
目录《工作五年,我从零开始学代码》
上篇文章《工作五年,我从零开始学代码》
目录
硬件层
数据通路
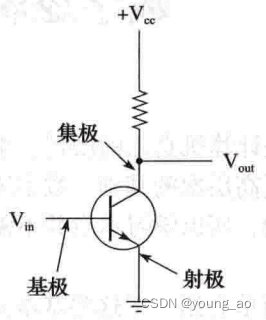
请让我们忘记一切语言、代码和框架,回到只有一堆三极管和导线的年代。三极管是个神奇的电子器件,它有三个引脚,分别为基极、集极、射极。基极接Vin,集极接Vcc,射极接GND
Vin 输入信号电压;Vout 输出信号电压;Vcc 电源电压;GND 地端
若基极Vin电压大于某个电压,如1.5v,则三级管导通,Vout电压等于GND,逻辑上为0;若基极Vin电压小于1.5v,则三级管不通,Vout电压等于Vcc,逻辑上为1。以上可以理解为非门
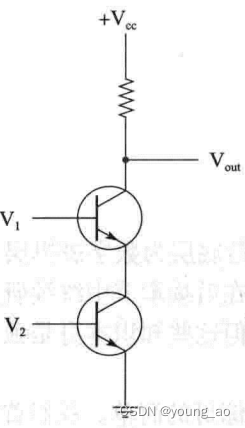
接着把两个三极管串联起来,我们就得到了与非门
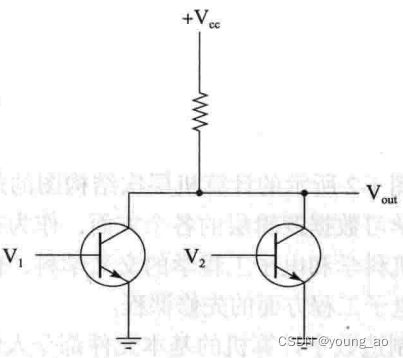
接着把两个三极管并联起来,我们就得到了或非门
是不是很有意思?假如你是一名出色的电子工程师,继续将三极管以各种奇奇怪怪的方式连接起来,那么你就得到了最基本的电路,例如以下几种:
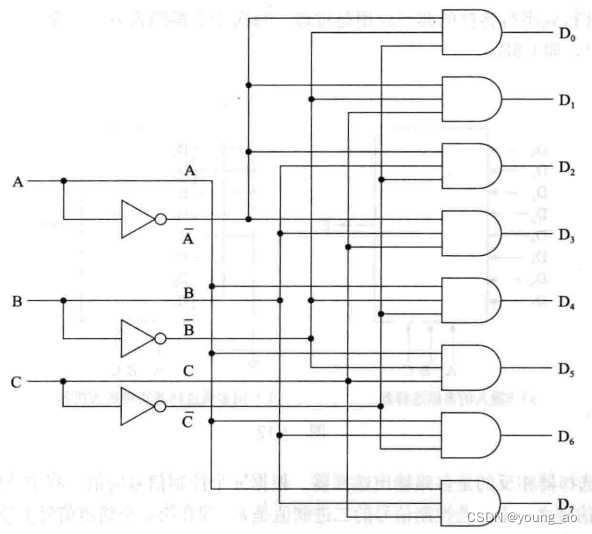
1、译码器,将n个输入信号转换为2的n次方种输出结果。ABC为三个输入,D0~D7为八个输出,改变输入的组合,就可以使其中一个输出为高电平。假设我们内存条上有八块存储芯片,可以使用译码器来选择使用哪块
2、多路选择器,改变ABC三位控制信号,从D0~D7个输入信号中选择一个输出
3、比较器,比较两个字(一个字为4bit)的大小,相等返回1,否则为0
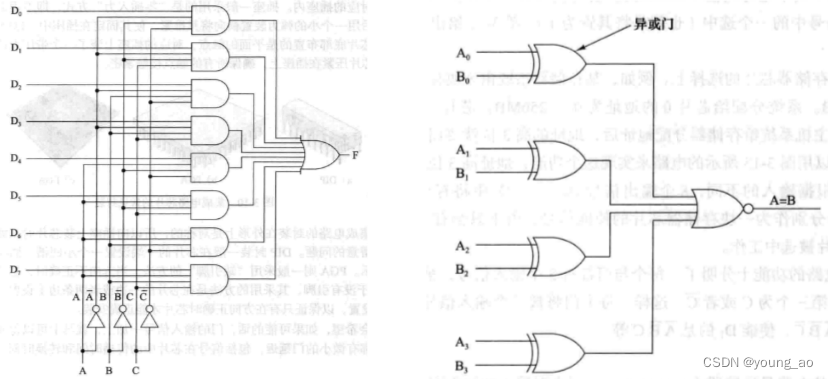
4、移位器,对n位输入信号进行左移右移并输出
5、加法器,对两个输入字进行相加并输出
6、算法逻辑部件ALU,每台计算机都有一个简单的电路,用来完成两个字的与、或、和等运算
7、内存/寄存器,触发器/锁存器是构成内存和寄存器的基本电路,能够记住输入信号的值(0或1)。为了简单理解,可以将内存看做是一个地址线性增长的二维数组
8、总线,负责将各种基本电路连接起来,可以将其理解为n条并行导线组成的。n条导线中,有些负责传输控制信号,有些负责传输数据(如果有x条导线负责传输数据,就可以同时传输x位)
......
