
介绍
大家好,我是Leo。前面文章我们介绍了WAL的安全机制。可以保证数据的安全性。通过安全性我们分析了binlog,redolog日志的写入机制。今天我们分析一下主从库的实现原理!MySQL是如何保证主从库的数据是一致的呢?

写作思路
根据读者与朋友的反馈,每篇文章我会加一块写作思路。让读者能更好的吸收相关知识,以及判断是否是自己所需要的知识。
主从同步的基本流程
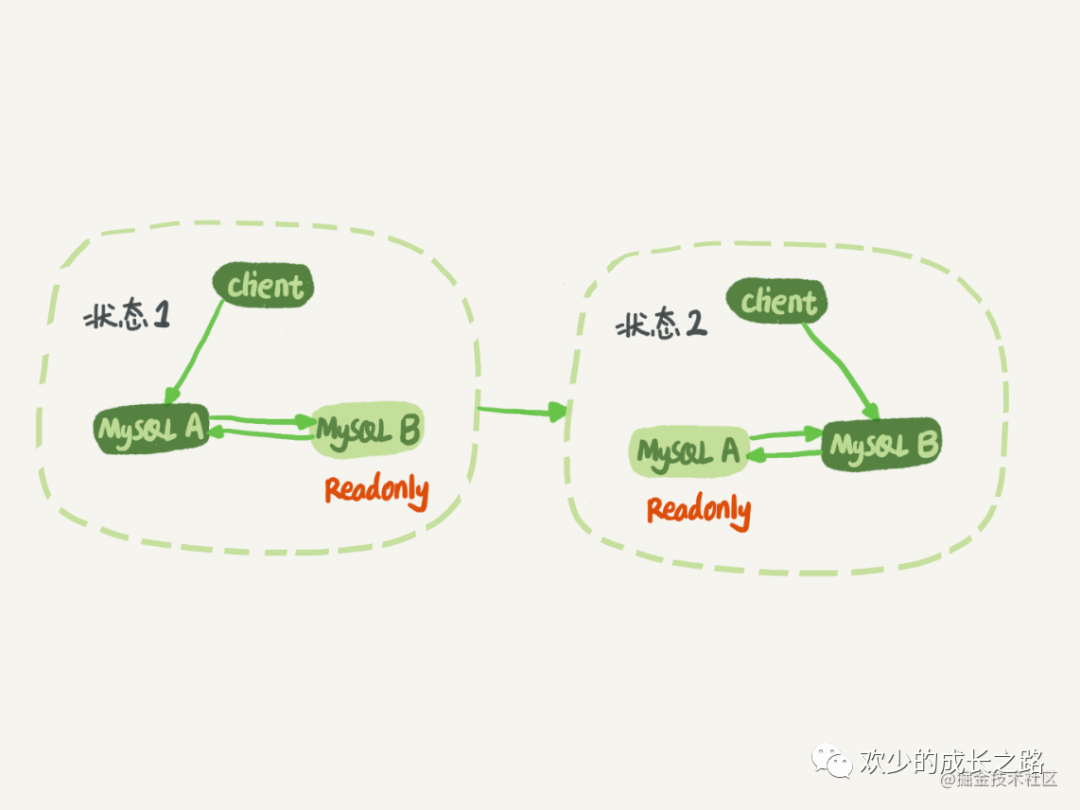
如下图所示,这是主从库的状态图。

- 状态1:用户端访问MySQLA,A是主库,B是从库,B同步A的数据。
- 状态2:用户端访问MySQLB,B是主库,A是从库,A同步B的数据。
主从在需要切换的时候就是由状态1转变成状态2的这个过程。
数据在从A同步B或者B同步到A。同步的线程具有超级管理员的权限。所以建议把从库设置成readonly模式的。因为这样可以避免主从同步的一个 “坑” 就是下面的双写。所以设置readonly百利而无一害。
