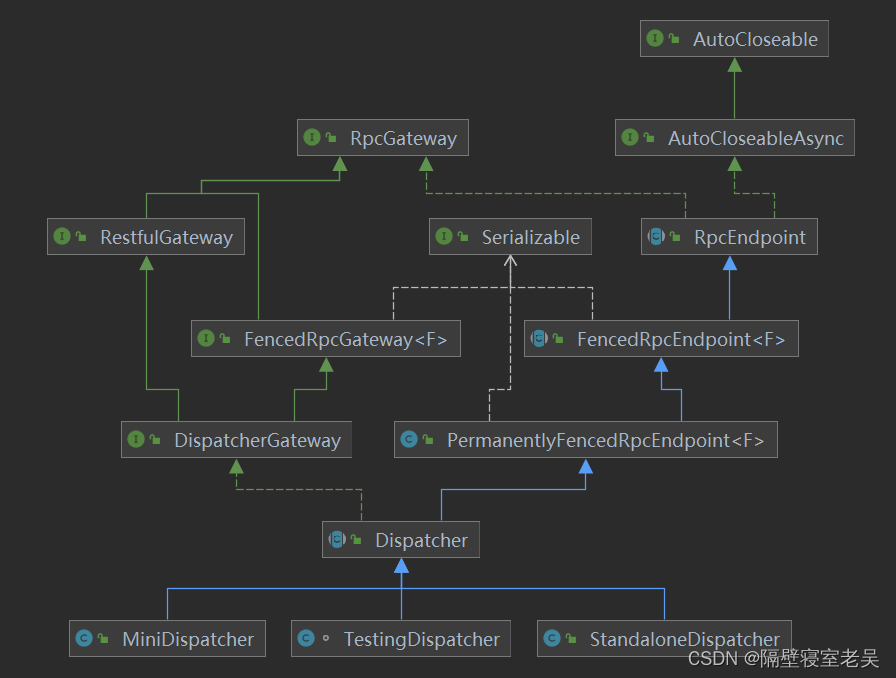
一、Flink的概念
JobManager:
它扮演的是集群管理者的角色,负责调度任务、协调 checkpoints、协调故障恢复、收集 Job 的状态信息,并管理 Flink 集群中的从节点 TaskManager。
并且他由以下三个主要的组件组成:
ResourceManager:
ResourceManager负责Flink 集群中的资源释放/分配——它管理taskslots,这是 Flink 集群中资源调度的单位(参见TaskManagers)。 Flink 为不同的环境和资源提供者(例如 YARN、Kubernetes和Standalone)实现了多个 ResourceManager。 在standalone的情况下,ResourceManager只能分配可用 TaskManager 的slot,而不能自行启动新的 TaskManager。
Dispatcher:
Dispatcher提供了一个REST 接口来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。 它还运行 Flink WebUI 以提供有关作业执行的信息。
JobMaster:
JobMaster 负责管理单个 JobGraph 的执行。 多个作业可以在一个 Flink 集群中同时运行,每个作业都有自己的 JobMaster。
TaskManager:
实际负责执行计算的 Worker,在其上执行 Flink Job 的一组Task;TaskManager 还是所在节点的管理员,它负责把该节点上的服务器信息比如内存、磁盘、任务运行情况等向JobManager 汇报。TaskManager 中资源调度的最小单位是task slot。TaskManager 中的task slots数量表示并发处理任务的数量。 请注意,一个task slot中可能会执行多个算子。
Client:
用户在提交编写好的 Flink 工程时,会先创建一个客户端再进行提交,这个客户端就是 Client,Client 会根据用户传入的参数选择使用 yarn per job 模式、stand-alone 模式还是 yarn-session 模式将 Flink 程序提交到集群

Task Slot
在Flink 集群中,一个 TaskManger 就是一个JVM 进程,并且会用独立的线程来执行 task,为了控制一个 TaskManger 能接受多少个 task,Flink提出了Task Slot 的概念。不同的 task 在不同的 slot 中执行,避免资源竞争。但是需要注意的是,slot 仅仅用来做内存的隔离,对 CPU 不起作用。那么运行在同一个 JVM 的 task 可以共享TCP 连接,减少网络传输,在一定程度上提高了程序的运行效率,降低了资源消耗。
默认情况下,Flink 允许子任务共享slot,即使它们是不同任务的子任务,只要它们来自同一个作业。结果是一个slot可以容纳整个作业管道。
Flink Session Cluster
集群生命周期:
在 Flink 会话集群中,客户端连接到一个预先存在的、长期运行的集群,该集群可以接受多个作业提交。即使在所有作业完成后,集群(和 JobManager)仍将继续运行,直到会话被手动停止。因此,Flink SessionCluster 的生命周期与任何 Flink Job 的生命周期无关。
资源隔离:
TaskManager 的slot由 ResourceManager 在作业提交时分配,并在作业完成后释放。因为所有作业都共享同一个集群,所以存在一些集群资源竞争——比如提交作业阶段的网络带宽。这种共享设置的一个限制是,如果一个 TaskManager 崩溃,那么所有在该 TaskManager 上运行任务的作业都将失败;同理,如果JobManager发生了一些致命的错误,就会影响到集群中运行的所有作业。
其他注意事项:
拥有一个预先存在的集群可以节省大量时间在申请资源和启动 TaskManagers。这在作业执行时间非常短且启动时间长会对端到端用户体验产生负面影响的情况下很重要——就像短查询的交互式分析一样,在这种情况下,作业可以快速使用现有资源执行计算。
Flink Job Cluster
集群生命周期:
在 Flink 作业集群中,可用的集群管理器(如 YARN)用于为每个提交的作业启动一个集群,并且该集群仅可用于该作业。在这里,客户端首先向集群管理器请求资源以启动 JobManager 并将作业提交给在此进程中运行的 Dispatcher。然后根据作业的资源需求延迟分配 TaskManager。一旦作业完成,Flink Job Cluster 就会被释放。
资源隔离:
JobManager 中的致命错误仅影响在该 Flink Job Cluster 中运行的一个作业。
其他注意事项:
由于ResourceManager需要申请并等待外部资源管理组件启动TaskManager进程并分配资源,所以Flink Job Clusters更适合长时间运行、对稳定性要求高、有更长的启动时间不敏感的大型作业。目前K8s不支持启动这种集群。
Flink Application Cluster:
集群生命周期:
Flink Application 集群是专用的 Flink 集群,仅从 Flink 应用程序执行作业,并且 main()方法在集群上而不是客户端上运行。提交作业是一个单步骤过程:无需先启动 Flink 集群,然后将作业提交到现有的 session 集群;相反,将应用程序逻辑和依赖打包成一个可执行的作业 JAR 中,并且集群入口(ApplicationClusterEntryPoint)负责调用 main()方法来提取 JobGraph。例如,这允许你像在Kubernetes 上部署任何其他应用程序一样部署 Flink 应用程序。因此,Flink Application 集群的寿命与 Flink 应用程序的寿命有关。
其他注意事项:
在 Flink Application 集群中,ResourceManager和 Dispatcher 作用于单个的 Flink 应用程序,相比于 Flink Session 集群,它提供了更好的隔离。
Keyed State
KeyedState是KeyBy算子之后执行带有状态的算子的中间状态, 每个KeyedState只能被对应的key使用。Keyed State 被进一步组织成所谓的Key Groups。Key Groups 是 Flink 可以重新分配 Keyed State 的原子单元;有与定义的最大并行度一样多的key Groups。在执行期间,keyed operator的每个并行实例都使用一个或多个键组的键。
Checkpoint
checkpoint又分为Aligned Checkpoint和Unaligned Checkpoint。
Aligned Checkpoint:
Flink的Job Master中有一个Checkpoint Coordinartor会定时触发一次checkpoint, 这个请求会发送给各个Source Operator,当Source Operator接收到该请求之后会将自己当前的状态写入到状态后端中,然后会向下游广播Checkpoint Barrier,并且还会向CheckpointCoordinartor发送一个确认已经做完checkpoint的响应。这个确认中包括了一些元数据,其中就包括刚才备份到State Backend的状态句柄,或者说是指向状态的指针。至此,Source完成了一次Checkpoint。跟Watermark的传播一样,一个算子子任务要把Checkpoint Barrier发送给所连接的所有下游算子子任务。
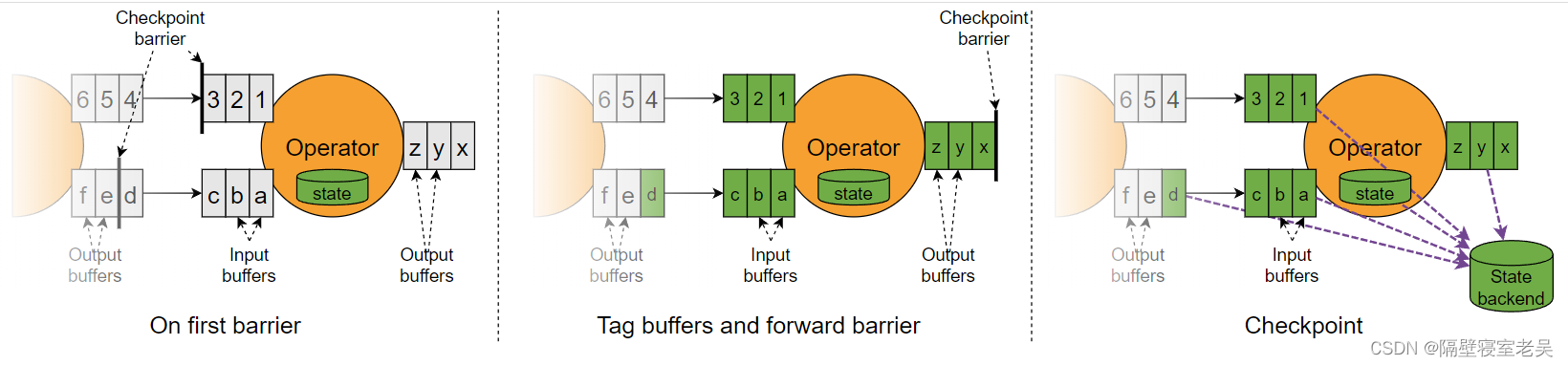
对于下游算子来说,可能有多个与之相连的上游输入,我们将算子之间的边称为通道。Source要将一个ID为n的CheckpointBarrier向所有下游算子广播,这也意味着下游算子的多个输入里都有同一个Checkpoint Barrier,而且不同输入里Checkpoint Barrier的流入进度可能不同。CheckpointBarrier传播的过程需要进行对齐(Barrier Alignment),如下图所示。

假设上图中注入的Snapshot Barrier的ID=n, 则有如下:
-
- 算子子任务在某个输入通道中收到第一个ID为n的Checkpoint Barrier,但是其他输入通道中ID为n的Checkpoint Barrier还未到达,该算子子任务开始准备进行对齐,这时候该算子无法流中的任何一条记录,否则会将属于快照n 的记录与属于快照n+1 的记录混合在一起。
- 算子子任务将第一个输入通道的数据缓存下来,同时继续处理其他输入通道的数据,这个过程被称为对齐,一旦接收到最后一个输入通道的屏障n,算子就会发出所有待处理的传出记录,然后该算子子任务执行快照,将状态写入State Backend,然后将ID为n的Checkpoint Barrier向下游所有输出通道广播。
- 对于这个算子子任务,快照执行结束,继续处理各个通道中新流入数据,包括刚才缓存起来的数据。
- 数据流图中的每个算子子任务都要完成一遍上述的对齐、快照、确认的工作,当最后所有Sink算子确认完成快照之后,说明ID为n的Checkpoint执行结束,Checkpoint Coordinator向State Backend写入一些本次Checkpoint的元数据。

生成的快照的内容有:
-
- 对于每个并行流数据源,快照开始时在流中的offset/position
- 对于每个运算符,指向作为快照一部分存储的状态的指针
Recovery:
这种机制下的恢复很简单:发生故障时,Flink 选择最新完成的检查点k。然后系统重新部署整个分布式数据流,并为每个算子提供作为检查点k一部分的快照状态。数据源算子被设置为从位置S k开始读取流。例如在 Apache Kafka 中,这意味着告诉消费者从偏移量S k开始获取。如果状态是增量快照,则算子从最新完整快照的状态开始,然后将一系列增量快照更新应用于该状态。
Unaligned Checkpoint:
如上是未对齐的Checkpoint,当算子接收到checkpoint barrier之后就立即对当前算子的state进行快照,当某些输入通道数据流执行得快一点的话,则会在快照n中包含快照n+1的信息,则在下一次的任务重启之后可能会导致重新消费处理这一部分快照n+1的数据,只能实现at least once的效果。
Recovery:
在开始处理来自未对齐检查点的上游算子的任何数据之前,操作员首先恢复运行中的数据。除此之外,它执行与恢复对齐检查点期间相同的步骤。
StateBackend:

MemoryStateBackend:
主要基于内存,它将数据存储在Java的堆区。当进行分布式快照时,所有算子子任务将自己内存上的状态同步到JobManager的堆上,一个作业的所有状态要小于JobManager的内存大小。这种方式显然不能存储过大的状态数据,否则将抛出OutOfMemoryError异常。因此,这种方式只适合调试或者实验,不建议在生产环境下使用。下面的代码告知一个Flink作业使用内存作为State Backend,并在参数中指定了状态的最大值,默认情况下,这个最大值是5MB。
FsStateBackend:
数据持久化到文件系统上,文件系统包括本地磁盘、HDFS以及包括Amazon、阿里云在内的云存储服务。使用时,我们要提供文件系统的地址,尤其要写明前缀,比如:file://、hdfs://或s3://。此外,这种方式支持Asynchronous Snapshot,默认情况下这个功能是开启的,可加快数据同步速度。
RocksDBStateBackend:
本地状态存储在本地的RocksDB上。RocksDB是一种嵌入式Key-Value数据库,数据实际保存在本地磁盘上。比起FsStateBackend的本地状态存储在内存中,RocksDB利用了磁盘空间,所以可存储的本地状态更大。然而,每次从RocksDB中读写数据都需要进行序列化和反序列化,因此读写本地状态的成本更高。快照执行时,Flink将存储于本地RocksDB的状态同步到远程的存储上,因此使用这种State Backend时,也要配置分布式存储的地址。AsynchronousSnapshot在默认情况也是开启的。
此外,这种State Backend允许增量快照(IncrementalCheckpoint),Incremental Checkpoint的核心思想是每次快照时只对发生变化的数据增量写到分布式存储上,而不是将所有的本地状态都拷贝过去。IncrementalCheckpoint非常适合超大规模的状态,快照的耗时将明显降低,同时,它的代价是重启恢复的时间更长。默认情况下,IncrementalCheckpoint没有开启,需要我们手动开启。
JobManager的数据结构

在作业执行期间,JobManager 会跟踪分布式任务,决定何时安排下一个任务(或一组任务),并对已完成的任务或执行失败做出反应。
JobManager接收 JobGraph ,它是由算子 ( JobVertex ) 和中间结果 ( IntermediateDataSet )组成的数据流的表示 。每个运算符都有属性,例如并行度和它执行的代码。此外,JobGraph 有一组附加的库,它们是执行操作符代码所必需的。
JobManager 将 JobGraph 转换为 ExecutionGraph 。ExecutionGraph 是 JobGraph 的并行版本:对于每个 JobVertex,它包含 每个并行子任务的 ExecutionVertex 。并行度为 100 的算子将有一个 JobVertex 和 100 个 ExecutionVertices。ExecutionVertex 跟踪特定子任务的执行状态。来自一个 JobVertex 的所有 ExecutionVertices 都保存在 ExecutionJobVertex 中 ,该ExecutionJobVertex 将操作符的状态作为一个整体进行跟踪。除了Vertices, ExecutionGraph 还包含 IntermediateResult 和 IntermediateResultPartition 。前者跟踪IntermediateDataSet的状态,后者是其每个分区的状态。
Flink中的窗口