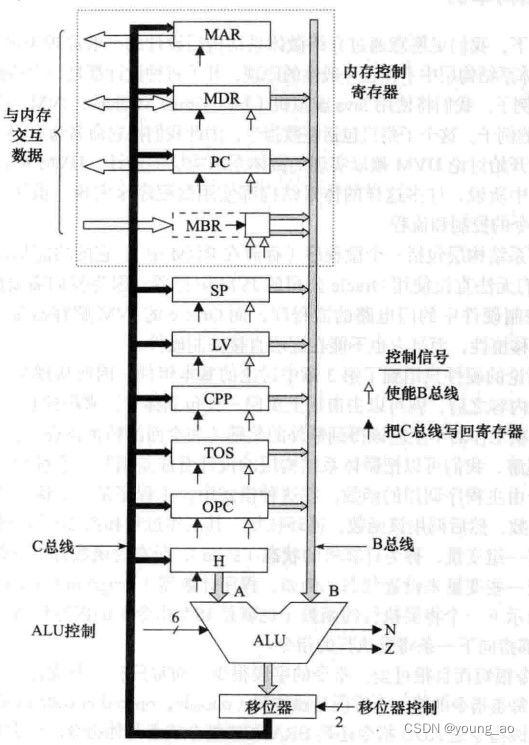
上面列举了这么多基本电路,就是为了让你穿越到太古时期:这里没有代码,只有三极管和导线。身为猪脚的你继续奋发图强,很快就将这些基本电路组合了起来,形成第一个数据通路,如下图。它能够选中一个寄存器,通过B总线将数据传输到ALU,ALU经过计算,通过C总线将结果写入寄存器。PC寄存器指向了内存中下一条指令的偏移量,MBR寄存器保存了要执行的指令
数据通路是cpu最基本的动作,数据通路运行完毕所需的时间等于时钟周期的时间。时钟周期越短,频率也就越高,通常计算机的性能会更好
微程序
有了数据通路,如何控制其行为呢?比如需要4位控制信号来选择一个寄存器输出数据到B总线;需要8位控制信号来指定ALU执行加/或/与运算中的一种;需要n位控制信号指定将结果写入到哪个寄存器。诸如此类,在一个数据通路周期中,共需要36位控制信号。话句话说,数据通路完整地执行一圈,需要36位控制信号来控制其行为,具体形式为010001010111110101001010111111101010,改变0和1的不同有意义组合,数据通路就对应不同行为
这36位控制信号就叫做微指令(注意这里的微‘指令’与PC寄存器指向的‘指令’不是一回事),前9位储存下一条微指令地址,接着3位控制JAM,接着8位控制ALU...