- 可以防止其他运营的类的查询语句的误操作。造成数据不一致的问题
- 可以防止状态1和状态2在切换的时候也会有一些逻辑性的BUG问题
接下来我们把流程的每一步分析一下,如下图所示
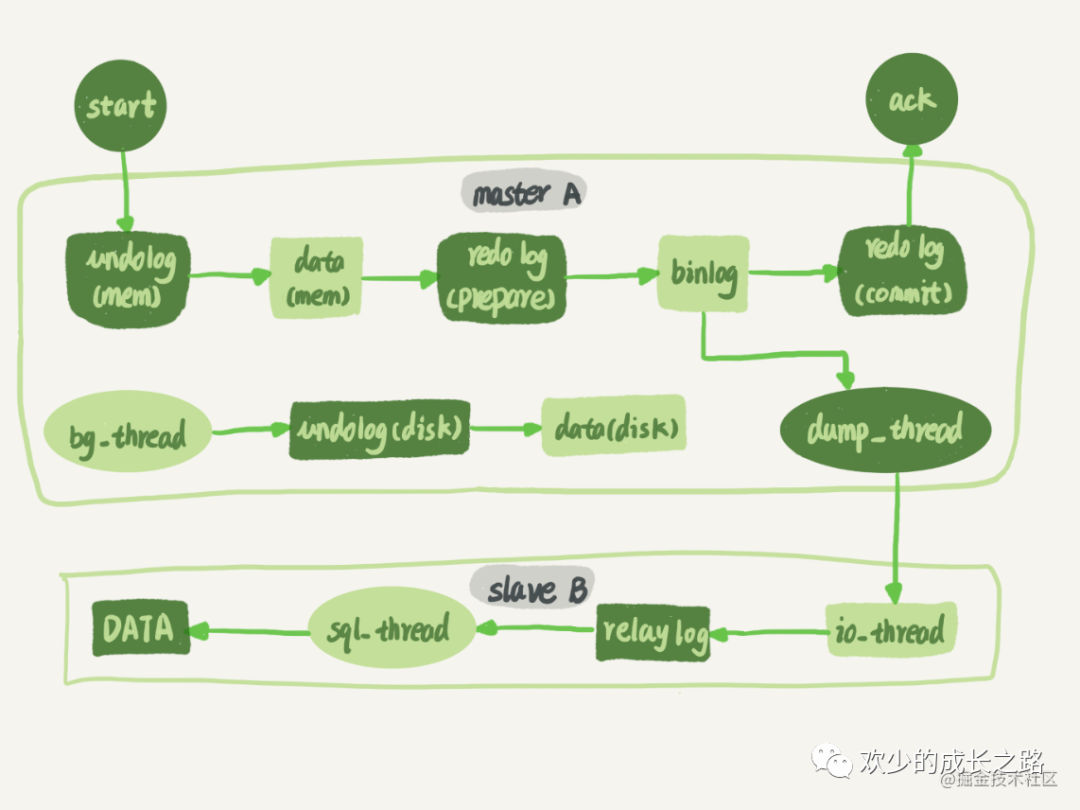
- 在备库 B 上通过 change master 命令,设置主库 A 的 IP、端口、用户名、密码,以及要从哪个位置开始请求 binlog,这个位置包含文件名和日志偏移量
- 在备库 B 上执行 start slave 命令,这时候备库会启动两个线程,就是图中的 io_thread 和 sql_thread。其中 io_thread 负责与主库建立连接。
- 主库 A 校验完用户名、密码后,开始按照备库 B 传过来的位置,从本地读取 binlog,发给 B。
- 备库 B 拿到 binlog 后,写到本地文件,称为中转日志(relay log)。
- sql_thread 读取中转日志,解析出日志里的命令,并执行。
sql_thread线程我们在今后的文章中会详细介绍。这里就不做过多解释了!