基于时间的窗口:基于时间的窗口分配器(包括会话时间)既可以处理 事件时间,也可以处理 处理时间。这两种基于时间的处理没有哪一个更好,我们必须折衷。使用 处理时间,会有较低的延迟,但是我们必须接受以下限制:
-
- 无法正确处理历史数据,
- 无法正确处理超过最大无序边界的数据,
- 结果将是不确定的。
基于计数的窗口:使用基于计数的窗口时,只有窗口内的事件数量到达窗口要求的数值时,这些窗口才会触发计算。尽管可以使用自定义触发器自己实现该行为,但无法应对超时和处理部分窗口。
基于会话的窗口:会话窗口的实现是基于窗口的一个抽象能力,窗口可以 聚合。会话窗口中的每个数据在初始被消费时,都会被分配一个新的窗口,但是如果窗口之间的间隔足够小,多个窗口就会被聚合。延迟事件可以弥合两个先前分开的会话间隔,从而产生一个虽然有延迟但是更加准确地结果。
滑动窗口是通过复制来实现的:滑动窗口分配器可以创建许多窗口对象,并将每个事件复制到每个相关的窗口中。
时间窗口会和时间对齐:时间窗口将会和我们的时间一样的,比如一个小时的窗口在12:05,则窗口结束时间将会是在13:00,窗口长度将会是55分钟。
window 后面可以接 window:
stream
.keyBy(t -> t.key)
.window(<window assigner>)
.reduce(<reduce function>)
.windowAll(<same windowassigner>)
.reduce(<same reduce function>)
// 必须使用ReduceFunction 或 AggregateFunction
空的时间窗口不会输出结果:事件会触发窗口的创建。换句话说,如果在特定的窗口内没有事件,就不会有窗口,就不会有输出结果。
Flink中程序执行模式
-
- STREAMING:经典的DataStream执行模式(默认)
- BATCH:DataStream API 上的批处理式执行
- AUTOMATIC: 让系统根据源的有界性来决定
1.可以通过在任务提交的时候: $bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
2.可以在代码中进行配置:
StreamExecutionEnvironmentenv=StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
-
- Batch模式的没有checkpoint功能, 当Batch任务失败的时候将会回溯到DAG中上一个任务重新继续后面的计算。
- Btach模式不支持
Iterations(迭代计算)。
FlinK的WaterMark生成
最新版本已经废除了AssignerWithPeriodicWatermarks和AssignerWithPunctuatedWatermarks 。
最先版本提供了一个WatermarkStrategy来设置WaterMark, 使用方式如下:
WatermarkStrategy timestampAssigner =WatermarkStrategy
// .>forBoundedOutOfOrderness(Duration.ofSeconds(10))// 设置允许乱序的时间, 本处是使用了预定义的watermark生成器
.forGenerator(s-> new BoundedOutOfOrdernessGenerator())// 使用自定义的lanbda表达式
.withTimestampAssigner((s, l) -> { // 特么的这里还必须使用lambda
String[] arr = s.split(",");
long timeStamp = Long.parseLong(arr[1]);
System.err.println(s + ",EventTime:" + timeStamp);
return timeStamp;
})
.withIdleness(Duration.ofMinutes(1));// 设置当没有数据流入的时候, 水印无法推进,结果无法输出的问题
Flink中的状态
状态类型:
ValueState: 这会保留一个可以更新和检索的值(如上所述,范围限定为输入元素的键,因此操作看到的每个键可能都有一个值)。可以使用 设置update(T)和检索 该值T value()。
ListState: 这保留了一个元素列表。您可以追加元素并检索Iterable 所有当前存储的元素。使用add(T)或添加元素addAll(List),可以使用 检索 Iterable Iterable get()。您还可以覆盖现有列表update(List)
ReducingState: 这会保留一个值,代表添加到状态的所有值的聚合。该接口类似于ListState但使用添加的元素 add(T)减少为使用指定的聚合ReduceFunction。
AggregatingState: 这会保留一个值,代表添加到状态的所有值的聚合。与 相反ReducingState,聚合类型可能与添加到状态的元素类型不同。接口与 for 相同,ListState但使用添加的元素add(IN)使用指定的AggregateFunction.
MapState: 这会保留一个Map列表。您可以将键值对放入状态并检索Iterable当前存储的所有映射。使用put(UK, UV)或 添加映射putAll(Map)。可以使用 检索与用户键关联的值get(UK)。对于映射,键和值可迭代视图可以使用被检索entries(),keys()并values()分别。您还可以使用isEmpty()来检查此映射是否包含任何键值映射。
以上所有的状态都是i通过RuntimeContext访问的,所以只有在RichFunction中才能访问状态。
状态的TTL:
设置方式:
StateTtlConfigttlConfig=StateTtlConfig.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptorstateDescriptor=newValueStateDescriptor<>("textstate",String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
刷新状态 TTL 时配置更新类型:
-
- StateTtlConfig.UpdateType.OnCreateAndWrite - 仅在创建和写时候刷新(默认的配置)
- StateTtlConfig.UpdateType.OnReadAndWrite - 在读写的时候刷新
配置状态可见性是否在读取访问时返回过期值(如果尚未清除NeverReturnExpired)(默认情况下):
StateTtlConfig.StateVisibility.NeverReturnExpired
StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp
注意:
-
- 状态后端将上次修改的时间戳与用户值一起存储,这意味着启用此功能会增加状态存储的消耗。HeapStatebackend存储一个额外的 Java 对象,其中包含对用户状态对象的引用和内存中的原始 long 值。RocksDBStateBackend为每个VlaueState、ListState或MapState添加 8 个字节。
- 当前仅支持与处理时间相关的TTL 。
- 尝试恢复之前没有 TTL 配置的状态,使用启用 TTL 的描述符或反之亦然将导致兼容性失败和StateMigrationException.
- TTL 配置不是检查点或保存点的一部分,而是 Flink 在当前运行的作业中如何处理它的一种方式。
- 只有当用户的序列化器可以处理空值时,具有 TTL 的映射状态当前才支持空值。如果序列化器不支持空值,则可以以NullableSerializer序列化形式增加一个额外字节的代价对其进行包装。
状态清理:
默认情况下,过期值会在读取时显式删除,例如ValueState#value,如果配置的状态后端支持,并在后台定期垃圾收集。
目前,堆状态后端依赖增量清理,RocksDB 后端使用压缩过滤器进行后台清理。
StateTtlConfig ttlConfig=StateTtlConfig.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()// 进行全量快照时执行清理操作, 适用于FsStateBackend
.build();
StateTtlConfig ttlConfig=StateTtlConfig.newBuilder(Time.seconds(1))
.cleanupIncrementally(10,true) // 进行增量清理操作触发器可以是来自每个状态访问或/和每个记录处理的回调。如果此清理策略对于某个状态是活动的,则存储后端会为其所有条目保留此状态的惰性全局迭代器。每次触发增量清理时,迭代器都会前进。检查遍历的状态条目并清除过期的条目。
// 第一个是每次清触发清除的状态条数。它总是在每次状态访问时触发。
// 第二个参数定义是否在每次记录处理时额外触发清理。Heap Staet的默认后台清理检查 5 个在执行处理时没有清理操作的状态数。
.build();
注意:
-
- 如果没有对该状态进行访问或没有处理任何记录,则过期状态将持续存在。
- 增量清理所花费的时间会增加记录处理延迟。
- 目前仅对Heap State Backend实施增量清理。为 RocksDB 设置它不会有任何效果。
- 如果Heap State Backend与同步快照一起使用,全局迭代器在迭代时保留所有键的副本,因为它的特定实现不支持并发修改。启用此功能将增加内存消耗。异步快照没有这个问题。
- 对于现有作业,可以随时激活或停用此清理策略StateTtlConfig,例如从保存点重新启动后。
RocksDb的Compact Cleanup:
StateTtlConfig ttlConfig=StateTtlConfig.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build();
RocksDB CompactFilter会在每次处理一定数量的状态条目后从 Flink 查询当前时间戳,用于检查过期时间。您可以更改它并将自定义值传给 StateTtlConfig.newBuilder(...).cleanupInRocksdbCompactFilter(longqueryTimeAfterNumEntries)方法。更频繁地更新时间戳可以提高清理速度,但会降低压缩性能,因为它使用来自本机代码的 JNI 调用。RocksDB 后端的默认后台清理每处理 1000 个条目就查询当前时间戳。
注意:
-
- 在压缩期间调用 TTL 过滤器会减慢它的速度。TTL 过滤器必须解析上次访问的时间戳,并检查每个正在压缩的键的每个存储状态条目的过期时间。在集合状态类型(列表或映射)的情况下,还会为每个存储的元素调用检查。
- 如果此功能与具有非固定字节长度的元素的列表状态一起使用,则本机 TTL 过滤器必须在每个状态条目上通过 JNI 额外调用元素的 Flink java 类型序列化器,其中至少第一个元素已过期确定下一个未过期元素的偏移量。
- 对于现有作业,可以随时激活或停用此清理策略StateTtlConfig,例如从保存点重新启动后。
Operator state的实现(不进行keyby操作之后的State):
可以通过实现CheckpointedFunction接口并且实现其以下的方法来访问State:
Void snapshotState(FunctionSnapshotContextcontext)throwsException;
Void initializeState(FunctionInitializationContextcontext)throwsException;
每次在执行checkpoint的时候snapshotState会被调用,在算子第一次初始化和从较早的检查点进行恢复的时候会调用initializeState。
目前Operator State是List类型,根据状态访问的方式,具有以下的重新分配状态的方式:
Even-split redistribution: 每个算子返回一个状态元素列表。整个状态在逻辑上是所有列表的串联。在恢复/重新分发时,列表被平均分成与并行操作符一样多的子列表。每个操作符得到一个子列表,它可以是空的,也可以包含一个或多个元素。
Union redistribution: 每个算子返回一个状态元素列表。整个状态在逻辑上是所有列表的串联。在恢复/重新分配时,每个操作员都会获得完整的状态元素列表。如果您的列表有很多的话(当对应于具有很大的并行度的时候),请不要使用此功能。检查点元数据将存储每个列表条目的偏移量,这可能导致 RPC 帧大小或内存不足错误。
如下有一个在Sink操作的时候,执行攒批的操作,进行状态的初始化和恢复操作的做法:
publicclass BufferingSink implements SinkFunction>,
CheckpointedFunction {
private final int threshold; // 攒批的阈值
private transientListState> checkpointedState; // 这里申明了进行状态快照的状态对象
private List> bufferedElements; // 缓存将要写出的数据元素
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = newArrayList<>();
}
@Override
public void invoke(Tuple2 value, Context contex) throws Exception {
bufferedElements.add(value);
if (bufferedElements.size() >=threshold) {
for (Tuple2element: bufferedElements) {
// send it to the sink
}
bufferedElements.clear();
}
}
@Override
public voidsnapshotState(FunctionSnapshotContext context) throws Exception {
checkpointedState.clear(); // 在进行快照的时候先清除前一个快照的数据
for (Tuple2element : bufferedElements) {
checkpointedState.add(element); // 进行状态快照的时候, 将攒批的元素挨个添加导快照的状态中去
}
}
@Override
public voidinitializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor> descriptor =
new ListStateDescriptor<>(
"buffered-elements",
TypeInformation.of(newTypeHint>() {}));
// 初始化获取Opeartor State这里就对应的Even-split redistribution, 如果想要使用Union redistribution则需调用getUnionListState(descriptor)
checkpointedState =context.getOperatorStateStore().getListState(descriptor);
if (context.isRestored()) { // 是否在失败后恢复
for (Tuple2element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}
如下有一个带状态的Source, 并且对数据的offset进行了快照操作:
publicstatic class CounterSource extends RichParallelSourceFunctionimplements CheckpointedFunction {
/** current offset for exactly once semantics */
private Long offset = 0L;
/** flag for job cancellation */
private volatile boolean isRunning = true;
/** Our state object. */
private ListState state;
@Override
public void run(SourceContext ctx) {
final Object lock =ctx.getCheckpointLock(); // 这里获取checkpoint的锁对象
while (isRunning) {
// output and state update areatomic
synchronized (lock) {
ctx.collect(offset); // 将数据往下下发
offset += 1; // 将offset自增
}
}
}
@Override
public void cancel() {
isRunning = false; // 标识source退出了
}
@Override
public voidinitializeState(FunctionInitializationContext context) throws Exception {
state =context.getOperatorStateStore().getListState(new ListStateDescriptor<>(
"state",
LongSerializer.INSTANCE));
// restore any state that we mightalready have to our fields, initialize state
// is also called in case of restore.
for (Long l : state.get()) { // 初始化状态, 这里采用Even-split redistribution的恢复方式
offset = l;
}
}
@Override
public voidsnapshotState(FunctionSnapshotContext context) throws Exception {
state.clear();
state.add(offset); // 这里进行状态的快照
}
}
当 Flink 完全确认检查点时,一些运营商可能需要这些信息与外界进行通信。通过CheckpointListener来实现的操作。
广播状态模式:
广播流目前的状态类型都是MapState, 所以定义的状态的描述符中只能为MapStateDescriptor。
当普通流需要和广播流进行join操作的时候,只能通过connect去关联广播状态流,并且使用CoProcessFunction来进行两个输入流的关联处理。
以下又分为当普通流为KeyedStream和NonKeyedStream的时候,分别需要实现
public abstract classKeyedBroadcastProcessFunction {
public abstractvoid processElement(IN1 value, ReadOnlyContext ctx, Collector out)throws Exception;
public abstractvoid processBroadcastElement(IN2 value, Context ctx, Collector out)throws Exception;
public voidonTimer(long timestamp, OnTimerContext ctx, Collector out) throwsException;
}
public abstract class BroadcastProcessFunction extends BaseBroadcastProcessFunction {
public abstractvoid processElement(IN1 value, ReadOnlyContext ctx, Collector out)throws Exception;
public abstractvoid processBroadcastElement(IN2 value, Context ctx, Collector out)throws Exception;
}
如上processElement中的ReadOnlyContext获取到广播流状态之后只能读取,processBroadcastElement中的Context获取到广播流状态之后可以进行修改操作。
注意: 当在进行这两个流的关联的时候,可能会由于两个流中数据到达的速率不一样,可能导致processElement中获取不到状态。
Checkpoint
启用检查点
env.enableCheckpointing(3*60*1000, CheckpointingMode.EXACTLY_ONCE)
检查点的属性设置
| env.getCheckpointConfig().setCheckpointStorage() |
设置检查点的存储位置, 其中有以下的两个选项: JobManagerCheckpointStorage: 1.该checkpoint的状态数据存储在JobManager的堆内存中, 并且默认的大小为5MB, 可以在构造函数中修改 2.无论配置的最大状态大小如何,状态都不能大于 Akka 帧大小 3.聚合状态必须小于等于JobManager 内存。 FileSystemCheckpointStorage : 1.设置将checkpoint的状态存储在外部的文件系统中 2.将checkpoint的状态数据的元数据存储在JobManager的堆内存中, 在高可用情况下存储在Metadata Checkpoint的目录中(一般为Zookeeper的znode中) 3. 建议在使用FileSystemCheckpointStorage 的时候设置高可用,并且将Managed Memory设置为0, 保证所有的代码都给用户代码使用。 |
| env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); checkpointConfig.setAlignedCheckpointTimeout(); |
设置检查点的模式, 如果是EXACTLY_ONCE则会触发,算子中的Checkpoint Barrier对齐操作。 并且还可以配置在Barrier对齐的时候的超时时间。 |
| env.getCheckpointConfig().setCheckpointTimeout(60000); |
设置检查点超时, 当触发超时的时候会导致正在进行中的Checkpoint被中断。 |
| env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); |
设置最小检查点的时间间隔, 该含义是指当前一个检查点结束之后多长时间触发下一次检查点。当配置了这个之后还意味这检查点的并发为1 |
| env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2); |
设置在整个作业故障转移之前可以容忍的连续检查点失败次数,如果检查点失败次数超过该值之后程序会失败。 |
| env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); |
并发检查点数:默认情况下,系统不会在一个检查点仍在进行中时触发另一个检查点。这确保拓扑不会在检查点上花费太多时间,并且不会在处理流方面取得进展。可以允许多个重叠检查点,这对于具有一定处理延迟(例如,因为函数调用需要一些时间来响应的外部服务)但仍希望执行非常频繁的检查点(100 毫秒)的管道很有趣) 在失败时很少重新处理。如果定义了检查点之间的最短时间,则无法使用此选项。 |
| env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); |
设置在程序退出之后,检查点的保存策略 |
| env.getCheckpointConfig().enableUnalignedCheckpoints(); |
未对齐的检查点:您可以启用未对齐的检查点以大大减少背压下的检查点时间。这仅适用于Exactly-ONCE检查点和检查点并发为1。 |
| Configurationconfig=new Configuration(); config.set(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH,true); env.configure(config); |
从 Flink 1.14 开始,即使作业图的某些部分已经完成了所有数据的处理,也可以继续执行检查点,如果它包含有界源,则可能会发生这种情况。此功能必须通过功能标志启用 |
检查点的目录结构:
与savepoints类似,检查点由元数据文件和根据状态后端的一些附加数据文件组成。元数据文件和数据文件存放在state.checkpoints.dir配置文件中配置的目录中,也可以在代码中为每个作业指定。

