
《Attention Is All You Need》一文中所提出的Transformer模型,与传统的CNN架构完全不同。Transformer中的注意力机制(attention mechanism)更是其大放异彩的核心之处。
前言
当前存在的问题:
在自然语言处理(NLP)场景下,通常使用的是循环模型(Recurrent model,RNN),但其顺序处理的特性存在以下弊端:1、沿着输入和输出的符号位置进行因子计算(通俗地讲就是计算
h
t
h_t
ht的话必须先知道
h
t
−
1
h_{t-1}
ht−1和当前的输入
t
t
t),这种顺序性质限制了并行性;2、当输入序列较长时需要存储很多的前置信息(通俗地讲就是要算第100个单词的话,需要掌握前99个单词就很麻烦),内存开销较大,甚至还会丢失很久之前的信息。创新点解决问题:
Transformer模型完全基于注意力机制,提出的编码器和解码器一次性可以获取序列的全部信息,有效地解决了上述两个问题。为了模拟CNN的多输出通道特性,Transfomer中还提出了多头注意力(Multi-Head Attention)的一种方式。
模型架构(Model Architecture)
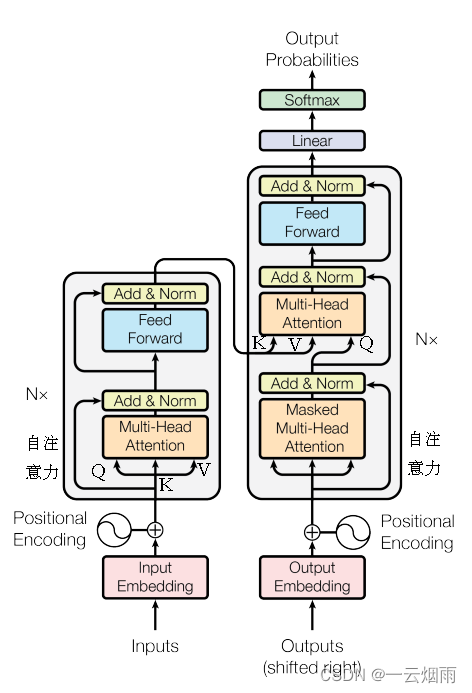
- 图中的inputs表示输入的一些单词序列,用编码后的 ( x 1 , x 2 . . . , x n ) (x_1,x_2...,x_n) (x1,x2...,xn)来表示这些词向量;
- Input Embedding相当于,学习了一个向量来表示单词(词源,token),向量长度为 d m o d e l = 512 d_{model}=512 dmodel=512;
- n个单词组成句子时,单词之间有位置关系,比如主语在谓语前,宾语在谓语后等等,所以再经过位置编码(Positional encoding)后,即可送入编码器。计算公式为:
P E ( p o s , 2 i ) = s i n ( p o s 1000 0 2 i d m o d e l ) PE(pos,2i)=sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) PE(pos,2i)=sin(10000dmodel2ipos)
P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i d m o d e l ) PE(pos,2i+1)=cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) PE(pos,2i+1)=cos(10000dmodel2ipos)
其中pos表示单词在句子中的绝对位置,pos=0,1,2…,例如:Jerry在"Tom chase Jerry"中的pos=2; d m o d e l d_{model} dmodel表示词向量的维度,在这里 d m o d e l d_{model} dmodel=512;2i和2i+1表示奇偶性,i表示词向量中的第几维,例如这里 d m o d e l d_{model} dmodel=512,故i=0,1,2…255。 - 编码器的输出用 ( z 1 , z 2 . . . , z n ) (z_1,z_2...,z_n) (z1,z2...,zn)来表示;
- 解码器的输出是翻译完的句子,用 ( y 1 , y 2 . . . , y m ) (y_1,y_2...,y_m) (y1,y2...,ym)来表示, m m m和 n n n可以一样也可以不一样;
- 解码器还有一个输入是因为自回归(auto-regressive),通俗地讲是当计算 y m y_m ym时需要输入 y m − 1 y_{m-1} ym−1,进行预测时则没有这个输入;
- 在解码器中,Transformer block比编码器中多了个encoder-cecoder attention。在encoder-decoder attention中, Q Q Q来自于解码器的上一个输出, K K K和 V V V则来自于与编码器的输出;