根据上面的流程,我们一点一点剖析底层的流程。先来了解一下binlog传输吧
binlog格式的华山论剑
说到binlog传输的话,我们肯定要聊到它的格式问题。binlog常见的格式有两种,一种是statement,一种是row。还有一种格式叫作mixed。这种格式是前面两种格式的混合体。
下面我们举例论述一下
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`t_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `t_modified`(`t_modified`)
) ENGINE=InnoDB;
insert into t values(1,1,'2018-11-13');
insert into t values(2,2,'2018-11-12');
insert into t values(3,3,'2018-11-11');
insert into t values(4,4,'2018-11-10');
insert into t values(5,5,'2018-11-09');
我们先简单的执行一条删除语句,查看一下对应的binlog日志到底是什么样的。
mysql> delete from t /*comment*/ where a>=4 and t_modified<='2018-11-10' limit 1;
当binlog格式属于第一种情况时。 statement
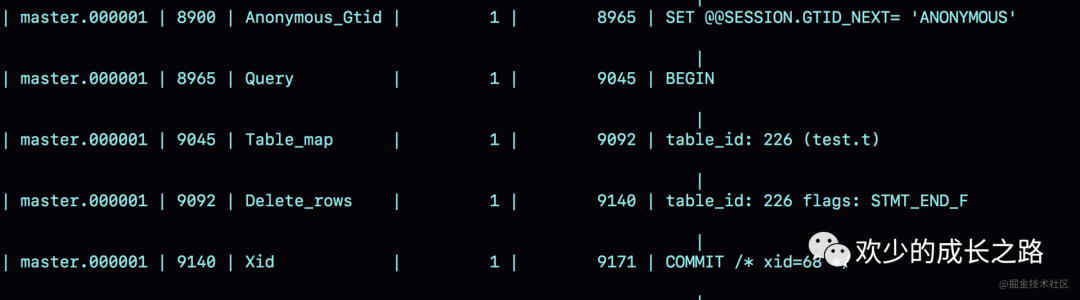
binlog里面记录的是SQL语句的原文。可以用 mysql> show binlog events in 'master.000001'; 查看

分析图上的结果。
- 第一行 SET @@SESSION.GTID_NEXT='ANONYMOUS’你可以先忽略,后面文章我们会在介绍主备切换的时候再提到;
- 第二行是一个 BEGIN,跟第四行的 commit 对应,表示中间是一个事务;
- 第三行就是真实执行的语句了。可以看到,在真实执行的 delete 命令之前,还有一个“use ‘test’”命令。这条命令不是我们主动执行的,而是 MySQL 根据当前要操作的表所在的数据库,自行添加的。这样做可以保证日志传到备库去执行的时候,不论当前的工作线程在哪个库里,都能够正确地更新到 test 库的表 t。use 'test’命令之后的 delete 语句,就是我们输入的 SQL 原文了。可以看到,binlog“忠实”地记录了 SQL 命令,甚至连注释也一并记录了。
- 最后一行是一个 COMMIT。你可以看到里面写着 xid=61。
还记得xid是啥意思吗,我们一起回顾一下吧。
xid是binlog与redo log共同的数据字段,崩溃恢复的时候,会按顺序扫描redo log
- 如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
- 如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。
为了说明 statement 和 row 格式的区别,我们来看一下这条 delete 命令的执行效果图

可以看到,这条delete产生了一条warning。是因为当前binlog设置的是statement格式的。并且delete带有limit,很可能会出现主从库数据不一致的情况。比如上面这个例子。
- 如果 delete 语句使用的是索引 a,那么会根据索引 a 找到第一个满足条件的行,也就是说删除的是 a=4 这一行;
- 但如果使用的是索引 t_modified,那么删除的就是 t_modified='2018-11-09’也就是 a=5 这一行。
由于 statement 格式下,记录到 binlog 里的是语句原文,因此可能会出现这样一种情况:在主库执行这条 SQL 语句的时候,用的是索引 a;而在备库执行这条 SQL 语句的时候,却使用了索引 t_modified。因此,MySQL 认为这样写是有风险的。
那么,如果我把 binlog 的格式改为 binlog_format=‘row’, 是不是就没有这个问题了呢?我们先来看看这时候 binog 中的内容吧。