SHARED目录用于可能属于多个检查点的状态,TASKOWNED用于永远不能被JobManager 删除的状态,而EXCLUSIVE用于仅属于一个检查点的状态。
注意: 检查点与保存点有一些不同。
-
- 使用状态后端特定(低级)数据格式,可能是增量的。
- 不支持 Flink 特定的功能,如重新缩放。
从保留的检查点恢复:
bin/flink run -s:checkpointMetaDataPath [:runArgs]
以下的检查点相关的属性可以在flink.yml配置文件中配置:
| Key |
Default |
Type |
Description |
| state.backend.incremental |
false |
Boolean |
如果可能,选择状态后端是否应创建增量检查点。对于增量检查点,只存储与前一个检查点的差异,而不是完整的检查点状态。启用后,Web UI 中显示的状态大小或从 rest API 获取的状态大小仅表示增量检查点大小而不是完整检查点大小。某些状态后端可能不支持增量检查点并忽略此选项。 |
| state.backend.local-recovery |
false |
Boolean |
此选项为此状态后端配置本地恢复。默认情况下,本地恢复处于停用状态。本地恢复目前仅涵盖KeyedStateBackend。目前,MemoryStateBackend 不支持本地恢复,忽略此选项。 |
| state.checkpoint-storage |
(none) |
String |
用于检查点状态的检查点存储实现。实现可以通过它们的快捷方式名称指定,也可以通过CheckpointStorageFactory. 如果指定了工厂,则通过其零参数构造函数对其进行实例化,并CheckpointStorageFactory#createFromConfig(ReadableConfig, ClassLoader) 调用其方法。公认的快捷方式名称是“jobmanager”和“filesystem”。 |
| state.checkpoints.dir |
(none) |
String |
Flink 支持的文件系统中用于存储检查点的数据文件和元数据的默认目录。存储路径必须可以从所有参与的进程/节点(即所有 TaskManager 和 JobManager)访问。 |
| state.checkpoints.num-retained |
1 |
Integer |
要保留的已完成检查点的最大数量。 |
| state.savepoints.dir |
(none) |
String |
保存点的默认目录。由将保存点写入文件系统的状态后端使用(HashMapStateBackend、EmbeddedRocksDBStateBackend)。 |
| state.storage.fs.memory-threshold |
20 kb |
MemorySize |
状态数据文件的最小大小。所有小于该值的状态块都内联存储在根检查点元数据文件中。此配置的最大内存阈值为 1MB。 |
| state.storage.fs.write-buffer-size |
4096 |
Integer |
写入文件系统的检查点流的写入缓冲区的默认大小。实际写入缓冲区大小确定为该选项和选项“state.storage.fs.memory-threshold”的最大值。 |
| taskmanager.state.local.root-dirs |
(none) |
String |
定义用于存储基于文件的状态以进行本地恢复的根目录的 config 参数。本地恢复目前仅涵盖键控状态后端。目前,MemoryStateBackend 不支持本地恢复,忽略该选项 |
保存点
// flink-conf.yml配置系统级别的保存点目录, 该配置可以在提交任务时覆盖,并且该目录必须在taskmanager和jobmanager都能访问到的位置state.savepoints.dir: hdfs:///flink/savepoints
// 触发 ID 为作业的保存点:jobId,并返回创建的保存点的路径。您需要此路径来恢复和处置保存点。
bin/flink savepoint :jobId [:targetDirectory]
// 触发具有 ID:jobId和 YARN 应用程序 ID的作业的保存点:yarnAppId,并返回创建的保存点的路径。
bin/flink savepoint :jobId [:targetDirectory]-yid:yarnAppId
// 自动触发具有 ID 的作业的保存点:jobid并停止作业。此外,您可以指定一个目标文件系统目录来存储保存点。该目录需要由 JobManager(s) 和 TaskManager(s) 访问。
bin/flink stop --savepointPath [:targetDirectory] :jobId
// 这会提交一个作业并指定一个保存点来恢复。您可以给出保存点目录或_metadata文件的路径。
bin/flink run -s :savepointPath [:runArgs]
// 当删除了一个算子的时候, 需要加上--allowNonRestoredState(简写: -n) 来取消
bin/flink run -s :savepointPath -n [:runArgs]
// 删除保存点, 请注意,也可以通过常规文件系统操作手动删除保存点,而不会影响其他保存点或检查点(请记住,每个保存点都是自包含的)。
// 在 Flink 1.2 之前,这是一个更繁琐的任务,使用上面的 savepoint 命令执行。
bin/flink savepoint -d :savepointPath
状态后端
-
- HashMapStateBackend
HashMapStateBackend在内部将数据保存为 Java 堆上的对象。键/值状态和窗口运算符持有存储值、触发器等的哈希表。
鼓励HashMapStateBackend 用于:
具有大状态、长窗口、大键/值状态的作业。
所有高可用性设置。
还建议将托管内存设置为零。这将确保为 JVM 上的用户代码分配最大内存量。
-
- EmbeddedRocksDBStateBackend
EmbeddedRocksDBStateBackend将动态数据保存在RocksDB数据库中,该数据库(默认情况下)存储在 TaskManager 本地数据目录中。与在HashMapStateBackend 中存储 java 对象不同,数据存储为序列化字节数组,主要由类型序列化程序定义,导致键比较是按字节进行的,而不是使用 Java 的hashCode() 和 equals() 方法。
EmbeddedRocksDBStateBackend始终执行异步快照。
EmbeddedRocksDBStateBackend 的限制:
-
- 由于 RocksDB 的 JNI 桥接 API 基于 byte[],每个键和每个值支持的最大大小为 2^31 个字节。在 RocksDB 中使用合并操作的状态(例如 ListState)可以默默地累积大于 2^31 字节的值,然后在下次检索时失败。这是目前 RocksDB JNI 的一个限制。
EmbeddedRocksDBStateBackend 鼓励用于:
-
- 具有非常大的状态、长窗口、大键/值状态的作业。
- 所有高可用性设置。
请注意,您可以保留的状态量仅受可用磁盘空间量的限制。与将状态保存在内存中的 HashMapStateBackend 相比,这允许保存非常大的状态。但是,这也意味着使用此状态后端可以实
现的最大吞吐量会更低。从/到该后端的所有读/写都必须经过反序列化来检索/存储状态对象,这也比始终使用基于堆的后端所做的堆上表示更昂贵。
内存管理:
Flink 旨在控制总进程内存消耗,以确保 Flink 任务管理器具有良好的内存占用。这意味着要保持在环境(Docker/Kubernetes、Yarn 等)强制执行的限制内,以免因消耗过多内存而被杀死,但也不要未充分利用内存(不必要的溢出到磁盘、浪费缓存机会、降低性能) .
为了实现这一点,Flink默认将 RocksDB 的内存分配配置为 TaskManager 的托管内存量(或者更准确地说,task slot)。这应该为大多数应用程序提供良好的开箱即用体验,这意味着大多数应用程序不需要调整任何详细的 RocksDB 设置。改善内存相关性能问题的主要机制是简单地增加 Flink 的托管内存。
用户可以选择停用该功能,并让 RocksDB 为每个 ColumnFamily 独立分配内存(每个操作员每个状态一个)。这最终为专家用户提供了对 RocksDB 的更细粒度的控制,但这意味着用户需要注意自己的整体内存消耗不会超过环境的限制。有关大型状态性能调整的一些指南,请参阅大型状态调整。
RocksDB的托管内存
此功能默认处于活动状态,可以通过state.backend.rocksdb.memory.managed=false配置键(取消)激活。
Flink 并不直接管理 RocksDB 的原生内存分配,而是以某种方式配置 RocksDB,以确保它使用的内存与 Flink 的托管内存预算一样多。这是在每个插槽级别上完成的(托管内存按插槽计算)。
为了设置 RocksDB 实例的总内存使用量,Flink在单个插槽中的所有实例之间利用共享缓存 和写入缓冲区管理器。共享缓存将对 RocksDB 中使用大部分内存的三个组件设置上限:块缓存、索引和布隆过滤器以及 MemTables。
对于高级调优,Flink 还提供了两个参数来控制写路径(MemTable)和读路径(索引&过滤器,剩余缓存)之间的内存划分。当您看到 RocksDB 由于缺少写入缓冲区内存(频繁刷新)或缓存未命中而导致性能不佳时,您可以使用这些参数重新分配内存。
-
- state.backend.rocksdb.memory.write-buffer-ratio,默认情况下0.5,这意味着写入缓冲区管理器将使用 50% 的给定内存。
- state.backend.rocksdb.memory.high-prio-pool-ratio,默认情况下0.1,这意味着给定内存的 10% 将被设置为共享块缓存中索引和过滤器的高优先级。我们强烈建议不要将此设置为零,以防止索引和过滤器与数据块竞争以保持缓存并导致性能问题。此外,L0 级别的过滤器和索引默认固定在缓存中以缓解性能问题,更多详细信息请参阅
检查点压缩
Flink 为所有检查点和保存点提供可选的压缩(默认:关闭)。目前,压缩始终使用snappy 压缩算法(版本 1.1.4),但我们计划在未来支持自定义压缩算法。压缩作用于键控状态的键组的粒度,即每个键组可以单独解压缩,这对于重新缩放很重要。
可以通过以下方式激活压缩ExecutionConfig:
ExecutionConfigexecutionConfig=newExecutionConfig();
executionConfig.setUseSnapshotCompression(true);
LOCAL RECORVERY(任务本地恢复)
// 在全局配置中设置启用本地恢复(注意:默认是不开启)
state.backend.local-recovery = true
// 或者在代码中设置
CheckpointingOptions.LOCAL_RECOVERY = true
限制:目前,任务本地恢复仅涵盖键控状态后端。键控状态通常是该状态的最大部分。
restart-strategy(重启策略)
1. Fixed Delay Restart Strategy (固定延迟重启策略,是默认的设置,重新启动尝试为Integer.MAX_VALUE和1 s延迟)
StreamExecutionEnvironmentenv = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(10, TimeUnit.SECONDS) // delay
));
含义: 失败后重启3次,并且每次重启之间间隔10秒钟。
2. Exponential Delay Restart Strategy(指数延迟重启策略)
// 如果重新启动策略已设置为指数延迟,则重新启动之间的启动持续时间。可以使用符号来指定:“1 min”、“20 s”
restart-strategy.exponential-delay.initial-backoff: 10 s
// 如果重新启动策略已设置为指数延迟,则重新启动之间可能的最长持续时间。可以使用符号来指定:“1 min”、“20 s”
restart-strategy.exponential-delay.max-backoff: 2 min
// 每次失败后,退避值乘以该值,直到达到最大退避(如果restart-strategy已设置为 )exponential-delay。
restart-strategy.exponential-delay.backoff-multiplier:2.0
// 如果重新启动策略已设置为指数延迟,则退避重置为其初始值时的阈值。它指定作业必须运行多长时间才能将指数增加的退避重置为其初始值。 可以使用符号来指定:“1 min”、“20 s”
restart-strategy.exponential-delay.reset-backoff-threshold:10 min
// 如果重新启动策略已设置为指数延迟,则抖动指定为退避的一部分。它表示将在退避中添加或减去多大的随机值。 当您想避免同时重新启动多个作业时很有用。
restart-strategy.exponential-delay.jitter-factor: 0.1
StreamExecutionEnvironmentenv = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.exponentialDelayRestart(
Time.milliseconds(1),
Time.milliseconds(1000),
1.1, // exponential multiplier
Time.milliseconds(2000), // thresholdduration to reset delay to its initial value
0.1 // jitter
));
3. FailureRate Restart Strategy(故障率重启策略)
// 如果重新启动策略已设置为restart-strategy,则在作业失败之前给定时间间隔内的最大重新启动次数。
restart-strategy.failure-rate.max-failures-per-interval:3
// 如果重新启动策略已设置为restart-strategy,则测量故障率的时间间隔。 可以使用符号来指定:“1 min”、“20 s”
restart-strategy.failure-rate.failure-rate-interval: 5min
// 如果重新启动策略已设置为restart-strategy,则两次连续重新启动尝试之间的延迟。 可以使用符号来指定:“1 min”、“20 s”
restart-strategy.failure-rate.delay: 10 s
StreamExecutionEnvironmentenv = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // max failures per interval
Time.of(5, TimeUnit.MINUTES), //time intervalfor measuring failure rate
Time.of(10, TimeUnit.SECONDS) // delay
));
4.NoRestart Strategy(没有重启策略)
restart-strategy: none
StreamExecutionEnvironmentenv = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
Task失败重启策略
jobmanager.execution.failover-strategy:
Full: 此策略重新启动作业中的所有任务以从任务失败中恢复。
Region:
1.包含失败任务的region将重新启动。
2. 如果结果分区在将要重新启动的region需要时不可用,则生成结果分区的region也将重新启动。
3.如果要重新启动一个region,则它的所有消费者region也将重新启动。这是为了保证数据的一致性,因为非确定性处理或分区会导致不同的分区。
Flink支持的数据类型
| Java Tuples and Scala Case Classes |
|
| Java POJOs |
1. 类必须是public并且没有非静态的内部类 2. 必须有一个无参构造函数 3. 字段必须公开,或者有对应的setter和getter函数 4. 类(以及所有超类)中的所有非静态、non-transient的字段要么是公共的(和non-final),要么具有遵循 Java bean 的 getter 和 setter 命名约定的公共 getter 和 setter 方法。 |
| Primitive Types |
|
| Regular Classes |
所有未被识别为 POJO 类型的类(参见上面的 POJO 要求)都被 Flink 作为通用类类型处理。 Flink 将这些数据类型视为黑匣子,并且无法访问它们的内容(例如,为了高效排序)。 使用序列化框架 Kryo 对一般类型进行反/序列化。 |
| Values |
值类型手动描述它们的序列化和反序列化。他们没有通过通用序列化框架,而是通过使用 read 和 write 方法实现 org.apache.flink.types.Value 接口来为这些操作提供自定义代码。当通用序列化效率非常低时,使用 Value 类型是合理的。一个示例是将元素的稀疏向量实现为数组的数据类型。知道数组大部分为零,可以对非零元素使用特殊编码,而通用序列化将简单地写入所有数组元素。 org.apache.flink.types.CopyableValue 接口以类似的方式支持手动内部克隆逻辑。 Flink 自带对应基本数据类型的预定义值类型。 (ByteValue、ShortValue、IntValue、LongValue、FloatValue、DoubleValue、StringValue、CharValue、BooleanValue)。这些值类型充当基本数据类型的可变变 体:它们的值可以改变,允许程序员重用对象并减轻垃圾收集器的压力。 |
| Hadoop Writables |
您可以使用实现 org.apache.hadoop.Writable 接口的类型。 write() 和 readFields() 方法中定义的序列化逻辑将用于序列化。 |
| Special Types |
您可以使用特殊类型,包括 Scala 的Either、Option和Try。 Java API 有自己的Either 自定义实现。 与Scala 的Either 类似,它表示两种可能类型的值,Left 或Right。 要么对错误处理有用,要么对需要输出两种不同类型记录的运算符有用。 |
Flink与类型相关的问题:
| Registering subtypes |
如果函数签名只描述了超类型,而实际上在执行过程中使用了这些超类型的子类型,那么让 Flink 知道这些子类型可能会大大提高性能。 StreamExecutionEnvironment.registerType(clazz) |
| Registering custom serializers |
当Flink遇到不能执行序列化的类型的时候,会使用Kryo来执行序列化操作。 StreamExecutionEnvironment.getConfig().addDefaultKryoSerializer(clazz, serializer) |
| Adding Type Hints |
当 Flink 尽管使用了所有技巧仍无法推断出泛型类型时,用户必须传递类型提示。这通常只在 Java API 中是必需的。 |
| Manually creating a TypeInformation |
这对于某些 API 调用可能是必要的,由于 Java 的泛型类型擦除,Flink 无法推断数据类型。 |
Flink 的 TypeInformation 类
类 TypeInformation 是所有类型描述符的基类。它揭示了类型的一些基本属性,并且可以生成序列化器,并且在专业化中可以生成类型的比较器。
请注意,Flink 中的比较器所做的不仅仅是定义顺序 - 它们基本上是处理键的实用程序)
Flink中的类型区分:
- 基本类型: Java基本类型和包装器类型。void, String, Date, BigDecimal, 和BigInteger。
- 基本类型数组和对象数组。
- 复合类型:
-
- Flink Java 元组(Flink Java API 的一部分):最多 25 个字段,不支持空字段
- Scala case class(包括 Scala 元组):不支持空字段。
- Row: 具有任意数量字段并支持空字段的元组。
- POJO类型。
- 辅助类型(Option、Either、Lists、Maps……)。
- 泛型类型:这些不会被 Flink 本身序列化,而是被 Kryo 序列化。
创建一个 TypeInformation 或 TypeSerializer
非泛型类型:
TypeInformation<String> info = TypeInformation.of(String.class);
泛型类型:
TypeInformation<Tuple2<String,Double>> info = TypeInformation.of(newTypeHint<Tuple2<String,Double>>(){});
创建一个TypeSerializer直接info.createSerializer(config)
在 Flink 无法重建擦除的泛型类型信息的情况下,Java API 提供了所谓的类型提示。类型提示告诉系统函数产生的数据流或数据集的类型:
DataStreamresult= stream.map(new MyGenericNonInferrableFunction())
.returns(SomeType.class);
注意: returns中传入的可以是一个类或者一个泛型的TypeHint
当Kryo无法序列化我们定义的POJO类型,则可以要求使用Arvo来代替Kryo序列化POJO:
Final StreamExecutionEnvironmentenv = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().enableForceAvro();
希望Kryo 序列化程序处理整个POJO 类型,请设置
Final StreamExecutionEnvironmentenv = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().enableForceKryo();
如果 Kryo 无法序列化您的 POJO,您可以向 Kryo 添加自定义序列化程序,使用
env.getConfig().addDefaultKryoSerializer(Class type,Class> serializerClass)
禁止Kryo最为泛型类型序列化的兜底方式:
env.getConfig().disableGenericTypes();
Flink的算子
| dataStream.shuffle(); |
根据均匀分布随机划分元素 |
| dataStream.rebalance(); |
进行完全重平衡操作 |
| dataStream.rescale(); |
如果上游操作的并行度为 2,下游操作的并行度为 6,那么一个上游操作会将元素分发给三个下游操作,而另一个上游操作将分发给其他三个下游操作。 |
| dataStream.broadcast(); |
将每个元素广播到下游的所有分区 |
| dataStream.partitionCustom(); |
自定义分区器 |
| dataStream.keyBy(value->value.f0).window(TumblingEventTimeWindows.of(Time.seconds(5))); |
|
| dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))); |
|
| dataStream.union(otherStream1,otherStream2,...); |
不会进行去重操作 |
| dataStream.join(otherStream) .where().equalTo() .window(TumblingEventTimeWindows.of(Time.seconds(3))) .apply(new JoinFunction(){...}); |
两个流进行join操作, 关于语义的一些注意事项: · 创建两个流的元素的成对组合的行为类似于内连接,这意味着如果一个流中的元素没有来自另一个流的相应元素要连接,则不会发出它们。 · 那些确实被加入的元素将把仍然位于各自窗口中的最大时间戳作为它们的时间戳。例如[5, 10),具有边界的窗口将导致连接元素的时间戳为 9。 |
| // this will join the two streams so that // key1 == key2 && leftTs - 2 < rightTs < leftTs + 2 keyedStream.intervalJoin(otherKeyedStream).between(Time.milliseconds(-2),Time.milliseconds(2))// lower and upper bound .upperBoundExclusive(true)// optional .lowerBoundExclusive(true)// optional .process(newIntervalJoinFunction(){...}); orangeStream .keyBy() .intervalJoin(greenStream.keyBy()) .between(Time.milliseconds(-2), Time.milliseconds(1)) .process (new ProcessJoinFunction @Override public void processElement(Integer left, Integer right, Context ctx, Collector out) { out.collect(first + "," + second); } }); |
Between: 右边流的时间在左边流的时间范围之内 upperBoundExclusive: 表示是否不等于最大的时间 lowerBoundExclusive: 表示是否不等于做小的时间 |
| dataStream.coGroup(otherStream).where(0).equalTo(1).window(TumblingEventTimeWindows.of(Time.seconds(3))).apply(newCoGroupFunction(){...}); |
|
| ConnectedStreams<Integer,String>connectedStreams=someStream.connect(otherStream); |
连接两个流,两个流互相共享流状态 |
Flink的Window
Keyed Windows:
stream .keyBy(...) <- keyed versus non-keyed windows .window(...) <- required: "assigner" [.trigger(...)] <- optional: "trigger" (else defaulttrigger) 触发器还可以决定在创建和删除窗口之间的任何时间清除窗口的内容 [.evictor(...)] <- optional: "evictor" (else noevictor) 它可以在触发器触发后以及应用函数之前和/或之后从窗口中删除元素。 [.allowedLateness(...)] <- optional: "lateness" (else zero) [.sideOutputLateData(...)]<- optional: "output tag"(else no side output for late data) .reduce/aggregate/apply() <- required: "function" [.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows:
stream .windowAll(...) <- required: "assigner" [.trigger(...)] <- optional: "trigger" (else default trigger) [.evictor(...)] <- optional: "evictor" (else noevictor) [.allowedLateness(...)] <- optional: "lateness" (else zero) [.sideOutputLateData(...)]<- optional: "output tag"(else no side output for late data) .reduce/aggregate/apply() <- required: "function" [.getSideOutput(...)] <- optional: "output tag"
Flink的窗口
翻滚窗口
input.keyBy().window(TumblingEventTimeWindows.of(Time.seconds(5))).();
滑动窗口
input.keyBy().window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5))).();
会话窗口
// event-time session windows with static gapinput.keyBy().window(EventTimeSessionWindows.withGap(Time.minutes(10))).();
// event-time session windows with dynamic gapinput.keyBy().window(EventTimeSessionWindows.withDynamicGap((element)->{//determine and return session gap})).();
全局窗口
input.keyBy().window(GlobalWindows.create()).();
窗口函数:
ReduceFunction: 增量聚合
input.keyBy()
.window()
.reduce(newReduceFunction>(){public Tuple2 reduce(Tuple2v1,Tuple2 v2){
Returnnew Tuple2<>(v1.f0,v1.f1+v2.f1);
}
});
AggregateFunction: 增量聚合
/**
* The accumulatoris used to keep a running sum and a count. The {@code getResult} method
* computes theaverage.
*/
private static class AverageAggregate
implementsAggregateFunction, Tuple2,Double> {
@Override
publicTuple2 createAccumulator() {
return newTuple2<>(0L, 0L);
}
@Override
publicTuple2 add(Tuple2 value, Tuple2 accumulator) {
return newTuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public DoublegetResult(Tuple2 accumulator) {
return ((double)accumulator.f0) / accumulator.f1;
}
@Override
publicTuple2 merge(Tuple2 a, Tuple2 b) {
return newTuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
DataStream> input = ...;
input
.keyBy()
.window()
.aggregate(newAverageAggregate());
ProcessWindowFunction: 不能进行增量处理,只能等窗口中的数据都准备好之后才进行处理
input
.keyBy(t ->t.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(newMyProcessWindowFunction());
/* ... */
public class MyProcessWindowFunction
extendsProcessWindowFunction, String, String,TimeWindow> {
@Override
public voidprocess(String key, Context context, Iterable>input, Collector out) {
long count = 0;
for(Tuple2 in: input) {
count++;
}
out.collect("Window: " + context.window() + "count:" + count);
}
}
ReduceFunction和ProcessWindowsFunction可以组合使用:
input
.keyBy()
.window()
.reduce(newMyReduceFunction(), new MyProcessWindowFunction());
// Function definitions
private static class MyReduceFunction implementsReduceFunction {
publicSensorReading reduce(SensorReading r1, SensorReading r2) {
returnr1.value() > r2.value() ? r2 : r1;
}
}
private static class MyProcessWindowFunction
extendsProcessWindowFunction,String, TimeWindow> {
public voidprocess(String key,
Context context,
Iterable minReadings,
Collector> out) {
SensorReadingmin = minReadings.iterator().next();
out.collect(new Tuple2(context.window().getStart(),min));
}
}
AggregateFunction和ProcessWindowFunction可以组合使用。
ProcessWindowFunction中的状态使用:
- globalState(),它允许访问不在窗口范围内的键控状态
- windowState(),它允许访问同样作用于窗口的键控状态
Triger
triger用于确认窗口什么时候应该可以被窗口函数处理。每个WindowAssigner都有一个默认的Trigger. 如果默认触发器不符合您的需要,您可以使用 指定自定义触发器trigger(...)。
触发器接口有五种方法可以Trigger对不同的事件做出反应:
- onElement()为添加到窗口的每个元素调用该方法。
- onEventTime()当注册的事件时间计时器触发时调用该方法。
- onProcessingTime()当注册的处理时间计时器触发时调用该方法。
- 该onMerge()方法与有状态触发器相关,并在两个触发器的相应窗口合并时合并两个触发器的状态,例如在使用会话窗口时。
最后,该clear()方法执行移除相应窗口时所需的任何操作。
注意:
- onElement()、onEventTime()和onProcessingTime()可以返回TrigerResult来确定是否进行触发计算操作
- CONTINUE: 没做什么,
- FIRE: 触发计算,
- PURGE: 清除窗口中的元素,
- FIRE_AND_PURGE: 触发计算,然后清除窗口中的元素。
- 上面所有的方法都可用于注册处理时间或事件时间定时器以供将来操作。
Flink预定义的触发器:
- EventTimeTrigger基于由watermark测量的事件时间的进度触发。
- ProcessingTimeTrigger基于处理时间的触发。
- CountTrigger一旦窗口中的元素数量超过给定的限制,就会触发。
- 将PurgingTrigger另一个触发器作为参数并将其转换为清除触发器。
Evictor
evicetor有两个分别实现的方法:
- void evictBefore(Iterable> elements, int size, W window, EvictorContext evictorContext);
在窗口函数调用之前被调用
- void evictAfter(Iterable> elements, int size, W window, EvictorContext evictorContext);
在窗口函数执行之后被调用
Flink中预先实现的evictor有:
- CountEvictor: 保持窗口中用户指定数量的元素,并从窗口缓冲区的开头丢弃剩余的元素。
- DeltaEvictor: 取 aDeltaFunction和 a threshold,计算窗口缓冲区中最后一个元素与其余每个元素之间的差值,并删除差值大于或等于阈值的元素。
- TimeEvictor: 以interval毫秒为单位作为参数,对于给定的窗口,它会max_ts在其元素中找到最大时间戳,并删除所有时间戳小于 的元素max_ts - interval。
指定一个 evictor 则会停止任何预聚合(即使是增量聚合,因为需要在窗口函数之后执行evictor操作,所以不能预聚合),因为在应用计算之前必须将窗口的所有元素传递给 evictor。这意味着带有驱逐器的窗口将创建更多的状态。
Allowed lateness
input
.keyBy()
.window()
.allowedLateness()
.();
默认情况下watermark超过窗口的结束时间戳之后将会清除窗口的元素,但是可以通过设置allowedLateness允许窗口触发之后,延迟指定的时间再次触发执行。注意这意味着对于同一个数据计算将会有多个结果,而延迟触发计算则是对前一次触发计算的结果的更新。
当使用GlobalWindows窗口分配器时,没有数据被认为是延迟的,因为全局窗口的结束时间戳是Long.MAX_VALUE。
获取延迟的数据,并且通过侧流输出将延迟的数据输出出去:
final OutputTag lateOutputTag = newOutputTag("late-data"){};
DataStream input = ...;
SingleOutputStreamOperator result = input
.keyBy()
.window()
.allowedLateness()
.sideOutputLateData(lateOutputTag)
.();
DataStream lateStream =result.getSideOutput(lateOutputTag);
TimeService
两种类型的计时器(处理时间和事件时间)都由 内部维护TimerService并排队执行。
TimerService每个key和时间戳的重复数据删除定时器,即每个密钥和时间戳最多有一个定时器。如果为同一个时间戳注册了多个计时器,则该onTimer()方法将只调用一次。
Flink 同步onTimer()和 的调用processElement()。因此,用户不必担心状态的并发修改。
Flink部署On K8s
- 首先需要保证k8s默认的default的serviceAccount需要有创建和销毁pod的edit权限, 没有的话则需要 kubectl create clusterrolebinding flink-role-binding-default --clusterrole=edit --serviceaccount=default:default 赋予edit的权限。
或者创建新的serviceAccount账号, 如下创建了一个名为flink的default命名空间下的serviceAccount:
kubectl create serviceaccount flink
kubectl create clusterrolebindingflink-role-binding-flink --clusterrole=edit --serviceaccount=default:flink
- 校验配置的./kube/config对应的用户是否有权限创建pod,kubectl auth can-i pods
Session模式
-
- 首先启动一个session集群
/usr/local/flink-1.14.0/bin/kubernetes-session.sh \
-Dkubernetes.cluster-id=session-cluster-1 \
-Dtaskmanager.numberOfTaskSlots=2 \
-Dresourcemanager.taskmanager-timeout=3600000 \
-Dkubernetes.rest-service.exposed.type=NodePort \
-Dkubernetes.service-account=flink\
-Djobmanager.memory.process.size=1024M \
-Dtaskmanager.memory.flink.size=1024M \
-Dkubernetes.jobmanager.cpu=1 \
-Dkubernetes.taskmanager.cpu=2 \
-Dexecution.attached=true \ # session集群的启动方式分为dettached和attached两种方式
-Dkubernetes.container.image=flink:scala_2.11-java8
-
- 然后启动客户端端向集群提交job
/usr/local/flink-1.14.0/bin/flink run \
--targetkubernetes-session \
-Dkubernetes.cluster-id=session-cluster-1 \
/usr/local/flink-1.14.0/examples/streaming/TopSpeedWindowing.jar
-
- 停止session集群
kubectl delete deployment/session-cluster-1
Application模式
-
- 首先需基于flink的镜像构建用户的自定义代码镜像, 以下是Dockerfile文件内容
FROM apache/flink:1.14.0-scala_2.11
RUN mkdir -p /opt/flink/usrlib
COPY TopSpeedWindowing.jar /opt/flink/usrlib/TopSpeedWindowing.jar
然后基于Dockerfile构建镜像:
docker build -t flink/myfirstjob -f ./Dockerfile .
注意: -f 后的第一个是Dockerfile的文件路径, 第二个路径表示镜像构建的上下文路径, 这个路径会影响ADD COPY等命令的文件路径上下文
-
- 开始提交任务到k8s集群上
/usr/local/flink-1.14.0/bin/flink run-application \
--targetkubernetes-application \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dkubernetes.container.image=flink/myfirstjob:latest \
-Djobmanager.memory.process.size=1024M \
-Dtaskmanager.memory.flink.size=1024M \
-Dkubernetes.jobmanager.cpu=1 \
-Dkubernetes.taskmanager.cpu=2 \
-Dtaskmanager.numberOfTaskSlots=2 \
local:///opt/flink/usrlib/TopSpeedWindowing.jar
-
- 任务提交后的其他的操作:
列出在集群上运行的正在运行的job
./bin/flink list --target kubernetes-application-Dkubernetes.cluster-id=my-first-application-cluster
退出正在运行的Job
./bin/flink cancel --target kubernetes-application -Dkubernetes.cluster-id=my-first-application-cluster
注意: 可以在提交任务的时候通过传递-Dkey=value的键值对来覆盖默认的conf/flink-conf.yml文件中的配置
Flink的WebUi的访问方式
- ClusterIP
在集群内部 IP 上公开服务。 该服务只能在集群内访问。 如果要访问 JobManager UI 或将作业提交到现有会话,则需要启动本地代理。 然后,您可以使用 localhost:8081 向会话提交 Flink 作业或查看页面。
kubectl port-forwardservice/ 8081
- NodePort
在静态端口(NodePort)处公开每个节点 IP 上的服务。: 可用于联系 JobManager 服务。
- LoadBalancer
使用云提供商的负载均衡器在外部公开服务。 由于云提供商和 Kubernetes 需要一些时间来准备负载均衡器,您可能会在客户端日志中看到一个 NodePort JobManagerWeb Interface。 您可以使用 kubectl getservices/-rest 获取EXTERNAL-IP 并手动构建负载均衡器 JobManager WebInterface http://:8081。
Flink的日志模式
1.通过kubectl logs -f 访问, 或者直接kubectl exec -it进入pod中查看打印的日志。
2.由于k8s默认回收空闲的TaskManager, 当TaskManager被回收之后就没法看日志了, 所以可以设置resourcemanager.taskmanager-timeout配置TaskManager超时的设置。
3.可以通过修改对应的deployment的configmap: kubectledit cm flink-config-my-first-flink-cluster。
Flink k8s高可用
// 唯一标识一个flink cluster
kubernetes.cluster-id:
// 高可用实现使用KubernetesHaServicesFactory实现
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
// 存储高可用元数据的地方
high-availability.storageDir: hdfs:///flink/recovery
// 设置HA的Owner reference, 这个一般不需要指定,系统默认生成
high-availability.cluster-id
// 设置jobmanager启动时的副本数得大于1
kubernetes.jobmanager.replicas
清理集群的时候只需要通过kubectl delete deployment , 直接删除对应的deployment, 而HA相关的ConfigMap则不会被清除, 因为Ha的ConfigMap没有设置成OwnerReference。重新启动集群时,所有之前运行的作业都将恢复并从最新成功的检查点重新启动。
Flink Zookeeper高可用
// 该high-availability选项必须设置为zookeeper.
high-availability: zookeeper
// JobManager 元数据被持久化在文件系统中high-availability.storageDir,并且只有指向该状态的指针存储在 ZooKeeper 中。
high-availability.storageDir: hdfs:///flink/recovery
// ZooKeeper quorum是 ZooKeeper 服务器的复制组,提供分布式协调服务。
high-availability.zookeeper.quorum:address1:2181[,...],addressX:2181
// ZooKeeper 的根节点,所有集群节点都放置在该节点之下。【非必须配置项】
high-availability.zookeeper.path.root: /flink
// 重要:为每个集群定制, cluster-id ZooKeeper 节点,在该节点下放置集群所需的所有协调数据。【非必须配置项】
high-availability.cluster-id:/default_ns
Note: 在 YARN、本机 Kubernetes 或其他集群管理器上运行时,不应手动设置此值。在这些情况下,会自动生成集群 ID。如果您在裸机上运行多个 Flink HA 集群,则必须为每个集群手动配置单独的集群 ID。
Flink总的内存模型