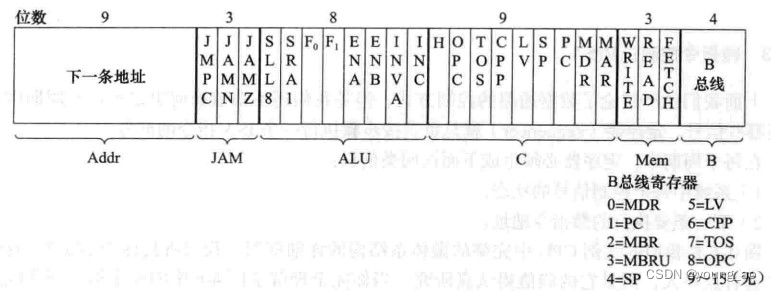
但是上面一串01非常不直观,我们引入一种符号表示,仅仅用于书写和分析。比如在一个数据通路周期中,想要SP寄存器的值加1,并启动读内存操作,并且取下一条微指令,可以这样写:SP=SP+1;rd
下面,将补全数据通路缺失的控制信号部分,形成一个完整的物理计算机Mic-1。图的左边为数据通路,右边为控制信号。所有的微指令都保存在微程序控制存储器中,可以把它理解为一块只读内存。保存的这些所有微指令组成了微程序

微程序是如何运行的呢?当通电后,从MPC所指向的控制存储器位置读出微指令加载到MIR,完成后各个不同的信号就开始在数据通路中传送了。某个寄存器把值放在B总线上,ALU知道该执行什么操作,输出经过移位器和C总线,写入到某个寄存器中。同时会利用MBR、ALU结果N和Z、微指令的Addr和JMPC位,计算出下一条微指令的地址,保存进MPC。此时就进入下一次的数据通路周期了,如此循环往复,直到关闭电源
但有一个问题,没有思想的各个组件是如何知道什么时候该执行什么操作呢?随着时间不断向前,一个数据通路周期又是如何确定的呢?这里引入时钟周期的概念,时钟周期是一个方波,来自时钟源,一种能够产生周期性稳定方波信号的器件,波峰为高电平,波谷为低电平,当然你也可以反过来。由高电平变为低电平的过程叫做下降沿,反之称为上升沿。下图中黑色实线部分分别为时钟周期1和时钟周期2
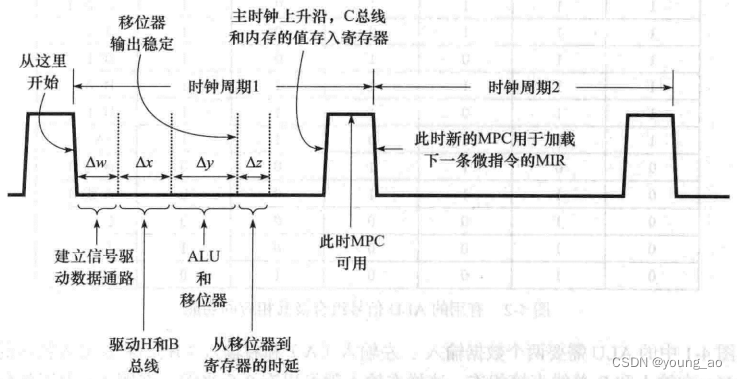
下面将以时序的维度再次描述微程序的运行过程。在第一个时钟周期开始处,下降沿会驱动MPC从所指的地址处读出微指令加载到MIR,这个过程a花费Δw时间,因为电子在导线和器件中传输并非没有时间,而是会经历一个小的延迟,就像图中从高电平变为低电平的过程,是一个并不垂直的线。换句话说,必须经过Δw时间之后,a过程才能够稳定,MPC和MIR输出的值才是正确的。接着MIR驱动H和B总线工作,经过Δx后稳定。后面还要再经过ALU、移位器、C总线的稳定过程。此刻,时钟周期由低电平变为高电平(上升沿),驱动了C总线和内存的值写入寄存器。再经过一段时间后,MPC的值也稳定了。随着时钟周期的再次变化(下降沿),下一个周期就开始了
在一个时钟周期内,只有下降沿和上升沿是真实发生的,至于其中的ΔwΔx则是电子器件的延时时间,并没有一个明确的信号来告诉电子器件开始或结束,完全是依靠生产商来保证在规定时间内一定会完成并稳定