可以看到,与 statement 格式的 binlog 相比,前后的 BEGIN 和 COMMIT 是一样的。但是,row 格式的 binlog 里没有了 SQL 语句的原文,而是替换成了两个 event:Table_map 和 Delete_rows。
- Table_map event,用于说明接下来要操作的表是 test 库的表 t;
- Delete_rows event,用于定义删除的行为。
把格式改成row的话,我们是看不到详细信息的。还需要借助mysqlbinlog工具,用下面这个命令解析和查看binlog中的内容。从上图可以得知,这个事务的binlog是从8900这个位置开始的。所以可以用 start-position 参数来指定从这个位置的日志开始解析。
mysqlbinlog -vv data/master.000001 --start-position=8900;
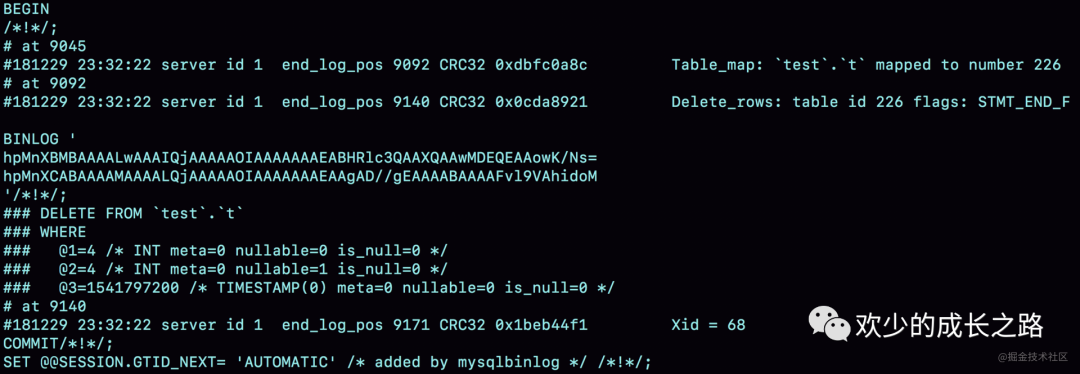
- server id 1,表示这个事务是在 server_id=1 的这个库上执行的。
- 每个 event 都有 CRC32 的值,这是因为我把参数 binlog_checksum 设置成了 CRC32。
- Table_map event 跟在图 5 中看到的相同,显示了接下来要打开的表,map 到数字 226。现在我们这条 SQL 语句只操作了一张表,如果要操作多张表呢?每个表都有一个对应的 Table_map event、都会 map 到一个单独的数字,用于区分对不同表的操作。
- 我们在 mysqlbinlog 的命令中,使用了 -vv 参数是为了把内容都解析出来,所以从结果里面可以看到各个字段的值(比如,@1=4、 @2=4 这些值)。
- binlog_row_image 的默认配置是 FULL,因此 Delete_event 里面,包含了删掉的行的所有字段的值。如果把 binlog_row_image 设置为 MINIMAL,则只会记录必要的信息,在这个例子里,就是只会记录 id=4 这个信息。
- 最后的 Xid event,用于表示事务被正确地提交了。
你可以看到,当 binlog_format 使用 row 格式的时候,binlog 里面记录了真实删除行的主键 id,这样 binlog 传到备库去的时候,就肯定会删除 id=4 的行,不会有主备删除不同行的问题。
miexed是啥,给binlog起到了哪些作用
想要解决这个问题, 就需要说明一下row格式的binlog与statement格式的binlog有啥优缺点!
statement 记录的是大概的信息,几乎是我们的执行信息,我们看不到具体的逻辑是什么。所以如果同步到从库上,很容易会发现数据不一致的情况,所以出现了row格式。
row row格式解决了statement的缺点。可以查到执行的详细信息,但是缺点也是相应暴露了出来,过于详细导致内存占用过大。比如删除一个几万的数据。row格式的binlog会记录每个数值记录。这样不仅会占用过多的空间,还会占用磁盘IO,影响整个MySQL的执行效率
miexed 横空出世,解决了statement不一致的问题,同时也解决了row格式的占用内存过大的缺点。主要的实现就是他会判断一下,这个binlog会不会引起数据不一致这个问题。如果会引起,那么久采用row格式的。如果不会引起,那么久采用statement格式的日志。
因此,如果你的线上 MySQL 设置的 binlog 格式是 statement 的话,那基本上就可以认为这是一个不合理的设置。你至少应该把 binlog 的格式设置为 mixed。
比如我们这个例子,设置为 mixed 后,就会记录为 row 格式;而如果执行的语句去掉 limit 1,就会记录为 statement 格式。
接下来,我们就分别从 delete、insert 和 update 这三种 SQL 语句的角度,来看看数据恢复的问题。
如果我执行的是 delete 语句,row 格式的 binlog 也会把被删掉的行的整行信息保存起来。所以,如果你在执行完一条 delete 语句以后,发现删错数据了,可以直接把 binlog 中记录的 delete 语句转成 insert,把被错删的数据插入回去就可以恢复了。