| TaskManager |
JobManager |
含义 |
| taskmanager.memory.flink.size |
jobmanager.memory.flink.size |
Jvm heap + off-heap |
| taskmanager.memory.process.size |
jobmanager.memory.process.size |
flink进程的所有的内存 |
| taskmanager.memory.task.heap.size 和 taskmanager.memory.managed.size |
jobmanager.memory.heap.size |
heap memory |
Flink之TaskManager内存模型
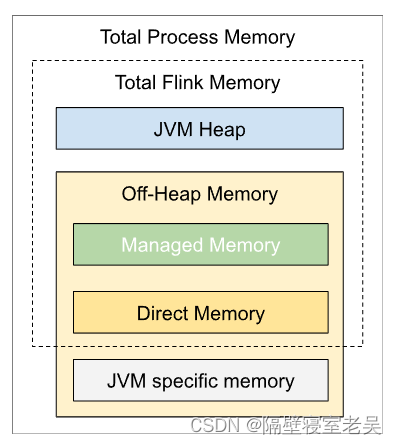
- Total Process Memory = Total Flink Memory (flink应用程序消耗的内存) + JVM specific memory(JVM运行进程所消耗的内存)
- Total Flink Memory = JVM heap + Managed Memory (flink管理的堆外内存) + Direct Memory
- 设置flink内存的方式可以只简单设置Total Process Memory的内存,那么其他的各个组件的内存将会根据默认值自动调整,或者也可以分别显式设置各个组件的内存;但是这两种方式不能同时一起设置,否则可能会冲突。
- JVM heap内存用于用户代码算子的执行。
- Managed Memory 使用场景:
- 流式作业可以将其用于 RocksDB 状态后端。
- 流和批处理作业都可以使用它来进行排序、哈希表、中间结果的缓存。
- 流作业和批处理作业都可以使用它在 Python 进程中执行用户定义的函数。

