
概述
MySQL最强大的功能之一就是能在数据检索的执行中连接(join)表。大部分的单表数据查询并不能满足我们的需求,这时候我们就需要连接一个或者多个表,并通过一些条件过滤筛选出我们需要的数据。
了解MySQL连接查询之前我们先来理解下笛卡尔积的原理。
数据准备
依旧使用上节的表数据(包含classes 班级表和students 学生表):
1 mysql> select * from classes; 2 +---------+-----------+ 3 | classid | classname | 4 5 | 1 | 初三一班 6 2 | 初三二班 7 3 | 初三三班 8 4 | 初三四班 9 10 4 rows in set 11 12 mysql students; 13 ---------+-------------+-------+---------+ 14 | studentid | studentname | score 15 16 | | brand | 97.5 17 | helen 96.5 18 | lyn 96 19 | sol 97 20 7 | b1 81 21 8 | b2 82 22 | 13 | c1 71 23 14 | c2 72.5 24 19 | lala 51 0 25 26 9 rows set
笛卡尔积
笛卡尔积:也就是笛卡尔乘积,假设两个集合A和B,笛卡尔积表示A集合中的元素和B集合中的元素任意相互关联产生的所有可能的结果。
比如A中有m个元素,B中有n个元素,A、B笛卡尔积产生的结果有m*n个结果,相当于循环遍历两个集合中的元素,任意组合。
笛卡尔积在SQL中的实现方式既是交叉连接(Cross Join)。所有连接方式都会先生成临时笛卡尔积表,笛卡尔积是关系代数里的一个概念,表示两个表中的每一行数据任意组合。
所以上面的表就是 4(班级表)* 9(学生表) = 36条数据;
笛卡尔积语法格式:
1 select cname1,cname2,... tname1,tname2,...; 2 or 3 select cname from tname1 join tname2 [join tname...];
图例表示:
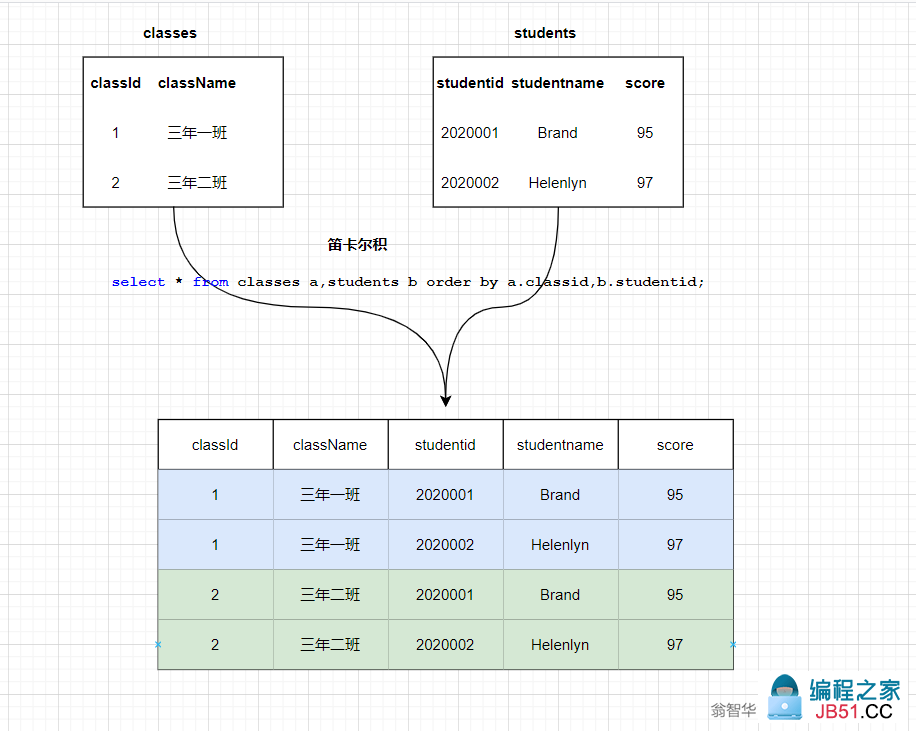
上述两个表实际执行结果如下:
from classes a,students b order by a.classid,b.studentid; -------+-----------+-----------+-------------+-------+---------+ -------+-----------+-----------+-------------+-------+---------+ 5 | 1 | 初三一班 | 1 | brand | 97.5 | 1 | 6 | 1 | 初三一班 | 2 | helen | 96.5 | 1 | 7 | 1 | 初三一班 | 3 | lyn | 96 | 1 | 8 | 1 | 初三一班 | 4 | sol | 97 | 1 | 9 | 1 | 初三一班 | 7 | b1 | 81 | 2 | 10 | 1 | 初三一班 | 8 | b2 | 82 | 2 | 11 | 1 | 初三一班 | 13 | c1 | 71 | 3 | 12 | 1 | 初三一班 | 14 | c2 | 72.5 | 3 | 13 | 1 | 初三一班 | 19 | lala | 51 | 0 | 14 | 2 | 初三二班 | 1 | brand | 97.5 | 1 | 15 | 2 | 初三二班 | 2 | helen | 96.5 | 1 | 16 | 2 | 