如果你是执行错了 insert 语句呢? 那就更直接了。row 格式下,insert 语句的 binlog 里会记录所有的字段信息,这些信息可以用来精确定位刚刚被插入的那一行。这时,你直接把 insert 语句转成 delete 语句,删除掉这被误插入的一行数据就可以了。
如果执行的是 update 语句的话,binlog 里面会记录修改前整行的数据和修改后的整行数据。所以,如果你误执行了 update 语句的话,只需要把这个 event 前后的两行信息对调一下,再去数据库里面执行,就能恢复这个更新操作了。
其实,由 delete、insert 或者 update 语句导致的数据操作错误,需要恢复到操作之前状态的情况,也时有发生。MariaDB 的Flashback工具就是基于上面介绍的原理来回滚数据的。
案例问题
虽然 mixed 格式的 binlog 现在已经用得不多了,但这里我还是要再借用一下 mixed 格式来说明一个问题,来看一下这条 SQL 语句 mysql> insert into t values(10,10, now());
如果我们把 binlog 格式设置为 mixed,你觉得 MySQL 会把它记录为 row 格式还是 statement 格式呢?

由输出结果得知,走的是statement格式。那如果传给主库同步的话,那里的时间肯定是不准的,造成主从库数据不一致啊。
接下来我们拿xid 用mysqlbinlog工具看一下

这里多了一个指令:SET TIMESTAMP=1546103491 它用 SET TIMESTAMP 命令约定了接下来的 now() 函数的返回时间。
因此,不论这个 binlog 是 1 分钟之后被备库执行,还是 3 天后用来恢复这个库的备份,这个 insert 语句插入的行,值都是固定的。也就是说,通过这条 SET TIMESTAMP 命令,MySQL 就确保了主备数据的一致性。
error: 一定不要用mysqlbinlog工具解析出数据,然后直接把里面的statement语句直接拷贝出来执行。这样的操作是有风险的。所以一定要把整个结构都发给MySQL执行。
主从同步的循环复制问题
在我们真实的开发场景中,往往主库不会一直是主库,从库不会一直是从库。为了保证安全性。往往是这样设计的。
这样的就会出现另一个问题。业务逻辑在节点 A 上更新了一条语句,然后再把生成的 binlog 发给节点 B,节点 B 执行完这条更新语句后也会生成 binlog。(我建议你把参数 log_slave_updates 设置为 on,表示备库执行 relay log 后生成 binlog)。
那么,如果节点 A 同时是节点 B 的备库,相当于又把节点 B 新生成的 binlog 拿过来执行了一次,然后节点 A 和 B 间,会不断地循环执行这个更新语句,也就是循环复制了。这个要怎么解决呢?
解决方案:
- 规定两个库的 server id 必须不同,如果相同,则它们之间不能设定为主备关系;
- 一个备库接到 binlog 并在重放的过程中,生成与原 binlog 的 server id 相同的新的 binlog;
- 每个库在收到从自己的主库发过来的日志后,先判断 server id,如果跟自己的相同,表示这个日志是自己生成的,就直接丢弃这个日志。
按照这个逻辑,如果我们设置了双 M 结构,日志的执行流就会变成这样:
- 从节点 A 更新的事务,binlog 里面记的都是 A 的 server id;
- 传到节点 B 执行一次以后,节点 B 生成的 binlog 的 server id 也是 A 的 server id;
- 再传回给节点 A,A 判断到这个 server id 与自己的相同,就不会再处理这个日志。所以,死循环在这里就断掉了。
总结
这篇文章,我们介绍了MySQL是怎么保证主从库数据一致的原因,实现流程,binlog三种格式的优缺点,线上场景的MySQL主从库应用配置,主从库互相切换的循环复制问题以及解决方案。
知道的越多,不知道的就越多!愿今后的岁月,不忘初心,努力学习!都有一个不辜负的人生!
有任何问题都可以在一起讨论。点赞+评论+关注是对博主最好的支持!
原文地址:https://cloud.tencent.com/developer/article/1893878
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。