| taskmanager.memory.managed.consumer-weights |
将managed memory按照配置权重分配给不同的进程使用: · OPERATOR: for built-in algorithms. · STATE_BACKEND: for RocksDB state backend in streaming · PYTHON: for Python processes. 例如。 如果流作业同时使用 RocksDB 状态后端和 Python UDF,并且消费者权重配置为 STATE_BACKEND:70,PYTHON:30,Flink 将为 RocksDB 状态后端保留 70% 的总托管内存,为 Python 进程保留 30%。 对于每种类型,只有当作业包含该类型的托管内存消费者时,Flink 才会保留托管内存。 例如,如果流式作业使用堆状态后端和 Python UDF,并且消费者权重配置为 STATE_BACKEND:70,PYTHON:30,Flink 会将其所有托管内存用于 Python 进程,因为堆状态后端不使用 托管内存。 |
| taskmanager.memory.framework.heap.size=128Mb |
TaskExecutor 的框架堆内存大小。 这是为 TaskExecutor 框架保留的 JVM 堆内存大小,不会分配给任务槽。 |
| taskmanager.memory.task.heap.size |
TaskExecutors 的任务堆内存大小。 这是为任务保留的 JVM 堆内存大小。 如果没有指定,它将被推导出为总 Flink 内存减去框架堆内存、框架堆外内存、任务堆外内存、托管内存和网络内存。 |
| taskmanager.memory.task.off-heap.size=0byte |
由用户代码分配的堆外内存应计入任务堆外内存 |
| taskmanager.memory.managed.size taskmanager.memory.managed.fraction=0.4 |
TaskExecutors 的托管内存大小。 这是内存管理器管理的堆外内存的大小,保留用于排序、哈希表、中间结果缓存和 RocksDB 状态后端。 内存使用者可以以 MemorySegments 的形式从内存管理器分配内存,或者从内存管理器保留字节并将其内存使用保持在该边界内。 如果未指定,它将被派生以构成总 Flink 内存的配置部分。 |
| taskmanager.memory.framework.off-heap.size=128Mb |
TaskExecutor 的框架堆外内存大小。 这是为 TaskExecutor 框架保留的堆外内存(JVM 直接内存和本机内存)的大小,不会分配给任务槽。 Flink 计算 JVM 最大直接内存大小参数时将完全统计配置的值。 |
| taskmanager.memory.task.off-heap.size=0byte |
TaskExecutor 的任务堆外内存大小。 这是为任务保留的堆外内存(JVM 直接内存和本机内存)的大小。 Flink 计算 JVM 最大直接内存大小参数时将完全统计配置的值。 |
| taskmanager.memory.network.min=64Mb taskmanager.memory.network.max=1Gb taskmanager.memory.network.fraction=0.1 |
TaskExecutors 的网络内存大小。 网络内存是为 ShuffleEnvironment 保留的堆外内存(例如,网络缓冲区)。 导出网络内存大小以构成总 Flink 内存的配置部分。 如果派生大小小于/大于配置的最小/最大大小,则将使用最小/最大大小。 网络内存的确切大小可以通过将最小值/最大值设置为相同的值来明确指定。 |
| taskmanager.memory.jvm-metaspace.size=256Mb |
TaskExecutor 的 JVM 元空间大小。 |
| taskmanager.memory.jvm-overhead.min=192Mb taskmanager.memory.jvm-overhead.max=1Gb taskmanager.memory.jvm-overhead.fraction=0.1 |
TaskExecutor 的JVM 开销大小。 这是为JVM开销预留的堆外内存,例如线程栈空间、编译缓存等。这包括native memory但不包括direct memory,在Flink计算JVM max direct memory size参数时不会计算在内。 JVM 开销的大小被派生为构成总进程内存的配置部分。 如果派生大小小于/大于配置的最小/最大大小,则将使用最小/最大大小。 JVM Overhead 的确切大小可以通过将最小/最大大小设置为相同的值来明确指定。 |
Flink之JobManager内存模型
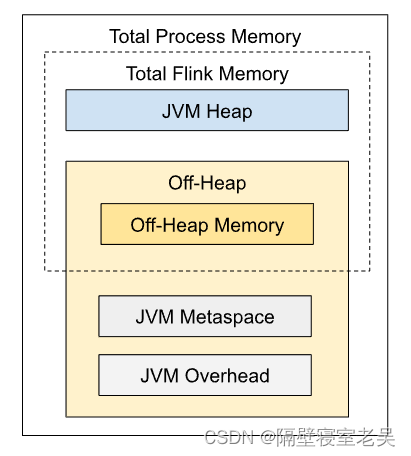
| JVM Heap |
jobmanager.memory.heap.size=128Mb |
JobManager 的 JVM 堆内存大小。 建议的最小 JVM 堆大小为 128.000mb(134217728 字节)。 堆内存用于: · Flink 框架 · 在作业提交期间(例如,对于某些批处理源)或在检查点完成回调中执行的用户代码 如果你已经明确配置了JVM Heap,建议不要设置total process memory和total Flink memory。否则容易导致内存配置冲突。 |
|
| Off-heap |
|
JobManager 的堆外内存大小。 此选项涵盖所有堆外内存使用,包括直接和本机内存分配。 如果通过'jobmanager.memory.enable-jvm-direct-memory-limit'启用限制,则JobManager进程的JVM直接内存限制(-XX:MaxDirectMemorySize)将设置为此值。 堆外内存用于: · Flink 框架依赖(例如 Akka 网络通信) · 在作业提交期间(例如,对于某些批处理源)或在检查点完成回调中执行的用户代码 如果你已经配置了total process memory 和total Flink memory明确,但你有没有配置off-heap内存,off-heap内存大小会被推断为total process memory - total Flink memory。Off-heap memory 选项的默认值将被忽略。 |
|
| JVM metaspace |
jobmanager.memory.jvm-metaspace.size= 256 mb |
JobManager 的 JVM 元空间大小。 |
|
| JVM Overhead |
jobmanager.memory.jvm-overhead.min= 192 mb jobmanager.memory.jvm-overhead.max=1Gb jobmanager.memory.jvm-overhead.fraction=0.1 |
JobManager 的 JVM 开销大小。 这是为JVM开销预留的堆外内存,例如线程栈空间、编译缓存等。这包括native memory但不包括direct memory,在Flink计算JVM max direct memory size参数时不会计算在内。 JVM 开销的大小被派生为构成总进程内存的配置部分。 如果派生大小小于或大于配置的最小或最大大小,则将使用最小或最大大小。 JVM Overhead 的确切大小可以通过将最小和最大大小设置为相同的值来明确指定。 |
Flink内存调优指南
| Standalone部署 |
建议为standalone部署设置total Flink memory (taskmanager.memory.flink.size或jobmanager.memory.flink.size)或者各个组件的内存 |
| 容器部署 |
建议为容器化部署(Kubernetes或Yarn)配置total Flink memory(taskmanager.memory.process.size or jobmanager.memory.process.size),它声明了总共应该分配多少内存给 Flink JVM 进程,并对应于请求容器的大小。 |
| HashMapStateBackend |
运行无状态作业或使用HashMapStateBackend 时,将managed memory设置为零。这将确保为 JVM 上的用户代码分配最大数量的堆内存。 |
| RocksDB state backend |
EmbeddedRocksDBStateBackend 使用native memory。 默认情况下,RocksDB 设置为将native memory分配限制为managed memory的大小。 因此,为您的状态保留足够的managed memory非常重要。 如果禁用默认的 RocksDB 内存控制,RocksDB 分配的内存超过请求的容器大小(总进程内存)的限制,则 taskmanager可能会在容器化部署中被终止。 |
| Batch Job |
Flink 的批处理操作符利用托管内存来更高效地运行。这样做时,可以直接对原始数据执行某些操作,而无需反序列化为 Java 对象。这意味着托管内存配置对应用程序的性能有实际影响。Flink 将尝试分配和使用 为批处理作业配置的尽可能多的托管内存,但不会超出其限制。这可以防止OutOfMemoryError's,因为 Flink 准确地知道它必须利用多少内存。如果托管内存不足,Flink 会优雅地溢出到磁盘。 |
程序执行配置
| setClosureCleanerLevel() |
默认情况下,闭包清理器级别设置为 ClosureCleanerLevel.RECURSIVE。 闭包清理器删除了对 Flink 程序中周围匿名函数类的不需要的引用。 禁用闭包清理器后,可能会发生匿名用户函数引用周围类的情况,该类通常不可序列化。 这将导致序列化程序出现异常。 设置为:NONE:完全禁用闭包清理器,TOP_LEVEL:只清理顶级类而不递归到字段,RECURSIVE:递归清理所有字段。 |
| getParallelism() 或 setParallelism(int parallelism) |
设置作业的默认并行度。 |
| getMaxParallelism() setMaxParallelism(int parallelism) |
设置作业的默认最大并行度。 此设置确定最大并行度并指定动态缩放的上限。 |
| getNumberOfExecutionRetries() setNumberOfExecutionRetries(int numberOfExecutionRetries) |
设置重新执行失败任务的次数。 零值有效地禁用容错。 值 -1 表示应使用系统默认值(在配置中定义)。 这已被弃用,请改用重启策略。 |
| getExecutionRetryDelay() / setExecutionRetryDelay(long executionRetryDelay) |
设置作业失败后系统在重新执行之前等待的延迟(毫秒)。 延迟在 TaskManager 上成功停止所有任务后开始,一旦延迟过去,任务将重新启动。 此参数对于延迟重新执行很有用,以便在尝试重新执行并由于相同的问题立即再次失败之前让某些与超时相关的故障完全浮出水面(例如尚未完全超时的断开连接)。 此参数仅在执行重试次数为一次或多次时才有效。 这已被弃用,请改用重启 策略。 |
| getExecutionMode() / setExecutionMode() |
默认执行模式是pipeline 设置执行模式以执行程序。 执行模式定义数据交换是以批处理方式执行还是以pipeline方式执行。 |
| enableForceKryo() / disableForceKryo |
默认情况下不强制使用 Kryo。 强制 GenericTypeInformation 对 POJO 使用 Kryo 序列化程序,即使我们可以将它们分析为 POJO。 在某些情况下,这可能更可取。 例如,当 Flink 的内部序列化程序无法正确处理 POJO 时。 |
| enableForceAvro() / disableForceAvro() |
默认情况下不强制执行 Avro。 强制 Flink AvroTypeInfo 使用 Avro 序列化程序而不是 Kryo 来序列化 Avro POJO。 |
| enableObjectReuse() / disableObjectReuse() |
默认情况下,Flink 中不会重用对象。 启用对象重用模式将指示运行时重用用户对象以获得更好的性能。 请记住,当操作的用户代码功能不知道此行为时,这可能会导致错误。 |
| getGlobalJobParameters() / setGlobalJobParameters() |
此方法允许用户将自定义对象设置为作业的全局配置。 由于 ExecutionConfig 可在所有用户定义的函数中访问,因此这是一种使配置在作业中全局可用的简单方法。 |
| addDefaultKryoSerializer(Class type, Serializer serializer) |
为给定类型注册一个 Kryo 序列化程序实例。 |
| addDefaultKryoSerializer(Class type, Class> serializerClass) |
为给定类型注册一个 Kryo 序列化程序类。 |
| registerTypeWithKryoSerializer(Class type, Serializer serializer) |
向 Kryo 注册给定类型并为其指定序列化程序。 通过向 Kryo 注册类型,类型的序列化将更加高效。 |
| registerKryoType(Class type) |
如果类型最终被 Kryo 序列化,那么它将在 Kryo 注册以确保只写入标签(整数 ID)。 如果一个类型没有在 Kryo 中注册,它 的整个类名将与每个实例一起序列化,从而导致更高的 I/O 成本。 |
| registerPojoType(Class type) |
向序列化堆栈注册给定类型。 如果该类型最终被序列化为 POJO,则该类型将注册到 POJO 序列化程序。 如果类型最终被 Kryo 序列化,那么它将在 Kryo 注册以确保只写入标签。 如果一个类型没有在 Kryo 中注册,它的整个类名将与每个实例一起 序列化,从而导致更高的 I/O 成本。 |
| disableAutoTypeRegistration() |
默认情况下启用自动类型注册。 自动类型注册是使用 Kryo 和 POJO 序列化程序注册用户代码使用的所有类型(包括子类型)。 |
| setTaskCancellationInterval(long interval) |
设置在连续尝试取消正在运行的任务之间等待的时间间隔(以毫秒为单位)。 当任务被取消时,如果任务线程在一定时间内没有终止,则会创建一个新线程,该线程会定期在任务线程上调用 interrupt()。 该参数是指连续调用interrupt()之间的时间,默认设置为30000毫秒,即30秒。 |
并行度设置
- 算子级别设置并行度
final StreamExecutionEnvironmentenv = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamtext = [...]
DataStream> wordCounts = text
.flatMap(new LineSplitter())
.keyBy(value -> value.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum(1).setParallelism(5);
wordCounts.print();
env.execute("WordCount Example");
- 执行环境级别
finalStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
DataStream text = [...]
DataStream>wordCounts = [...]
wordCounts.print();
env.execute("Word Count Example");
-
- 客户级别
./bin/flinkrun -p 10 ../examples/*WordCount-java*.jar
try {
PackagedProgram program = newPackagedProgram(file, args);
InetSocketAddress jobManagerAddress =RemoteExecutor.getInetFromHostport("localhost:6123");
Configuration config = new Configuration();
Client client = newClient(jobManagerAddress, config, program.getUserCodeClassLoader());
// set the parallelism to 10 here
client.run(program, 10, true);
} catch(ProgramInvocationException e) {
e.printStackTrace();
}
-
- 系统级
parallelism.default可以通过在 中设置属性来定义所有执行环境的系统范围的默认并行度 ./conf/flink-conf.yaml
-
- 最大并行度
128 <=operatorParallelism + (operatorParallelism / 2) <= 32768
Fllink运行中的组件
REST
REST是JobManager暴露给外部的服务,主要为客户端和前端提供http服务。其中WebMonitorEndpoint是核心类,MiniDispatcherRestEndpoint是Per-job模式的实现,DispatcherRestEndpoint是作为Session模式的实现。

WebMonitorEndpoint的启动过程
-
- 初始化处理外部请求的handler
-
- MiniDispatcherRestEndpoint和DispatcherRestEndpoint的构造函数中,会调用WebMonitorEndpoint的构造函数,WebMonitorEndpoint的构造函数会调用RestServerEndpoint的构造函数实例化对象。
- DefaultDispatcherResourceManagerComponentFactory会启动JobManager运行中所需的所有的组件(dispatcher,resourceManager,restEndpoint等), 会调用RestServerEndpoint.start()函数进行初始化handler等操作。
- 将处理外部请求Handler注册到路由器(Router)
-
- 遍历handlers将所有的handler注册到到Router中
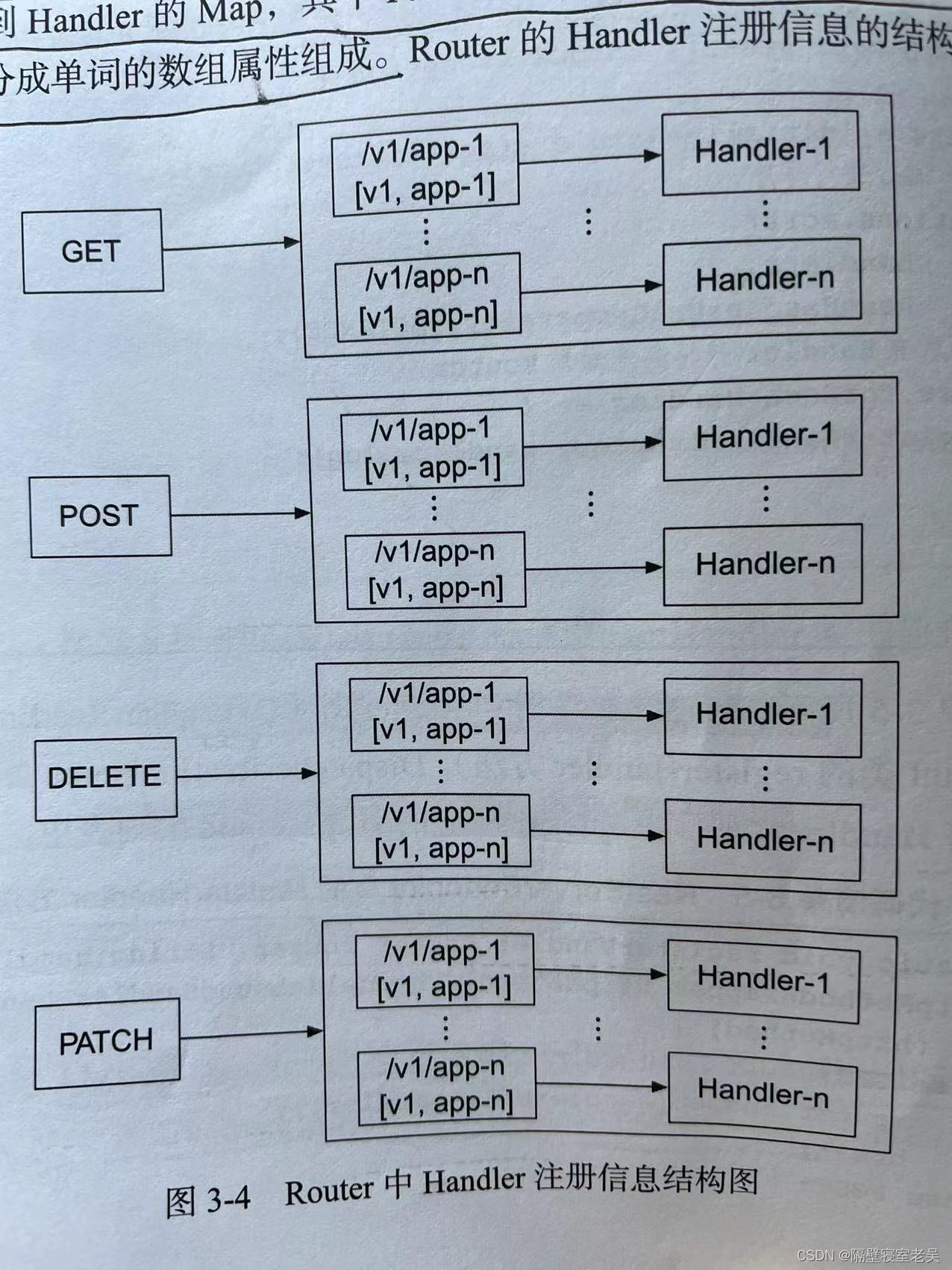
- Router类的handler注册信息是一个嵌套的Map结构, Router的routers(Router类的Handler注册信息)是一个HttpMethod映射到MethodlessRouter的Map(Map),而MethodlessRouter中的routes属性是一个PathPattern映射到Handler的Map, 其中PathPattern由请求URL的path全路径和path基于分隔符拆分成单词的数组属性组成。
-
- 创建并启动NettyServer和初始化处理channel
-
- HttpServerCodec:负责Http消息的解码和编码
- FileUploadHandler:负责处理文件上传
- FlinkHttpObjectAggregator:继承HttpObjectAggregator,负责将多个Http消息组装成一个完整的Http请求或者Http响应
- ChunkedWriteHandler:负责大的数据流处理,比如查看TaskManager/JobManager的日志和标准输出的Handler的处理
- RouterHandler: REST服务暴露的核心,会根据URL路由到正确的Handlerjin进行相应的逻辑处理
- PipelineErrorHandler:负责记录异常日志,并返回HTTP异常响应。只有前面五部分因异常情况没有发送HTTP响应,才会执行到PipelineErrorHandler
- 启动leader选举
Dispatcher
Dispatcher负责作业的提交、对作业进行持久化、产生新的JobMaster执行作业、在JobManager节点崩溃时恢复所有的作业的执行,以及管理作业对应的JobMaster状态。其中MiniDispatcher作为Per-Job模式实现,StandaloneDispatcher是作为Session模式的实现。
Dispatcher接收到REST提交作业的消息后处理过程如下:
-
- 检查作业是否重复,防止一个作业在JobManager进程中被多次调度运行。 判断作业是否执行过或者作业是否正在执行中。
- 执行该作业前一次运行未完成的终止逻辑(同一个JobId的作业)
- 持久化作业的JobGraph
- 创建JobManagerRunner
- JobManagerRunner构建JobMaster用来负责作业的运行
- 启动JobManagerRunner
ResourceManager
ResourceManager组件负责资源的分配与释放,以及资源状态的管理。
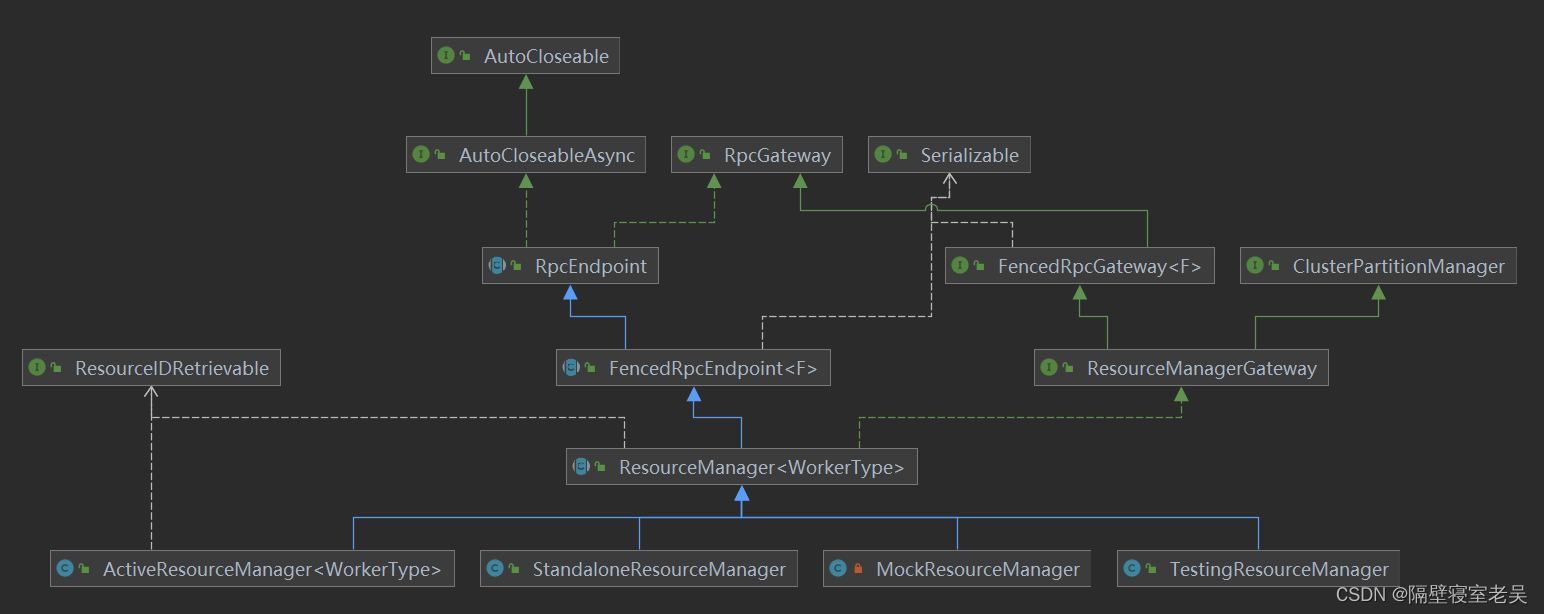
ResourceManager与其他组件的通信主要有以下几种:
-
- REST组件通过Dispatcher透传或者直接与ResourceManager通信来获取TaskExecutor的详细信息、集群的资源情况、TaskExecutor Metric查询服务的信息、TaskExecutor的日志和标志输出。
- JobMaster与ResourceManager的交互主要体现在申请Slot、释放Slot、将JobMaster注册到ResourceManager,以及组件之间的心跳。
- TaskExecutor与ResourceManager的交互主要是将TaskExecutor注册到ResourceManager、汇报TaskExecutor上Slot情况,以及组件之前心跳通信。
对于资源Slot,在TaskExecutor上以Slot逻辑单元对TaskManager资源(资源CPU、内存等)进行划分,供作业调度;在JObMaster和ResourceManager上维护与TasExecutor的Slot的映射关系,JObManager通过SlotPool来管理运行作业的Slot,ResourceManager通过SlotManager来管理TaskManage注册过来的Slot,供多个JobMaster的SlotPool来申请和分配。
申请Slot的过程图