介绍完运行原理,最后一步就是将微程序写入存储控制器了,微程序如下:

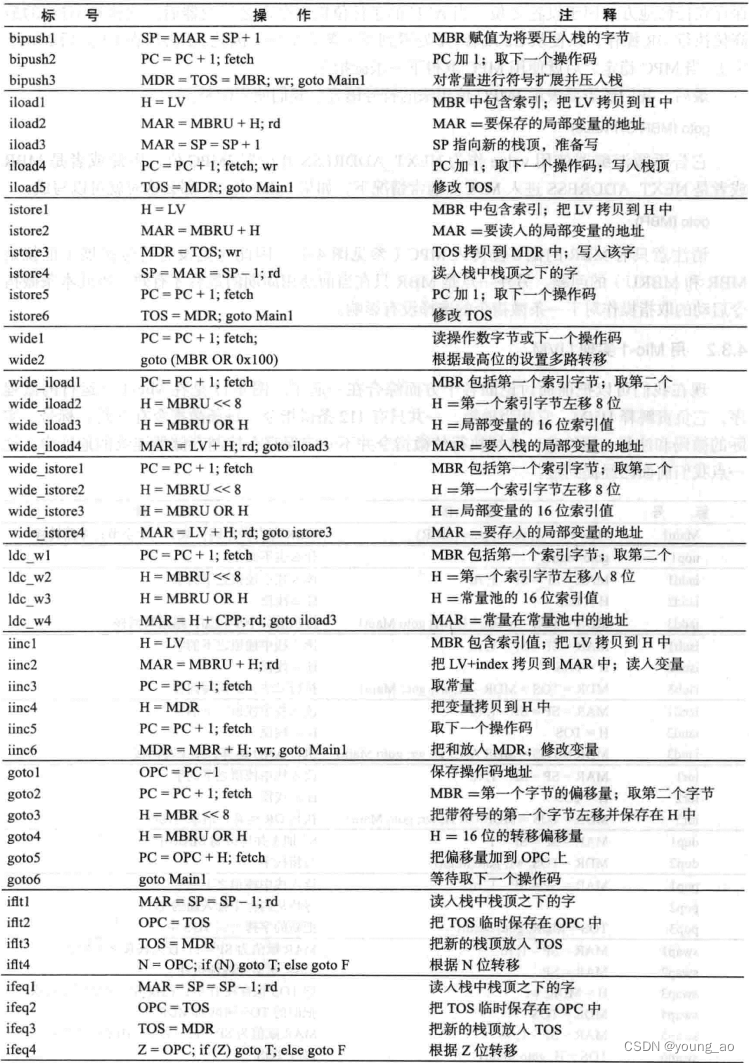
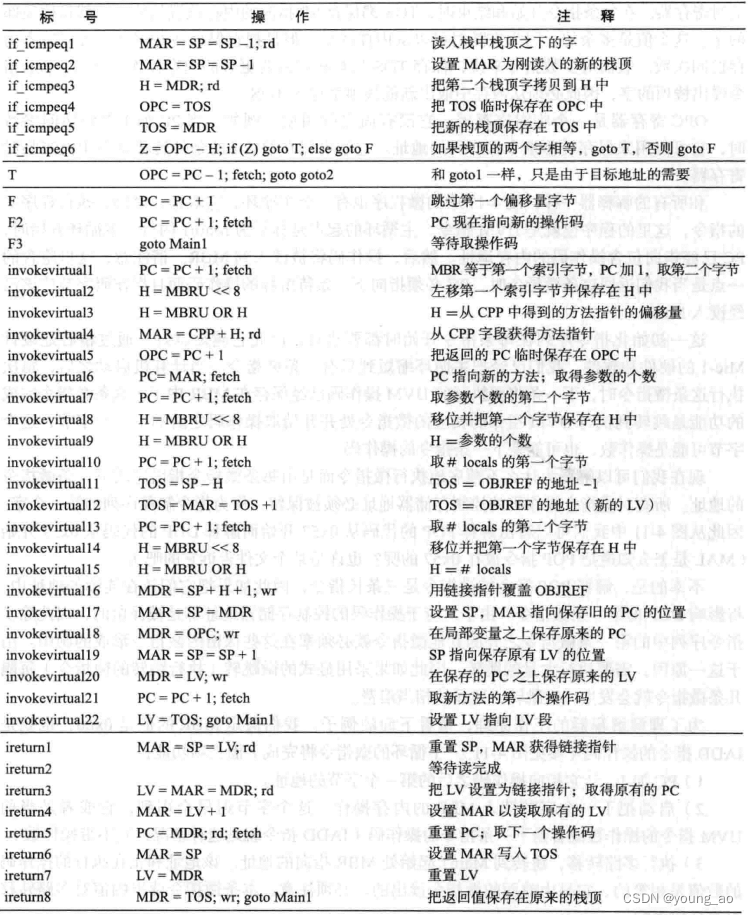
第一列是标号(仅仅帮助记忆),第二列是微指令的符号表示,第三列是微指令功能介绍。具有相同标号前缀的若干微指令,用于实现对应的指令,比如ireturn1~ireturn8(被称为微指令序列)用于实现指令ireturn。为了表示方便,ireturn1~ireturn8放在一起,但在实际的存储上不是按顺序的,每条微指令都包含一个指向下条微指令地址的字段。尽管不是按照顺序保存的,但是ireturn1的地址与ireturn的标号(下面会讲到指令)是相同的,一一映射不可更改,用于执行时,能够从ireturn所指向的控制存储器地址找到ireturn1
到现在为止, 你已经完成了机器的电子线路部分
指令
就像网络分为五/七层,计算机也分为若干层次,指令层在硬件层之上,硬件层负责解释执行指令层的指令。拿产品经理与程序员的关系类比一下,产品经理先画出原型图,而后程序员负责用代码实现它,同样,先设计好指令,后有硬件层实现。但是硬件也会影响指令设计,就像你对产品说,这个实现起来代价太大,我们换种方案吧。请注意,这篇文章先介绍了物理层实现,后介绍指令实现,是倒置的
现在,开始实现我们的指令集——IJVM。它参考了JVM的指令集、内存布局、执行方式(基于栈)。只不过IJVM是极度简化的,仅能够做整数运算,而且它是一台真正的物理机,而不是像HotSpot一样的虚拟机
聪明的你可能已经从上面一段话中看出了端倪,内存布局、执行方式等等是与指令集密切关联的,它们之间互相影响。下面先分别介绍基于栈的执行方式,和IJVM内存布局
栈
IJVM支持方法调用,每个方法有自己的局部变量,在方法内部可以访问这些变量,而方法一旦返回,这些变量就不存在了。这里就有一个问题:这些变量应该保存在内存的什么位置呢?
最简单的方案是给每个变量一个绝对的内存地址,但是实际上该方案行不通,问题在于方法可以调用自己(也就是方法的递归调用),如果一个方法被调用了两次,那么就不可能把局部变量保存在绝对内存地址中,因为第二次调用写入的局部变量将会影响第一次调用的局部变量值。因此必须使用其它的方案,我们可以使用称为栈的内存区域来保存变量,栈中的变量并没有绝对地址,而是使用寄存器LV指向当前方法的局部变量结构的基地址。在图1-a中,方法A被调用,它有3个局部变量al、a2和a3,它们被保存在从LV寄存器所指的内存地址开始的内存段中。另一个寄存器SP,指向A的局部变量中的地址最高的一个字。如果LV的值是100,每个字的长度为4个字节,那么SP的值就是108。通过给出变量相对于LV的偏移量来访问变量。LV和SP之间的数据结构(包括这两个寄存器指向的字)称为A的局部变量结构