初三二班 | 3 | lyn | 96 | 1 | 17 | 2 | 初三二班 | 4 | sol | 97 | 1 | 18 | 2 | 初三二班 | 7 | b1 | 81 | 2 | 19 | 2 | 初三二班 | 8 | b2 | 82 | 2 | 20 | 2 | 初三二班 | 13 | c1 | 71 | 3 | 21 | 2 | 初三二班 | 14 | c2 | 72.5 | 3 | 22 | 2 | 初三二班 | 19 | lala | 51 | 0 | 23 | 3 | 初三三班 | 1 | brand | 97.5 | 1 | 24 | 3 | 初三三班 | 2 | helen | 96.5 | 1 | 25 | 3 | 初三三班 | 3 | lyn | 96 | 1 | 26 | 3 | 初三三班 | 4 | sol | 97 | 1 | 27 | 3 | 初三三班 | 7 | b1 | 81 | 2 | 28 | 3 | 初三三班 | 8 | b2 | 82 | 2 | 29 | 3 | 初三三班 | 13 | c1 | 71 | 3 | 30 | 3 | 初三三班 | 14 | c2 | 72.5 | 3 | 31 | 3 | 初三三班 | 19 | lala | 51 | 0 | 32 | 4 | 初三四班 | 1 | brand | 97.5 | 1 | 33 | 4 | 初三四班 | 2 | helen | 96.5 | 1 | 34 | 4 | 初三四班 | 3 | lyn | 96 | 1 | 35 | 4 | 初三四班 | 4 | sol | 97 | 1 | 36 | 4 | 初三四班 | 7 | b1 | 81 | 2 | 37 | 4 | 初三四班 | 8 | b2 | 82 | 2 | 38 | 4 | 初三四班 | 13 | c1 | 71 | 3 | 39 | 4 | 初三四班 | 14 | c2 | 72.5 | 3 | 40 | 4 | 初三四班 | 19 | lala | 51 | 0 | 41 42 36 rows set
这样的数据肯定不是我们想要的,在实际应用中,表连接时要加上限制条件,才能够筛选出我们真正需要的数据。
我们主要的连接查询有这几种:内连接、左(外)连接、右(外)连接,下面我们一 一来看。
内连接查询 inner join
语法格式:
from tname1 inner join tname2 on join condition; 或者 from tname1 join tname2 on join4 5 from tname1,tname2 [where join condition];
说明:在笛卡尔积的基础上加上了连接条件,组合两个表,返回符合连接条件的记录,也就是返回两个表的交集(阴影)部分。如果没有加上这个连接条件,就是上面笛卡尔积的结果。

select a.classname,b.studentname,b.score from classes a join students b on a.classid = b.classid; ---------+-------------+-------+ 11 12 8 rows set
从上面的数据可以看出 ,初三四班 classid = 4,因为没有关联的学生,所以被过滤掉了;lala 同学的classid=0,没法关联到具体的班级,也被过滤掉了,只取两表都有的数据交集
where a.classid = b.classid and a.classid=1; set
查找1班同学的成绩信息,上面语法格式的第三种,这种方式简洁高效,直接在连接查询的结果后面进行Where条件筛选。
左连接查询 left join