-
- JobMaster会根据Task的调度按需向ResourceManager发出申请Slot的请求
- ResourceManager根据自身注册TaskManager的Slot空闲情况进行处理:TaskManager的空闲Slot资源充足时,直接往对应的TaskManager发起申请占有Slot的请求;不够时则先向各种部署模式(Standalone/k8s/yarn)申请TaskManager
- 各种部署模式的资源管理中心根据ResourceManager申请TaskManager资源的规格,分配并启动TaskManager
- 启动的TaskManager会注册到ResourceManager,注册成功后,TaskManager汇报自身的Slot情况(TaskManager汇报Slot的过程)
- ResourceManager根据TaskManager汇报Slot的情况向TaskManager申请占有Slot(ResourceManager申请占有Slot的过程)
- TaskManager根据申请占有Slot的信息中的作业信息注册对应的JobMaster,并将Slot提供给JobMaster调用分配Task(offSlot过程)
SlotManager
SlotManager维护和注册来自TaskManager的Slot,并处理来自JobMaster的Slot申请。
-
- 申请Slot与分配:
-
- 检测Slot申请是否有效
- 匹配SlotManager空闲的Slot(TaskManagerSlot)和待完成资源申请的Slot请求(PendingTaskManager),即Slot与待完成资源申请的Slot请求匹配过程
- 申请TaskManager资源或者分配空闲的Slot(TaskManagerSlot)(申请资源与分配过程)
- Slot的注册与分配
-
- 启动的TaskManager会注册到ResourceManager,同事将其Slot信息汇报给ResourceManager,而汇报的Slot由SlotManager来分配。
- ResourceManager接收到TaskManager的Slot汇报情况的处理过程是:判断发送该TaskManager是否已经注册到ResourceManager,如果未注册,返回异常,反之执行SlotManager处理Slot注册与分配的逻辑。
- SlotManager处理TaskManager注册的逻辑是:首先检查驻车的TaskManager是否是首次注册,如果非首次驻车,则直接汇报TaskManagerSlot的状态,最终跟小滚TaskManagerSlot的状态。如果是首次注册则注册TaskManager,并且注册所有汇报的TaskManagerSlot,然后执行分配Slot的操作。
- 注册TaskManagerSlot的操作为: 检测该Slot是否已经被注册过,如果是则从已注册的列表中移除老的注册的Slot,然后创建新的TaskManagerSlot添加到列表中。然后执行Slot的状态转换操作。
JobMaster