现在我们来看一看如果A调用了另一个方法B会发生什么情况。B的4个局部变量(b1、b2、b3、b4)将保存在哪里呢?答案是:保存在栈中A的局部变量结构的上面,如图1-b所示。方法调用指令将使LV指向B的局部变量而不再是A的局部变量。然后就可以通过给定相对LV的偏移量来访问B的局部变量。与之类似,如果B调用C,那么LV和SP将再次被调整以便为C的两个局部变量分配空间,如图1-c所示
当C返回时,B再次被执行,栈又被恢复成图1-b的状态,这样LV就可以再次指向B的局部变量。同样,当B返回时,栈将变回图1-a的状态。在任何情况下,LV都指向当前正在执行的方法的栈段的底部,SP则指向栈段的顶部
现在假定A调用D,D有5个局部变量。栈就将变成图1-d的状态,D的局部变量使用了B的局部变量用过的相同的内存区域和C用过的部分内存区域。采用这种内存组织方式,可以只为当前正在执行的方法分配内存。当方法返回后,该方法的局部变量使用的内存将被释放
除了保存局部变量之外,栈还有另一种用途。在算术表达式求值时可以使栈保存操作数。当栈用于这种目的时,称为操作数栈。举个例子,假定在调用B之前,A计算表达式a1 = a2+ a3;计算该表达式的一种方法是把a2压入栈,如图2-a所示,SP将被加上一个字的字节数,比如4,现在SP就指向了第一个操作数。然后,把a3压入栈,如图2-b所示
现在可以执行实际的计算了,计算时指令会把这两个数弹出栈,相加再把结果压回栈,如图2-c所示。最后,栈顶的字被弹出栈并保存到局部变量a1中,如图2-d所示

局部变量结构和操作数栈可以混合使用,例如,计算表达式x+f(x)时,当调用f时,表达式的结果已经位于栈顶。因此函数f(x)的结果将位于x之上,这样下一条指令就可以把它们相加
内存模型
我们规定内存划分为以下几个区域
1、常量池:用来保存常量、字面量、偏移量、方法签名等,一旦代码加载完成后,该区域只可读
2、栈帧:用来保存当前方法的局部变量,以及操作数栈。具体描述见上面‘栈’的介绍
3、方法区:保存着我们编写的‘业务’代码,有一个寄存器PC指向方法区的基地址,每当PC+1,就指向下一条指令
介绍完栈和内存布局,IJVM指令集是时候登场了!