- 完整可训练的网络结构便是编码器和解码器的堆叠( N = 6 N=6 N=6)。
在介绍多头注意力机制之前,还需要先补习一些注意力机制的知识。
注意力函数是一个Query(简称Q)和一些key-value对( key-value pairs)映射成一个输出的函数。
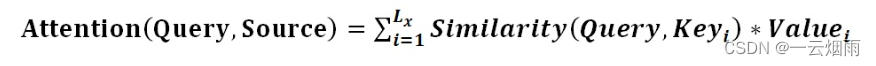
具体而言,输出output是value的加权和,加权系数由query和value所对应的key的相似性(compatibility function)决定。
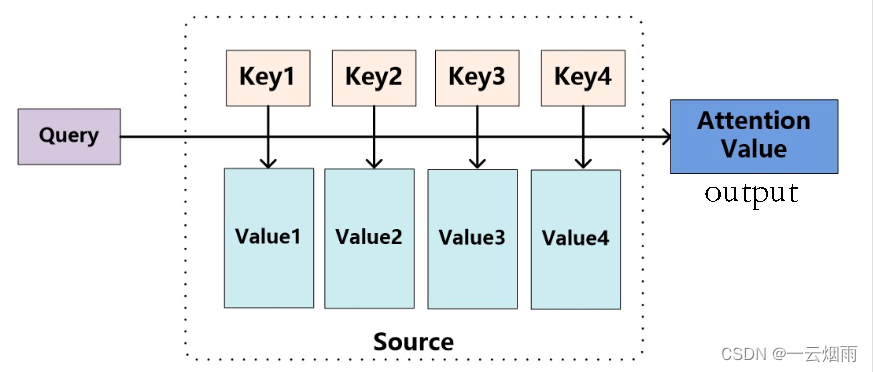
不同的相似函数就有不同版本的注意力机制,Transformer这篇文章所使用的相似函数就是点积(Dot-Product Attention)。这个输出值就是 z z z。
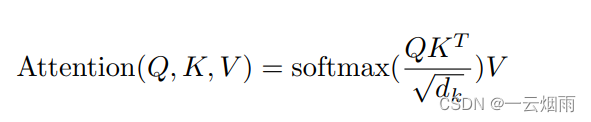
其中Q和K的维度都是 d k d_k dk,V的维度是 d v d_v dv,计算完Q和K的点积之后,再除以 d k \sqrt{d_k} dk,再运用softmax函数得到V的权重。因为Transformer定义的相似性函数还除以了 d k \sqrt{d_k} dk,所以叫尺度点积注意力机制(Scaled Dot-Product Attention)。整个过程就如下所示:
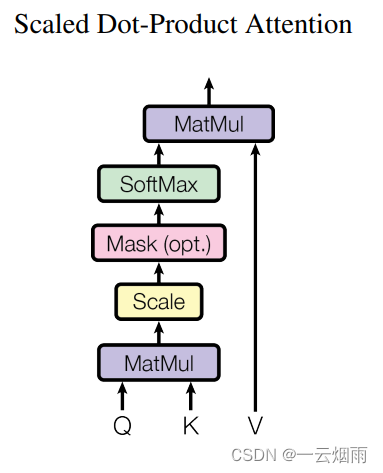
图中加的Mask模块的目的是,在训练计算第 t t t时刻的输出时, Q Q Q只能关注到 t t t时刻之前的信息,而不受 t + 1 , . . . t+1,... t+1,...这些的影响。
多头注意力机制:
Multi-Head Attention使用多组可学习的
W
Q
W^Q
WQ、
W
K
W^K
WK、
W
V
W^V
WV得到多组Query、Keys、Values,然后每组分别执行Scaled Dot-Product Attention,计算得到一个输出矩阵
h
e
a
d
i
head_i
headi,最后将得到的多个输出矩阵进行拼接(Concat)。Transformer中设定
h
=
8
h=8
h=8,相当于有8个头。
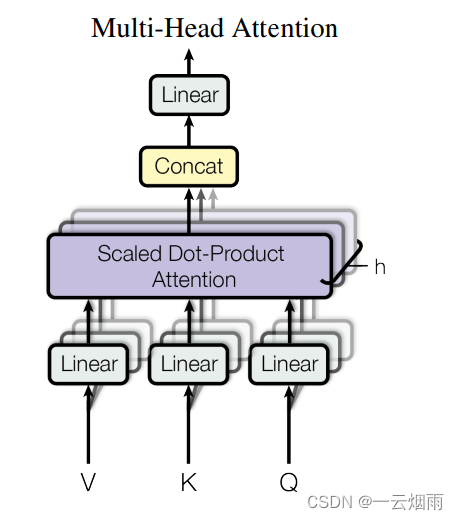
由于在计算过程中还涉及到残差连接以及最后的Concat,所以要求每个 h e a d i head_i headi的维度相同,即 d k = d v = d m o d e l h = 64 d_k=d_v=\frac{d_{model}}{h}=64 dk=dv=hdmodel=64
Feed-Forward Network:
全连接层将对每一个单词利用相同的权重执行一次(point wise),第一层的激活函数为 Relu,第二层不使用激活函数。
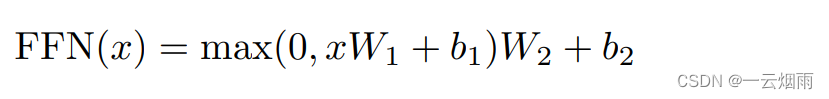
W 1 W_1 W1将512维提升至2048,为了残差连接, W 2 W_2 W2又将2048维降低至512。
参考
https://blog.csdn.net/Tink1995/article/details/105012972
https://blog.csdn.net/Tink1995/article/details/105080033
http://jalammar.github.io/illustrated-transformer/
https://www.bilibili.com/video/BV1pu411o7BE/?spm_id_from=333.788&vd_source=94f79d8adeec4791b8751d7cb539ce55
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。