主要负责单个作业的执行。JobMaster实现了FencedRpcEndpoint类,来实现带Token(Fencing Token)检查的RpcEndpoint;JobMaster类实现了JobMasterGateway接口,来提供其他组件调用的Rpc方法,JobMatser类实现JobMasterService接口,来供JobMasterRunner调用。
JobManangerRunner负责JobMaster的创建与启动,以及与JobMaster Leader选举相关的处理。在JobMaster中,最核心的组件为Scheduler和CheckpointCoordinator。其中Scheduler负责作业执行图(ExecutionGraph)调度,而CheckpointCoordinator负责作业检查点的协调。
JobMaster是申请Slot的流程的发起方,其中SlotPool作为作业执行图在调度时提供Slot功能以及对Slot生命周期管理,与作业一一对应(一个作业有一个SlotPool实例),其实现类为DeclarativeSlotPoolBridge。
1.发起Slot请求
-
- 查看SlotPool的空闲列表中是否存在与任务所需资源规格相匹配的空闲Slot。存在即返回,无则存在可能触发SlotPool发起申请新Slot的逻辑。
- 申请新的Slot。判断JobMaster是否已与ResourceManager连接:如未连接,则将申请Slot的请求记录下来,等待与ResourceManager连接后再向ResourceManager发起申请申请Slot请求;如已经连接,则直接向ResourceManager发起申请新Slot的逻辑。
- 再向ResourceManager发起申请Slot的请求之前,会将该待分配Slot请求记录到待分配Slot列表中,供TaskExecutor提供的Slot绑定分配。再向ResourceManager发起请求时,会对请求因异常而失败进行处理。
2.接收来自TaskExecutor的Slot
-
- 检查汇报的TaskExecutor是否在注册的TaskExecutor列表中,如果不在,则该Slot提供失败。
- 检查汇报Slot的分配Id是否存在于已经添加到SlotPool的Slot列表(包括已分配的Slot列表allocatedSlots和可用列表availableSlots)中,如果存在检查SlotPool列表中分配ID与汇报Slot一致的Slot,是否与汇报的Slot拥有一样的SlotID。是的话返回该Slot汇报成功,即重复汇报(汇报Slot具有幂等性);否则该Slot汇报因分配ID已经被其他Slot占有而失败。
- 创建已分配Slot,从待分配的Slot请求列表匹配同样分配ID的Slot请求。如果匹配不上,则重新匹配其他待分配的Slot请求,或者将其添加到可用的Slot列表中;如果能匹配上,则接着判断该Slot请求是否已经完成分配。如果该请求未完成分配,将该Slot添加到SlotPool的已分配Slot列表中,并返回该Slot给对应作业的Task调度;否则继续匹配是否满足其他待分配的Slot请求,或者添加到可用的Slot列表中。
TaskExecutor
TaskExecutor是TaskManager的核心部分,主要负责多个Task的执行。
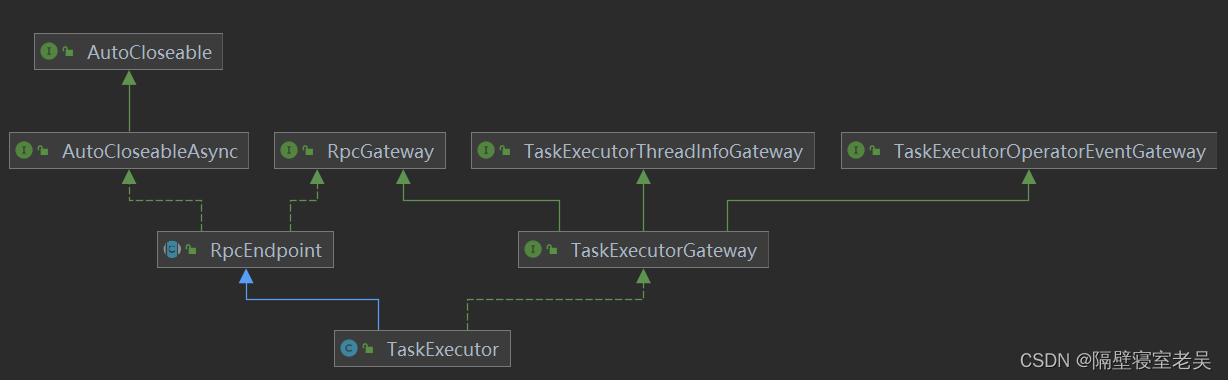
其中TaskManagerRunner是各种部署模式下TaskManager的执行入口,负责构建TaskExecutor的网络,I/O管理,内存管理,RPC服务,HA服务以及启动TaskExecutor。
TaskExecutor组件负责与ResourceManager、JobMaster通信,资源Slot的申请合汇报,Task的部署合操作及状态的变更,以及检查点相关的协调等。其中TaskExecutor与ResourceManager、JobMaster的通信时机如下:
-
- 与ResourceManager初次简历通信是在ResourceManager向部署模式申请合启动{TaskExecutor,TaskExecutor启动之后,通过HA服务监听到ResourceManager的Leader信息,主动发送消息简历联系。
- TaskExecutor与JobMaster建立通信的时机时ResourceManager向TaskExecutor申请Slot时,TaskExecutor会根据申请Slot中的作业信息,获取JobMaster的通信地址,主动发送信息建立通信,并将Slot提供给JobMaster。
TaskExecutor的单个Slot是以TaskSlot类来组织的,在TaskSlot中,记录Slot在TaskSlotTable的位置(下标)、分配情况(包括分配占有ID、分配占有Slot的作业ID以及分配在Slot上的运行任务列表)和TaskSlot的状态。
TaskSlot的状态有:
-
- Free:TaskSlot的初始状态为空闲
- Allocated:已分配状态,但是还未提供给JobMaster
- Active:活跃状态,表示TaskSlot已经提供给某个作业对应的JobMaster
- Releasing:Slot已经被调用释放但其上还存在运行种的任务,等待所有的任务被移除以变成Free的状态。
接收来自ResourceManager的Slot请求
TaskExecutor接收来自ResourceManager的Slot请求的入口方法(RPC)为requestSlot方法。
-
- 检查TaskExecutor是否与ResourceManager建立起连接,如果没有,则返回带有没有与ResourceManager建立连接的异常。
- 分配占有Slot。分配占有之前判断申请Slot的请求中的SlotID对应的Slot是否可以分配占有,判断依据是Slot是否空闲。如果是空闲的,则调用TaskSlotTable的allocateSlot方法占有Slot,占有Slot失败则返回分配Slot失败的异常。对于对应的Slot不是空闲的情况,判断slotId对应的Slot是否已经被本次的Slot请求占有(重复申请请求的情况),如果不是,则返回Slot已经被占用的异常。
- 将Slot提供给JobMaster,判断TaskExecutor是否已经与本次Slot请求对应的JobMaster建立连接(jobManagerTable中存在本次Slot申请对应的jobId)。如果已经建立,直接调用offerSlotsToJobManager方法处理将Slot提供给JobMaster的逻辑;否则通过jobLeaderService监听对应的JobMaster的首领信息后建立连接,再向对应的JobMaster提供Slot
- jobLeaderService添加监控JobMaster的首领信息失败的情况,先释放slotId对应的Slot,如果释放Slot产生异常,则TaskExecutor的对应进程会异常退出。如释放Slot未产生异常,就会接着释放申请Slot的分配ID(allocationId)对应的本地State(针对开启Local Recovery的情况)。最后对slotId对应的Slot进行是否空闲的检查。加入不空闲,则执行进程异常退出的逻辑;否则返回作业无法添加到JobLeaderService的异常。
将Slot提供给JobMaster
-
- 先检查TaskExecutor与JobMaster是否建立连接,如果已经建立连接,则从TaskSlotTable中筛选出已经被该作业占有但不处于活跃状态(Allocated)的TaskSlot。并从这些TaskSlot中提取信息来组装成Slot提供信息列表(SlotOffer列表,其中SlotOffer由AllocateID,Slot下标SlotIndex,和Slot对应的资源规格组成);然后通过向JobMaster发送SlotOffer请求将SlotOffer列表提供给JobMaster,在JobMaster接收到该SlotOffer列表后会返回一个确认接收的SlotOffer列表。
- 当接收JobMaster返回的响应后,如果发生异常,当时超时异常时,进行重试操作,当是其他异常的时候,释放掉SlotOffer列表对应的TaskSlot。当没发生异常,且返回的结果是JobMaster接收的Slot列表,检查对应的JobMaster连接是否有效;有效的话,将对应的TaskSlot由Allocate状态转为Active状态,并且移除对应的超时检查定时器。
FlinkRPC
RPC主要的部分如下:
-
- RpcEndpoint:RPC的基础类,提供远程过程调用的分布式组件需要继承这个基础类。前面提到的运行时组件Dispacther、TaskExecutor、ResourceManager和JobMaster组件都继承了RpcEndpoint。
- AkkaRpcActor:接收RpcInvocation、RunAsync、CallAsync和ControlMessages的消息来完成运行时组件中状态的安全操作。
- AkkaInvocationHandler:作为RpcAkka调用的Handler,AkkaRpcActor接收到的RunAsync、CallAsync和RpcInvocation消息都由AkkaInvocationHandler发送。
- AkkaRpcService:实现RpcService接口,负责启动AkkaRpcActor和连接到RpcEndpoint。连接到一个RpcEndpoint,会返回RpcGateway,供远程过程调用。
Note: 其中带Fenced开头的类只是多了对FencingToken的处理逻辑。
Akka消息发送模式:
-
- Ask: 发送消息异步。并返回一个Future来代表可能的消息回应。
- Tell: 一种fire-and-forget(发后即忘)的方式,发送消息异步并立即返回,无返回信息。
- forward:类似邮件的转发,将接收到的消息由一个Actor转发到另一个Actor。
AkkaRpcActor
AkkaRpcActor负责接收并处理消息,其对应的消息类型有:远程握手消息(用于在RpcEndpoint建立通信之前)、控制消息和普通消息。
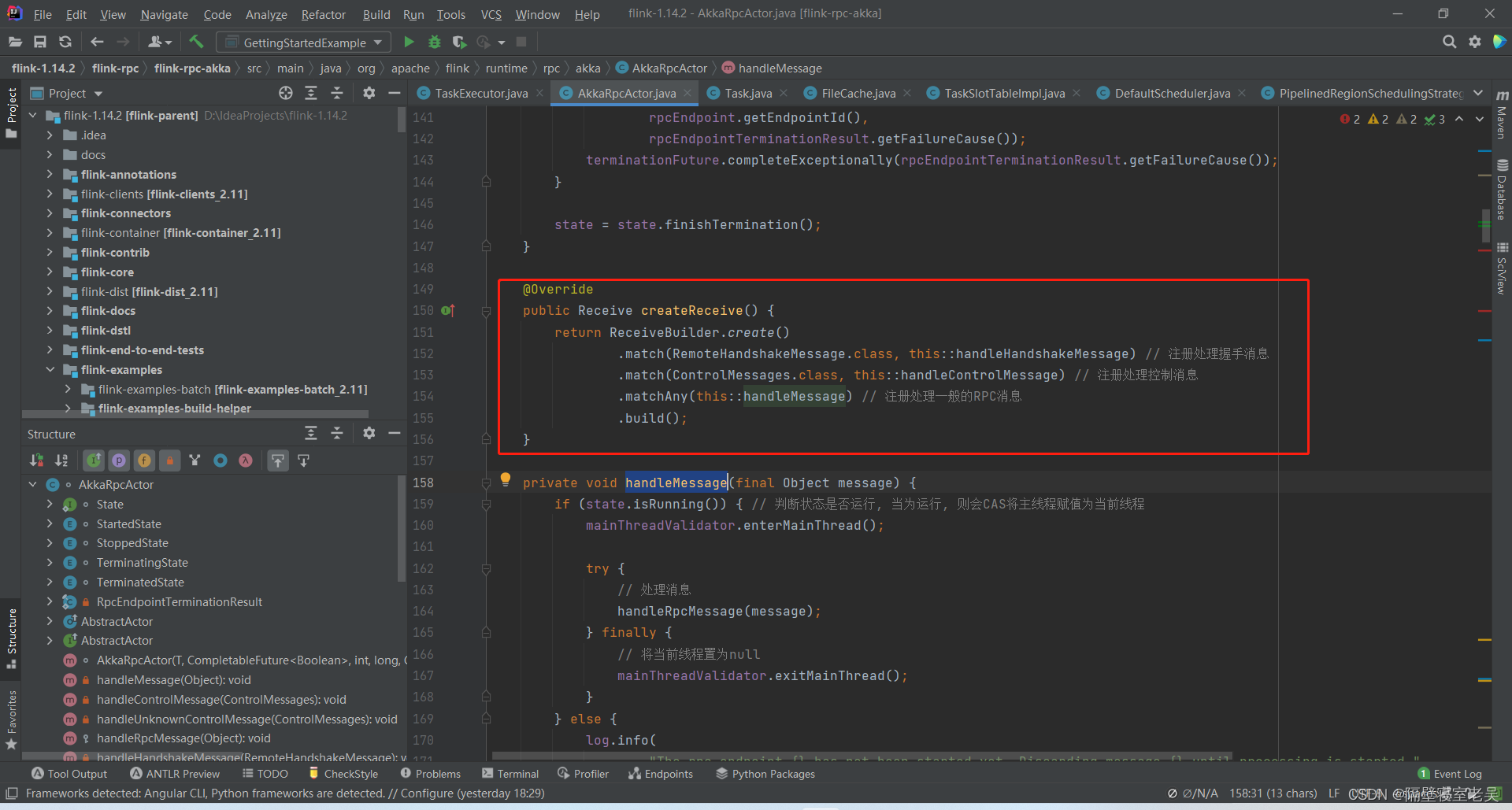
控制消息:
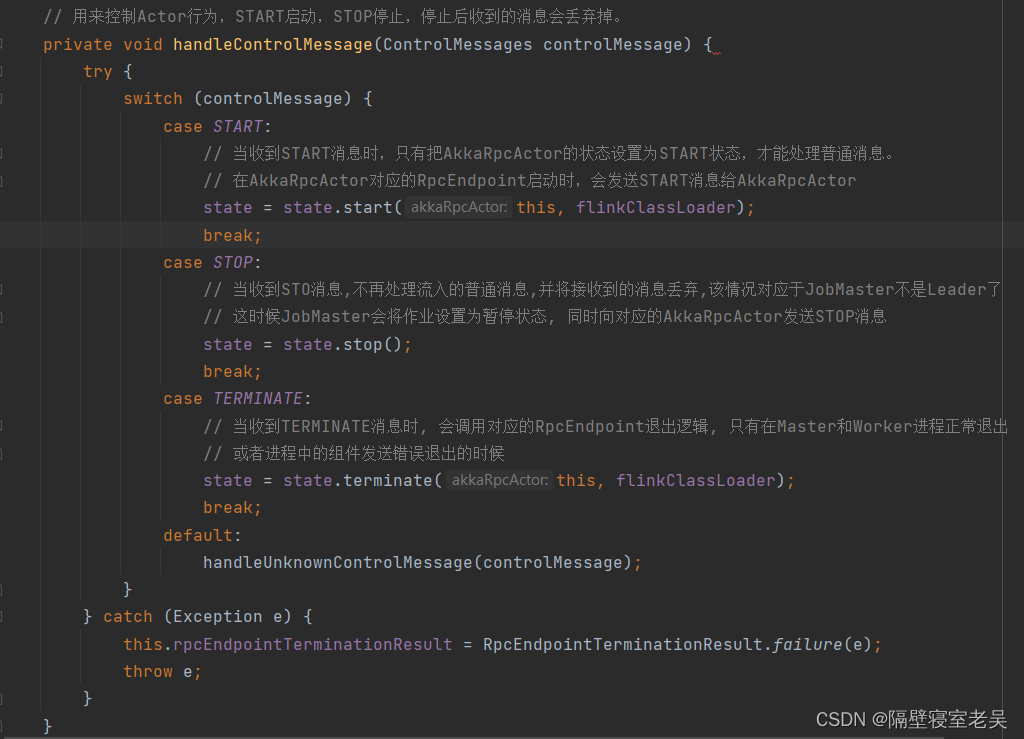
START消息:当AkkaRpcActor接收到START消息时,只有AkkaRpcActor的状态设置为开始状态,才可以处理流入的普通消息。在AkkaRpcActor对应的RpcEndpoint启动时,会发送START消息给AkkaRpcActor。
STOP消息:当AkkaRpcActor接收到STOP消息时,AkkaRpcActor处于不在流入普通消息并且将接收到的普通消息丢弃的状态。此时指挥发送JobMaster失去Leader角色的情况。在这种情况下,JobMaster会将作业设置为暂停状态,同时向其对应的AkkaRpcActor发送STOP消息。
TERMINATE消息:当AkkaRpcActor接收到TERMINATE消息时,会调用对应的RpcEndpoint的退出(onStop)逻辑。只有在Master或Worker进程正常退出或者进程中的组件发生致命错误而退出时,才会收到该消息。
普通消息:
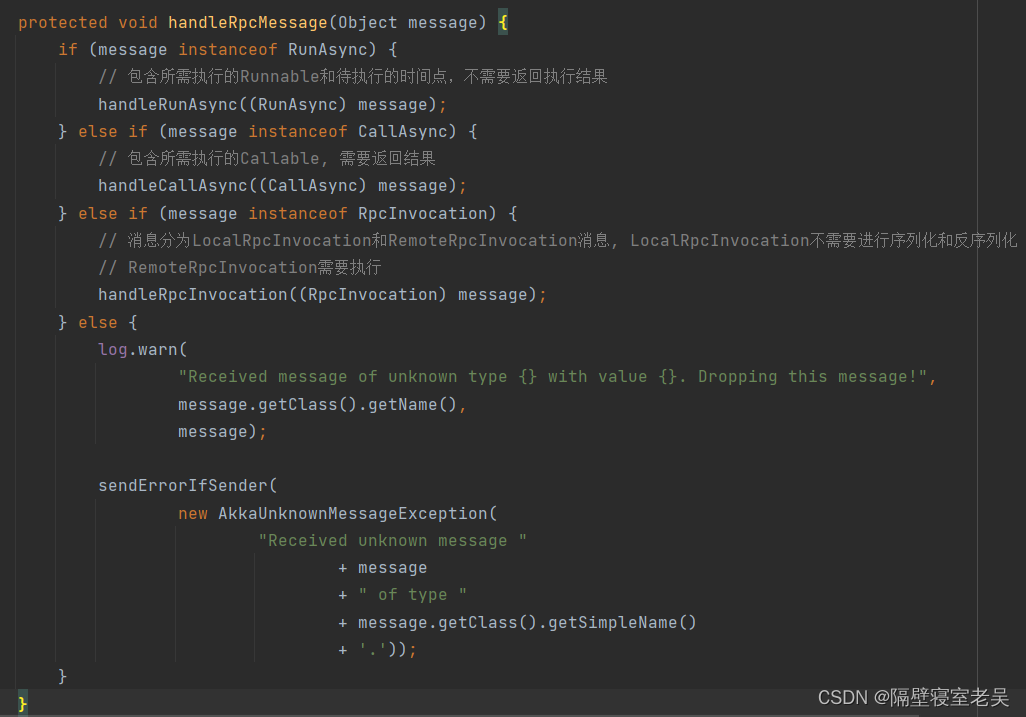
RunAsync消息:包含所需执行的Runnable和待执行的时间点,不需要返回执行结果。组件中的runAsync和scheduleRunAsync方法最终会将runAsync消息发送给AkkaRpcActor,从而线程安全地执行Runnable的run方法,修改RpcEndpoint实现类对象的状态。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
private void handleRunAsync(RunAsync runAsync) { final long timeToRun = runAsync.getTimeNanos(); final long delayNanos; if (timeToRun == 0 || (delayNanos = timeToRun - System.nanoTime()) <= 0) { // 如RunAsync中的执行时间为0或者已经早于当前时间, 立即执行RunASync中的Runnable方法 // run immediately try { runWithContextClassLoader(() -> runAsync.getRunnable().run(), flinkClassLoader); } catch (Throwable t) { log.error("Caught exception while executing runnable in main thread.", t); ExceptionUtils.rethrowIfFatalErrorOrOOM(t); } } else { // 否则将该RunAsync消息发送给AkkaRpcActor,加载到其延迟任务队列中, 等到时间一到会再次执行 // schedule for later. send a new message after the delay, which will then be // immediately executed FiniteDuration delay = new FiniteDuration(delayNanos, TimeUnit.NANOSECONDS); RunAsync message = new RunAsync(runAsync.getRunnable(), timeToRun); final Object envelopedSelfMessage = envelopeSelfMessage(message); getContext() .system() .scheduler() .scheduleOnce( delay, getSelf(), envelopedSelfMessage, getContext().dispatcher(), ActorRef.noSender()); } } |
CallAsync消息:闹含所需执行的Callable,需要返回执行结果。调用CallAsync方法会触发客户端以Ask模式将CallAync消息发送给AkkaActor。
| 1 2 3 4 5 6 7 8 9 10 11 12 |
private void handleCallAsync(CallAsync callAsync) { try { // 执行callAsync中的callable任务, 并将执行结果返回给CallAsync消息的发送方 Object result = runWithContextClassLoader( () -> callAsync.getCallable().call(), flinkClassLoader); getSender().tell(new Status.Success(result), getSelf()); } catch (Throwable e) { getSender().tell(new Status.Failure(e), getSelf()); } } |
RpcInvocation消息:其分为LocalRpcInvocation和RemoteRpcInvocation消息,二者的区别是:LocalRpcInvocation用于本地Actor之间的Rpc,不需要消息的序列化和反序列化,用于Master上运行时组件间的通信(如ResourceManager与JobMaster的通信);RemoteRpcInvocation用于Actor远程通信中的Rpc,需序列化和反序列化,用于Master组件与Worker组件的远程通信(如JobMaster与TaskExecutor的通信)。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
private void handleRpcInvocation(RpcInvocation rpcInvocation) { Method rpcMethod = null; try {// 得到传递的方法名和参数类型信息等 String methodName = rpcInvocation.getMethodName(); Class[] parameterTypes = rpcInvocation.getParameterTypes(); // 遍历该RpcEndpoint得到对应的方法, 所以需要继承RpcEndpoint实现方法来实现Rpc调用 rpcMethod = lookupRpcMethod(methodName, parameterTypes); } catch (ClassNotFoundException e) { log.error("Could not load method arguments.", e); RpcConnectionException rpcException = new RpcConnectionException("Could not load method arguments.", e); getSender().tell(new Status.Failure(rpcException), getSelf()); } catch (IOException e) { log.error("Could not deserialize rpc invocation message.", e); RpcConnectionException rpcException = new RpcConnectionException("Could not deserialize rpc invocation message.", e); getSender().tell(new Status.Failure(rpcException), getSelf()); } catch (final NoSuchMethodException e) { log.error("Could not find rpc method for rpc invocation.", e); RpcConnectionException rpcException = new RpcConnectionException("Could not find rpc method for rpc invocation.", e); getSender().tell(new Status.Failure(rpcException), getSelf()); } if (rpcMethod != null) { try { // this supports declaration of anonymous classes // 这支持匿名类的声明 rpcMethod.setAccessible(true); final Method capturedRpcMethod = rpcMethod; if (rpcMethod.getReturnType().equals(Void.TYPE)) { // No return value to send back // 当返回类型是Void类型时,直接通过反射执行查找到的方法,如果正常执行(执行过程中没有异常),不回复任何消息给RpcInvocation消息的发送者 runWithContextClassLoader( () -> capturedRpcMethod.invoke(rpcEndpoint, rpcInvocation.getArgs()), flinkClassLoader); } else { // 有返回值 final Object result; try { result = runWithContextClassLoader( () -> capturedRpcMethod.invoke( rpcEndpoint, rpcInvocation.getArgs()), flinkClassLoader); } catch (InvocationTargetException e) { log.debug( "Reporting back error thrown in remote procedure {}", rpcMethod, e); // tell the sender about the failure getSender().tell(new Status.Failure(e.getTargetException()), getSelf()); return; } final String methodName = rpcMethod.getName(); if (result instanceof CompletableFuture) { // 当返回类型是CompletableFuture时,通过反射执行查找到的方法的返回结果的CompletableFuture, 在CompletableFunction完成(onComplete)的情况下, // 将结果回复给RpcInvocation消息的发送者,即属于异步的回复消息。 final CompletableFuture responseFuture = (CompletableFuture) result; sendAsyncResponse(responseFuture, methodName); } else { // 当返回类型不是以上两种时,直接将反射查找到的方法的执行结果通过tell模式返回给RpcInvocation消息的发送者。 sendSyncResponse(result, methodName); } } } catch (Throwable e) { log.error("Error while executing remote procedure call {}.", rpcMethod, e); // tell the sender about the failure getSender().tell(new Status.Failure(e), getSelf()); } } } |
AkkaRpcActor的启动过程:
AkkaRpcActor是在AkkaRpcService的startServer中进行的。流程分为:
-
- 首先实例化AkkaRpcService的时候,会先实例化SupervisorActor,用来专门实例化AkkaRpcActor和监控注册的Actors。
- 然后向SupervisorActor发送StartAkkaRpcActor,来实例化AkkaRpcActor,并且注册到Actors列表中。
- 构建RpcServer代理对象,使用发送消息给RpcActor的方式实现状态的线程安全操作。
RpcServer代理对象:
-
- FencedRpcEndpoint的实现类对象中调用runAsync、callAsync和shceduleRunAsync方法是通过RpcServer代理对象实现的。
- RpcServer代理对象调用runAsync、callAsync和shceduleRunAsync方法时会调用AkkaRpcInvocation的invoke方法,invoke方法会将这三种方法转换为RunAsync消息和CallAsync消息发送给AkkaActor。
- AkkaRpcActor接收到RunAsync消息和CallAsync消息,进行FencedRpcEndpoint/RpcEndpoint实现类对象的线程安全的状态修改,或者将执行结果原路返回。
AkkaInvocationHandler:
AkkaInvocationHandler类的所有的逻辑入口时实现InvocationHandler的invoke方法。当RpcServer代理对象或RpcGateway代理对象执行某个方法时,AkkaInvocationHandler的Invoke方法会被调用。而AkkaInvocationHandler的invoke处理逻辑是:先获取调用方法定义类,然后根据不同调用方法的定义类进行不通的处理。不同调用方法的定义类,处理情况如下:
-
- 调用方法定义类属于AkkaRpcEndpoint、Object、RpcGateway、StartStopable、MainThreadExecuteable和RpcServer,这是通过反射调用AkkaInvocationHandler的方法,这个场景用于RpcServer调用对应方法时(如调用runAsync、callAsync等方法)。
- 调用方法对应的定义类为FencedRpcGateway时,不支持,直接抛出异常,FencedRpcGateway接口定义的方法只有getFencingToken。
- 调用方法定义类为其他事=时,调用invokeRpc来处理逻辑,这个场景用于继承RpcGateway接口的代理对象调用相应方法时。
组件间通信:
组件间通信都是调用继承RpcGateway接口的代理对象来实现的。如JobMaster、ResourceManager和TaskExecutor之间都是通过调用JobMasterGateway、TaskExecutorGateway和ResourceManagerGateway对应的RpcGateway接口的代理对象来实现通信。
RpcGateway代理对象是通过在AkkaRpcService的connect方法中实现的。实现逻辑是:
-
- 通过actorSelection的方式往Akka地址对应的Actor发送Identity消息。对应的Actor会返回ActorIdentity消息。
- 从ActorIdentity消息中提取ActorRef,再往ActorRef发送RemoteHandShakeMessage消息,与对应的Actor组件握手建立联系。
- 在与Akka地址对应的Actor建立联系后,根据入提供的class(TaskExecutorGateway.class、JobMasterGateway.class、ResourceManagerGateway.class和DispatcherGateway.class等其中一个),InvocationHandlerFactor创建InvocationHandler,通过动态带创建继承RpcGateway接口的代理对象。