left join on / left outer join on,语法格式:
from tname1 left join tname2 on join condition;
说明: left join 是left outer join的简写,全称是左外连接,外连接中的一种。 左(外)连接,左表(classes)的记录将会全部出来,而右表(students)只会显示符合搜索条件的记录。右表无法关联的内容均为null。
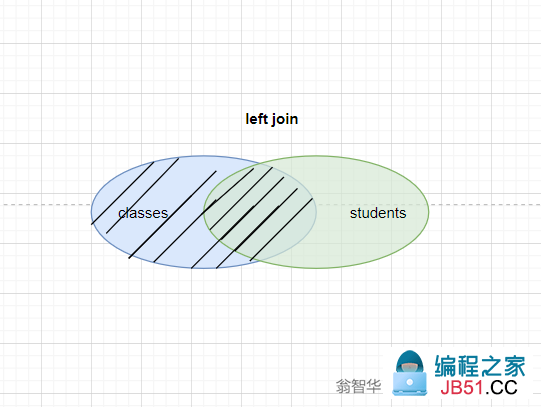
from classes a left | NULL NULL set
从上面结果中可以看出,初三四班无法找到对应的学生,所以后面两个字段使用null标识。
右连接查询 right join
right join on / right outer join on,语法格式:
right on join condition;
说明:right join是right outer join的简写,全称是右外连接,外连接中的一种。与左(外)连接相反,右(外)连接,左表(classes)只会显示符合搜索条件的记录,而右表(students)的记录将会全部表示出来。左表记录不足的地方均为NULL。

NULL set
从上面结果中可以看出,lala同学无法找到班级,所以班级名称字段为null。
连接查询+聚合函数
使用连接查询的时候,经常会配合使用聚集函数来进行数据汇总。比如在上面的数据基础上查询出每个班级的人数和平均分数、班级总分数。
select a.classname as '班级名称',count(b.studentid) 总人数sum(b.score) 总分avg(b.score) 平均分' 2 b.classid 3 group by a.classid,a.classname; --------+--------+--------+-----------+ | 班级名称 | 总人数 | 总分 | 平均分 | 初三一班 | 387.00 96.750000 | 初三二班 163.00 81.500000 | 初三三班 143.50 71.750000 3 rows set
这边连表查询的同时对班级(classid,classname)做了分组,并输出每个班级的人数、平均分、班级总分。
连接查询附加过滤条件
使用连接查询之后,大概率会对数据进行在过滤筛选,所以我们可以在连接查询之后再加上where条件,比如我们根据上述的结果只取出一班的同学信息。
= b.classid where a.classid=1set
如上,只输出一班的同学,同理,可以附件 limit 限制,order by排序等操作。
总结
1、连接查询必然要带上连接条件,否则会变成笛卡尔乘积数据,使用不正确的联结条件,也将返回不正确的数据。
2、SQL规范推荐首选INNER JOIN语法。但是连接的几种方式本身并没有明显的性能差距,性能的差距主要是由数据的结构、连接的条件,索引的使用等多种条件综合决定的。
我们应该根据实际的业务场景来决定,比如上述数据场景:如果要求返回返回有学生的班级就使用 inner join;如果必须输出所有班级则使用left join;如果必须输出所有学生,则使用right join。
3、性能上的考虑,MySQL在运行时会根据关联条件处理连接的表,这种处理可能是非常耗费资源的,连接的表越多,性能下降越厉害。所以要分析去除那些不必要的连接和不需要显示的字段。
之前我的项目团队在优化旧的业务代码时,发现随着业务的变更,某些数据不需要显示,对应的某个连接也不需要了,去掉之后,性能较大提升。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。