

1、树形结构:树是 n(n>=0) 个结点的有限集合T,当 n=0 时,称为空树;当 n>0 时,该集合满足如下条件:
(1)其中必有一个称为跟(root)的特定结点,他没有直接前驱,但有0个或多个直接后继。
(2)其余 n-1 个结点可以划分成 m(m>=0) 个互不相交的有限集合,T1,T2,T3,··· Tm,其中Ti又是一棵树,称为根的子树。子树的定义也同树的定义一样。
如图:

** 关于树的一些术语及相关概念:
节点的度 :一个节点含有的子树的个数称为该节点的度;
树的度 :一棵树中,最大的节点的度称为树的度;
叶子节点 :度为0的节点称为叶节点;
双亲节点 :若一个节点含有子节点,则这个节点称为其子节点的父节点;
孩子节点 :一个节点含有的子树的根节点称为该节点的子节点;
根结点 :一棵树中,没有双亲结点的结点;
节点的层次 :从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度 :树中节点的最大层次;
2、二叉树满足以下条件:
(1)每个节点的度都不大于二;
(2)每个结点的孩子结点次序不能任意颠倒,即孩子有左右之分。

两种特殊的二叉树:
1.满二叉树:一个二叉树,如果每-一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果
一个二叉树的层数为K,且结点总数是2k - 1 ,则它就是满二叉树。
2.完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n
个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全
二叉树。要注意的是满二叉树是一种特殊的完全二叉树。

二叉树的性质:
1.若规定根节点的层数为1,则-棵非空=叉树的第i层上最多有2i一1(i>0)个结点
2.若规定只有根节点的二叉树的深度为1,则深度为K的二叉树的最大结点数是2k - 1(k>=0)
3.对任何-棵= =叉树,如果其叶结点个数为n0,度为2的非叶结点个数为n2,则有n0= n2 + 1
4.具有n个结点的完全二叉树的深度k为log2(n + 1)上取整
5.对于具有n个结点的完全二叉树,如果按照从上至下从左至右的顺序对所有节点从0开始编号,则对于序号为i
的结点有:
若i>0,双亲序号: (i-1)/2; i=0, i为根节点编号,无双亲节点。
若2i+1<n, 左孩子序号: 2i+1, 否则无左孩子
若2i+2<n,右孩子序号: 2i+2, 否则无右孩子.
二叉树代码实现:
节点类:
public class Node <E extends Object> {
public E val;
public Node<E> left; // 左孩子
public Node<E> right; // 右孩子
public Node(E val){
this.val=val;
}
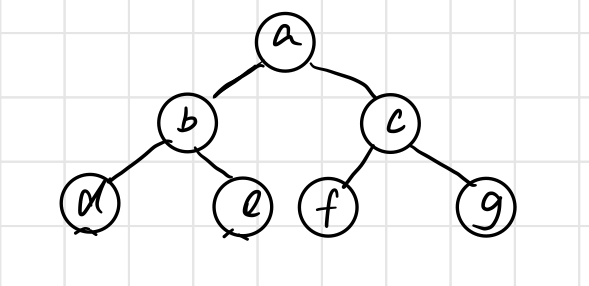
}二叉树的基本操作,使用以下二叉树为例:
//构建树
public static Node<Character> BuildTree(){
Node<Character> n1 = new Node<>('a');
Node<Character> n2 = new Node<>('b');
Node<Character> n3 = new Node<>('c');
Node<Character> n4 = new Node<>('d');
Node<Character> n5 = new Node<>('e');
Node<Character> n6 = new Node<>('f');
Node<Character> n7 = new Node<>('g');
Node<Character> n8 = new Node<>('m');
n1.left = n2;n1.right = n3;
n2.left = n4;n2.right = n5;
n3.left = n6;n3.right = n7;
n5.left = n8;
return n1;
}
1. 递归遍历二叉树:
(1)根、左、右(前序):abdemcfg
//前序遍历
public static void preOrder(Node<Character> root){
if (root != null){
//如果为空证明则什么都不做,退出即可。
System.out.print(root.val);//打印当前结点的值。
preOrder(root.left);//前序遍历左子树,将问题分解成小问题。
preOrder(root.right);//前序遍历右子树
}
}运行结果为:
![]()
(2)左、根、右(中序):dbmeafcg
//中序遍历
public static void inorder(Node<Character> root){
if (root != null){
//如果为空证明则什么都不做,退出即可。
inorder(root.left);//中序遍历左子树,将问题分解成小问题。
System.out.print(root.val);//打印当前结点的值。
inorder(root.right);//中序遍历右子树
}
}运行结果为:
![]()
(3)左、右、根(后序):dmebfgca
//后序遍历
public static void postorder(Node<Character> root){
if (root != null){
//如果为空证明则什么都不做,退出即可。
postorder(root.left);//后序遍历左子树,将问题分解成小问题。
postorder(root.right);//后序遍历右子树
System.out.print(root.val);//打印当前结点的值。
}
}运行结果:
![]()
总结:在遍历二叉树时,可以看到采用递归是一个不错的选择。当我们拿到一个二叉树的时候首先将其拆分成:
左子树 + 根结点 + 右子树 的结构形式。然后对其 “左子树” 和 “右子树”分别进行同样的操作,即递归。
至于顺序,那就以你选择的遍历顺序一致,如:前序则是:根结点 + 左子树 + 右子树。
层序遍历二叉树:原则比较简单,即从上至下,从左至右遍历二叉树。
//层序遍历
public static void levelOrder(Node<Character> root){
//我们从一开始就不会给 queue 中放入 null 值。
Queue<Node<Character>> queue = new LinkedList<>();
if (root != null){
queue.offer(root);
}
//如果队列不为空,则证明还没有遍历完。
while ( !queue.isEmpty() ){
Node<Character> node = queue.poll();
//访问当前结点值
System.out.print(node.val);
if (node.left != null){
//如果有左孩子,则让左孩子入队
queue.offer(node.left);
}
if (node.right != null){
//如果有右孩子,则让右孩子入队
queue.offer(node.right);
}
}
}
总结:层序遍历时一定是和 queue 有关的,所以提到层序遍历一定要想到队列。遍历第 i 层时一定要把该层的所有结点
都遍历一遍。有时候题目会要求把所有结点按层次分类。这时候就需要在层序遍历的同时记录下结点的层次。
**给定一棵树,我们可以得到前、中、后三种遍历顺序。假设给定某种顺序是否能画出一颗树呢?
如果只给定一种顺序是不能确定输的具体结构的。
但是 前序 + 中序 或者 后序 + 中序 两种情况是可以的。
讨论 前序 + 中序:
1、在前序中找到根节点(前序的首位元素)。
2、在中序中分别找到左子树和右子树的中序。
左子树的中序序列:根节点的前面部分。
右子树的中序序列:根节点的后面部分。
3、在前序中找到左右子树的前序
左子树前序:从根节点的下一个位置开始,长度为左子树中序序列的长度。
右子树前序:找完左子树前序序列以后剩下的就是右子树的前序序列。
我们考虑前序和中序的构造过程,是一个递归过程,所以我们得到左子树和右子树的前序和中序以后,
使用类似于 左子树 + 根节点 + 右子树 的分解方式,继续对左子树和右子树进行1、2、3步的操作。

版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