Flink组件高可用
Master节点上组件的Leader选举与失去首领角色时的处理
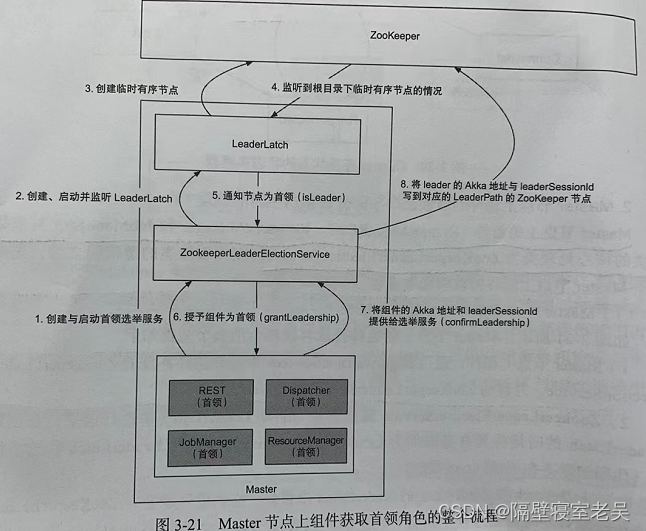
一、Master节点上组件的首领选举流程
-
- Master节点上组件,通过HighAvaliableServices来创建组件各自的ZookeeperLeaderElecttionService,并启动ZookeeperLeaderElecttionService。
- ZookeeperLeaderElecttionService通过创建与启动LeaderLatchListener,来监听LeaerLatch的选举情况。
- LeaderLatch往zookeeper的leaderLatch根目录(这个根目录回来ZookeeperLeaderElectionService的创建过程中设置)创建临时的有序节点,并监听LeaderLatch根目录的创建情况。
- 当LeaerLatch创建的临时节点为最小的编号,即该Master节点上的组件为首领时,LeaderLatch通知ZookeeperLeaderElecttionService已经为首领(isLeader通知过程)。
- ZookeeperLeaderElecttionService接收到组件为首领的通知,调用相应组件的授予首领角色的处理逻辑(grantLeaderShip过程)。在grantLeaderShip的过程中,REST、Dispactcher、JobManager和ResourceManager共同的处理逻辑是,将授予中的LeaderSessionId设置为FencingToken,以防止接收到的发给老首领的消息被处理。启动相关的服务或者进行相应的状态恢复。最终组件都会执行confirmLeaderShip方法,将组件地址与选举为首领时随机产生的首领会话ID(LeaderSessionID)提供给ZookeeperLeaderElecttionService。
- ZookeeperLeaderElecttionService将组件地址和首领会话ID写到运行时组件对应的zokeeper临时节点上,供ZookeeperLeaderRetrievalService检索(comfirmLeaderShip过程)。
状态管理与容错
- 状态的原理与实现:
在Flink中,状态分为Keyed State和OpeartorState两种。这两种状态分为Raw State和Managed State。
Managed Keyed State:
Managed Keyed State只能使用在KeyedStream,其中又有ValueState、ListState、ReducingState、AggregatingState和MapState。
Flink通过RuntimeContext.getState方法获取State,如下StreamingRuntimeContext:
getState方法主要做以下的三件事情:
1)获取KeyedStateStore。KeyedStateStore是在StreamOperator中根据KeyedStateBackend初始化得到的。KeyedStateStore是KeyedState
存储的对象,每一次状态的变更都会同步到KeyedStateStore中去。
2)状态序列化方法初始化。提供一个序列化方法来指定声明状态序列化的方式,一个状态指挥初始化一次,这是为了避免同一个状态被多种方式序列化。
3)从KeyedStateStore中得到的状态的初始值。如果任务是第一次启动,那么会得到状态的默认值;如果任务是从检查点启动的,那么会获得从
StateBackend中恢复的状态值。
@Override
public<T>ValueState<T>getState(ValueStateDescriptor<T>stateProperties){
KeyedStateStorekeyedStateStore=checkPreconditionsAndGetKeyedStateStore(stateProperties);
stateProperties.initializeSerializerUnlessSet(getExecutionConfig());
returnkeyedStateStore.getState(stateProperties);
}
@Override
public<T>ListState<T>getListState(ListStateDescriptor<T>stateProperties){
KeyedStateStorekeyedStateStore=checkPreconditionsAndGetKeyedStateStore(stateProperties);
stateProperties.initializeSerializerUnlessSet(getExecutionConfig());
returnkeyedStateStore.getListState(stateProperties);
}
@Override
public<T>ReducingState<T>getReducingState(ReducingStateDescriptor<T>stateProperties){
KeyedStateStorekeyedStateStore=checkPreconditionsAndGetKeyedStateStore(stateProperties);
stateProperties.initializeSerializerUnlessSet(getExecutionConfig());
returnkeyedStateStore.getReducingState(stateProperties);
}
@Override
public<IN,ACC,OUT>AggregatingState<IN,OUT>getAggregatingState(
AggregatingStateDescriptor<IN,ACC,OUT>stateProperties){
KeyedStateStorekeyedStateStore=checkPreconditionsAndGetKeyedStateStore(stateProperties);
stateProperties.initializeSerializerUnlessSet(getExecutionConfig());
returnkeyedStateStore.getAggregatingState(stateProperties);
}
@Override
public<UK,UV>MapState<UK,UV>getMapState(MapStateDescriptor<UK,UV>stateProperties){
KeyedStateStorekeyedStateStore=checkPreconditionsAndGetKeyedStateStore(stateProperties);
stateProperties.initializeSerializerUnlessSet(getExecutionConfig());
returnkeyedStateStore.getMapState(stateProperties);
}
其中针对KeyedState,Flink提供了两种具体的实现:heap和rocksdb。
MapState =>HeapMapState、RocksDbMapState
ValueState=> HeapValueState、RocksDBValueState
ListState=> HeapListState、RocksDBListState
ReducingState=> HeapReducingState、RocksDBReducingState
AggregatingState => HeapAggregatingState、RocksDBAggregatingState
启动Heap和Rocksdb这两种实现:
- 相同点:两者都实现了InternalKvState类,都需要覆盖getKeySerializer、getNameSpaceSerializer和getValueSerializer方法。这三个方法分别对应:key、NameSpace和value的序列化器。
- 不同点:heap每种状态都关联一个StateTable,对状态的更新读取都是通过StateTable进行的。RockDB的每种状态都关联一个ColumnFamilyHandle,对应RocksDb的列簇,RocksDB的状态变更都是通过ColumnFamilyHandle实现的。
Managed Operator State
Operator State对应于不需要进行keyby的场景,并且使用Operator State需要实现CheckpointFunction或ListCheckpointed接口。
-
- 在函数中实现CheckpointedFunction接口的snapshotState和InitializeState方法。其中进行任务初始化或恢复的时候,调用initiallizeState方法进行状态初始化。
-
- 初始化的时候和KeyedState一样,先创建StateDescriptor,然后调用initiallizeState中的StateInitializationContext.getOperatorStateStore().getListState(descriptor)获取到状态。
- 其中StateInitializationContext中设置了keyedStateStore和operatorStateStore,且该StateInitializationContextImpl在StreamOperatorStateHandler的构造函数中被实例化,并且在StreamOperatorStateHandler在AbstractStreamOperator.initializeState被实例化。所有的算子都继承了AbstractStreamOperator。
- ListCheckpoint提供snapshotState和restoreState,其中snapshotState用于在检查点的时候进行状态处理,restoreState用于任务失败之后恢复上一个检查点中算子的状态。
Managed keyed State和Managed Operator State的区别:
-
- Keyed State只能用于Keyed Stream,而Operator Stream都可以用。
- Keyed State可以理解为一个算子为每个子任务中的每个key维护了一个状态的命名空间,而所有子任务共享Opeartor State。
- Operator State只提供了ListState,而Keyed State提供了ValueState、ListState、ReducingState和MapState。
- Opeartor State的默认实现只有DefaultOpeartorStateBackend,状态都存储在内存中;而Keyed State的存储则根据存储状态介质配置的不同而不同。
检查点执行过程
-
- 在任务的初始化过程中,JobMaster会通过schedulerNG完成各种调度操作。ShcedulerNG.startScheduler中,调用DefaultScheduler.startSchedulingInternal()方法,然后去调用DefaultExecutionGraph.transitionState()去转换作业的状态;首先判断作业是否是结束的状态,然后将作业状态由JobStatus.CREATED转换为JobStatus.RUNNING,然后通知通知所有的JobStateListener任务状态变更, 其中负责检查点的Listener是CheckpointCoordinator。
- 调用CheckpointCoordinator.startCheckpointScheduler启动一个ScheduledTrigger的定时任务,该定时任务负责根据用户配置的时间间隔进行运行状态的处理。


SchedulerTrigger首先会拿到作业所有的Execution(单个ExecutionVertex容器)
Flink任务提交整体流程

-
- 提交作业:执行./bin/flink run yarn-cluster -d 来提交任务,这里使用yarn-cluster方式和detach方式提交任务。
- 解析参数:命令行入口类CliFrontend解析相关参数,根据不同命令和参数执行不同的逻辑。
- 生成JobGraph:如果判断是通过Per-Job和detach方提交任务,会通过PackagedProgramUtils的createJobGraph方法来创建当前任务的JobGraph。
- 创建描述符:创建YarnClusterDescriptor来提交Yarn作业。
- 运行AppMaster:这里向Yarn集群提交一个任务,使用YarnClient接口的相关方法提交任务。
- 上传任务资源文件:提交任务的过程中需要把任务用到的文件或者配置上传到文件系统中,以使任务在不同的节点启动之后都可以获取到需要的资源。
- 提交任务:把任务提交给Yarn的ResourceManager(RM)。YARN的RM会启动一个容器来运行JobManager。具体过程:创建一个新的任务,判断资源情况,调度器(Scheduler)进行调度,随后YARN的RM通知NodeManager启动服务。
- 启动容器:Yarn的NodeManager收到RM通知,进行一系列校验和资源文件的准备,包括文件的下载和环境变量的设置,然后运行启动脚本(由ContainerLanucher根据AppMaster的启动命令生成)启动AppMaster。
- 启动ClusterEntrypoint:启动Flink的AppMaster,入口类是ClusterEntrypoint。
- 启动ResouceManager:ClusterEntrypoint会依次启动JobManager中的各个服务,首先启动负责资源管理的YarnResouceManager,这是JobManager内部的服务,与Yarn的RM是不同的服务。
- 启动Dispatcher:Dispatcher主要负责接收任务的提交,包括REST方式,为Flink提供一个任务提交管理中心化的角色。Dispatcher还可以用来对JobManager进行容错管理,在JobManager失败后做恢复工作。
- 启动JobManager:JobManager对应的实现类是JobManagerRunner,用来管理作业的调度和执行。
- 启动JobMaster:JobMaster会把与作业相关的具体事情委托给JobMaster,自己则主要做一些高可用相关的工作。
- 调度作业:JobMaster会根据JobGraph构建ExecutionGraph,ExecutionGraph经过Slot的分配之后就可以进行真正的部署了。这个时候如果还没有有效的Slot,会先申请Slot。
- 申请资源:JobMaster在调度任务的时候会通过SlotPool进行Slot的申请和分配。SlotPool是通过YarnResourceManager进行slot请求的,而YarnResouceManager内部通过SlotManager进行Slot管理。YarnResourceManager收到Slot请求之后会先判断是否有有效 的Slot可供分配。如果有就直接分配;如果没有,则需要启动一个新的TaskManager提供新的Slot。
- 请求Yarn容器,即Flink中的TaskManager。
- 启动容器:YARN的NodeManager收到命令之后,启动我们所需要的容器。
- 启动TaskExecutor:TaskExecutor的入口类是YarnTaskExecutorRunner,该类会负责启动TaskExecutor。
- 注册TaskManager:TaskExecutor启动之后会向YarnResourceManager注册,成功后再向SlotManager汇报自己的资源情况,也就是Slot,同事会启动心跳等服务。
- 注册Slot:在TaskExecutor向YarnResourceManager注册之后,SlotManager就有了我们需要的Slot。SlotManager会从等待的请求队列里开始分配资源,向TaskManager请求Slot的分配。
- 提供Slot:TaskExecutor收到slot请求后,进行一些检查和异常的判断,没有问题的话就会将Slot分配给JobMaster。到这里ExecutionGraph就得到了需要的物理资源Slot。
- 部署:Execution执行部署任务流程,向TaskExecutor提交任务,TaskExecutor启动新的线程执行任务。到这里整个任务提交流程结束。
Flink SQL
查询优化
Apache Flink 利用和扩展 Apache Calcite 来执行复杂的查询优化。这包括一系列基于规则和成本的优化,例如:
- 基于 Apache Calcite 的子查询去相关
- 列裁剪
- 分区裁剪
- 过滤器下推
- 子查询去重,避免重复计算
- 特殊子查询重写,包括两部分:
-
- 将 IN 和 EXISTS 转换为左半联接
- 将 NOT IN 和 NOT EXISTS 转换为左反连接
- 可选的连接重新排序
- 通过启用table.optimizer.join-reorder-enabled
-
- 注意: IN/EXISTS/NOT IN/NOT EXISTS 目前仅在子查询重写的连接条件中支持。
优化器不仅基于计划,还基于数据源提供的丰富统计数据和每个算子(如 io、cpu、网络和内存)的细粒度成本做出智能决策。
处理(Inser-Only)流
StreamTableEnvironment 提供以下方法来转换和转换为 DataStream API:
- fromDataStream(DataStream):将仅插入更改和任意类型的流解释为表。 默认情况下不传播事件时间和水印。
- fromDataStream(DataStream, Schema):将仅插入更改和任意类型的流解释为表。 可选模式允许丰富列数据类型并添加时间属性、水印策略、其他计算列或主键。
- createTemporaryView(String, DataStream):在一个名称下注册流,以便在 SQL 中访问它。 它是 createTemporaryView(String, fromDataStream(DataStream)) 的快捷方式。
- createTemporaryView(String, DataStream, Schema):在一个名称下注册流,以便在 SQL 中访问它。 它是 createTemporaryView(String, fromDataStream(DataStream, Schema)) 的快捷方式。
- toDataStream(Table):将表转换为仅插入更改的流。 默认流记录类型是 org.apache.flink.types.Row。 单个行时间属性列被写回到 DataStream API 的记录中。 水印也被传播。
- toDataStream(Table, AbstractDataType):将表转换为只插入更改的流。 此方法接受一种数据类型来表达所需的流记录类型。 规划器可能会插入隐式强制转换和重新排序列以将列映射到(可能是嵌套的)数据类型的字段。
- toDataStream(Table, Class):toDataStream(Table, DataTypes.of(Class)) 的快捷方式,可以快速反射地创建所需的数据类型。
处理ChangeLog流
StreamTableEnvironment提供以下方法来公开这些变更数据捕获(CDC) 功能:
- fromChangelogStream(DataStream):将变更日志条目流解释为表格。 流记录类型必须是 org.apache.flink.types.Row,因为它的 RowKind 标志是在运行时评估的。 默认情况下不传播事件时间和水印。 此方法需要一个包含各种更改的更改日志(在 org.apache.flink.types.RowKind 中枚举)作为默认的 ChangelogMode。
- fromChangelogStream(DataStream, Schema): 允许为DataStream类似于fromDataStream(DataStream, Schema). 否则语义等于fromChangelogStream(DataStream)。
- fromChangelogStream(DataStream, Schema, ChangelogMode):完全控制如何将流解释为变更日志。传递ChangelogMode帮助计划者区分insert-only、 upsert或retract行为。
- toChangelogStream(Table):fromChangelogStream(DataStream)的逆操作。 它生成一个包含 org.apache.flink.types.Row 实例的流,并在运行时为每条记录设置 RowKind 标志。 该方法支持各种更新表。 如果输入表包含单个行时间列,它将被传播到流记录的时间戳中。 水印也将被传播。
- toChangelogStream(Table, Schema): 的反向操作fromChangelogStream(DataStream, Schema)。该方法可以丰富产生的列数据类型。如有必要,planner可能会插入隐式强制转换。可以将rowtime写为元数据列。
- toChangelogStream(Table, Schema, ChangelogMode):完全控制如何将表转换为变更日志流。传递ChangelogMode帮助计划者区分insert-only、 upsert或retract行为。
Flink相关的Blog
如何预估Flink集群的 资源:
How To Size Your Apache Flink® Cluster: A Back-of-the-Envelope Calculation
排查Flink 中磁盘对 RocksDB 状态后端的影响:
这里讲述了:如何将通过开启TaskManager的JMX,然后使用VisualVM来连接该JMX进行采样,找到有问题的地方。
The Impact of Disks on RocksDB State Backend in Flink: A Case Study
Flink使用Prometheus监控JobManager和TaskManager的指标:
Flink and Prometheus: Cloud-native monitoring of streaming applications
Monitoring Apache Flink Applications 101
Flink SQL Client
这里测试使用sql-client on k8s seesion模式,操作步骤如下:
- 修改$FLINK_HOME/conf/flink-conf.yaml,新增以下配置:
-
- execution.target: kubernetes-session
- kubernetes.cluster-id: session-cluster-1 // 这里是提交任务的时候指定的cluster-id,还可以配置为:yarn-per-job、yarn-session等。
- 直接启动sql-client,./bin/sql-client.sh embedded 启动SQL-CLient,然后提交sql执行,看是否能提交job到k8s的session集群上:
SELECT word, SUM(frequency) AS `count`
FROM (
VALUES ('Hello',1), ('Ciao', 1), ('Hello', 2)
)
AS WordTable(word, frequency)
GROUP BY word;
参考文章:GitHub - ververica/flink-sql-gateway
Flink SQL中的函数的类型:
- 临时系统函数
- 系统函数
- 临时的catalog函数
- catalog函数
函数调用方式:
- 显式路径调用
-
- 当显式调用的catalog下存在相同的函数时,则函数查找顺序为:
- 临时catalog函数
- catalog函数
-
- 模糊调用
-
- 当以模糊调用的方式进行调用的时候,函数查找顺序为:
- 临时系统函数
- 系统函数
- 临时catalog函数,在会话的当前catalog和当前数据库中
- catalog函数,在会话的当前catalog和当前数据库中
Flink SQL的自定义UDF函数:
- 标量函数:将标量值映射到新的标量值。 【UDF】
-
- 继承 ScalarFunction 并实现eval()函数
-
- 表函数:将标量值映射到新行。【UDTF】
-
- 继承TableFunction并实现eval()函数
-
- 聚合函数:将多行的标量值映射到新的标量值。
-
- 继承AggregateFunction并且需要实现以下的函数。
- createAccumulator()、accumulate(...)、getValue(...):这三个函数是必须要实现的。
- retract(...):在Over Window上的聚合需要实现该方法。【选择进行实现】
- merge(...):许多有界聚合以及会话窗口和跳跃窗口聚合都需要。 此外,这种方法也有助于优化。 例如,两阶段聚合优化需要所有的 AggregateFunction 支持合并方法。【选择进行实现】
-
- 表聚合函数:将多行的标量值映射到新行。
-
- 继承TableAggregateFunction并需要实现以下函数。
- createAccumulator()、accumulate(...)、emitValue(...)或者emitUpdateWithRetract(...):这几个函数是必须要实现的。
- retract(...):在Over Window上的聚合需要实现该方法。【选择进行实现】
- merge(...):许多有界聚合和无界会话和Over Window聚合都需要。【选择进行实现】
- emitValue(...):有界和窗口聚合需要。【选择进行实现】
- emitUpdateWithRetract(...):用于发出已在retract模式下已经被更新的值。可以提高streaming job的性能。
-
- 异步表函数:用于执行查找的表源的特殊函数。
优化:
MiniBatchAggregation:
该优化项为了解决聚合的时候频繁访问statestore的问题,开启该优化项得指定以下的配置项:
- table.exec.mini-batch.enabled = true
- table.exec.mini-batch.allow-latency = '5s'
- table.exec.mini-batch.size = 1000
Local-GlobalAggregation:
该优化项为了解决数据倾斜问题,将组聚合分为两个阶段,即先在上游进行局部聚合,然后在下游进行全局聚合,类似于MapReduce中的Combine+ Reduce模式。
- table.optimizer.agg-phase-strategy = 'TWO_PHASE'
SplitDistinct Aggregation:
- 优化原理:将不同的聚合(例如COUNT(DISTINCT col))分成两个级别。第一个聚合由分组键和一个附加的分桶键打乱。分桶键是使用 计算的HASH_CODE(distinct_key) % BUCKET_NUM。BUCKET_NUM默认为 1024,可通过table.optimizer.distinct-agg.split.bucket-num选项进行配置。第二个聚合由原始组键打乱,并用于SUM聚合来自不同存储桶的 COUNT DISTINCT 值。因为同一个distinct key只会在同一个bucket中计算,所以变换是等价的。bucket key 起到了额外的 group key 的作用,分担了 group key 中热点的负担。分桶键使工作具有可扩展性,以解决不同聚合中的数据倾斜/热点。
- 优化原理的距离说明:
-
- Select day, count(distinct user_id) from T group by day
- 优化为以下类型的SQL语句:
SELECT day, SUM(cnt)
FROM (
SELECT day, COUNT(DISTINCTuser_id) as cnt
FROM T GROUP BY day,MOD(HASH_CODE(user_id), 1024)
)
GROUP BY day
table.optimizer.distinct-agg.split.enabled = 'true'
table.optimizer.distinct-agg.split.bucket-num = '1024'
UseFILTER Modifier on Distinct Aggregates:
- 优化前的SQL语句:
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT CASE WHEN flag IN ('android','iphone') THEN user_id ELSE NULL END) AS app_uv,
COUNT(DISTINCT CASE WHEN flag IN ('wap','other') THEN user_id ELSE NULL END) AS web_uv
FROM T
GROUP BY day
- 优化后的SQL语句
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN('android', 'iphone')) AS app_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN('wap', 'other')) AS web_uv
FROM T
GROUP BY day
在这种情况下,建议使用FILTER语法而不是CASE WHEN。因为FILTER更符合 SQL 标准,将获得更多的性能提升。 FILTER是用于聚合函数的修饰符,用于限制聚合中使用的值。
自定义Flink Table Source
- 实现DynamicTableSourceFactory的方法。
- 实现DynamicTableSource的方法
- 实现SourceFunction的方法。
https://www.jianshu.com/p/a218069357cf
Flink SQL CDC 上线!我们总结了 13 条生产实践经验_Techflow1的技术博客_51CTO博客
Flink-1.13.0 sql-client yarn-session模式部署_lyd882的博客-程序员宝宝 - 程序员宝宝
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。