IJVM指令集
它一共拥有20条指令,大部分指令的工作方式是基于栈和内存模型的,例如BIPUSH会用到栈,把byte压入其中。它的格式非常简单,以BIPUSH byte为例,前面为操作码,后面为操作数,或者根本没有操作数(DUP)。下面表格中,第一列为指令的十六进制编码,第二列为助记符(仅仅是帮助记忆),第三列是功能描述
每条指令都对应一个微指令序列,第一列十六进制编码就对应微指令序列的第一个微指令的地址
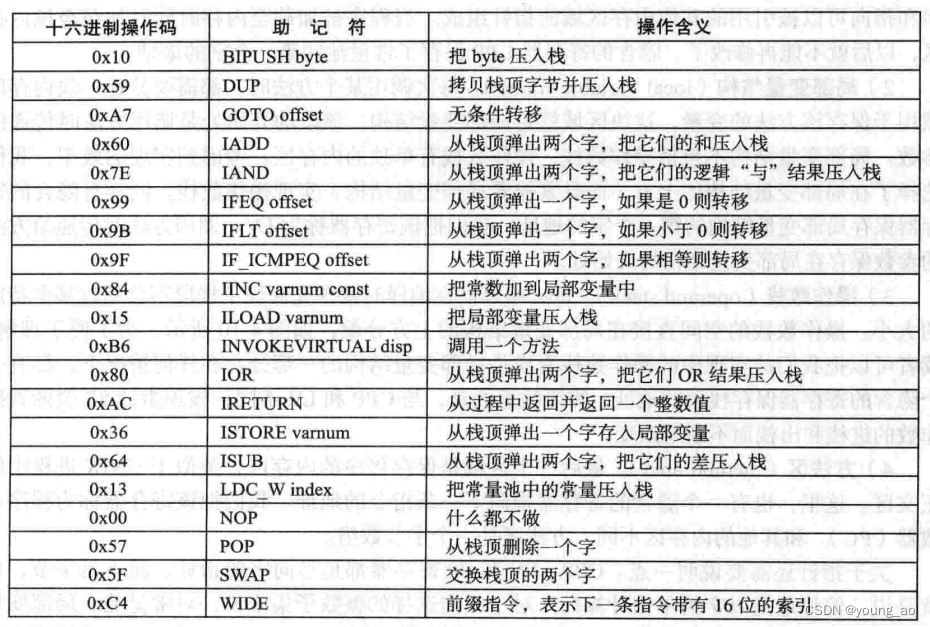
硬件层实现指令集
硬件层和指令集都已经介绍完了,现在把它们结合起来:微程序是如何解释指令的。微程序就像一个永不停歇的循环:取指令,解释指令。最开始执行的微指令为标号Main1处,他将PC值加1,用于获取下一条即将要被执行的指令,然后读取MBR寄存器的值(保存的是当前要被执行的指令),跳转到对应的微指令序列处开始执行,当序列执行完毕,再次跳转到Main1处,开始下一次循环
总结
“什么是代码”是一个广阔的命题,在这里我们只讨论了很小一部分:指令。指令既机器码,是非常低层次的代码,它如何产生,如何运行是非常有意思的。要真正学习计算机,必然要学习指令层,这一层没有过多的包装和抽象,直面最基本和真实的物理资源,并且对我们入门JVM、golang等技术非常有帮助
下一篇文章中,将会给出MIC-1、IJVM、MAL、Assembler等代码实现,我们能够真正在上面运行代码、观察常量池、栈和方法区、修改指令集。代码实现补全了本文中缺失的细节,能够让我们彻底理解其技术原理
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。