

作者简介
蓝寅,开源分布式中间件DBLE项目负责人;持续专注于数据库方面的技术, 始终在一线从事开发;对数据复制,读写分离,分库分表的有深入的理解与实践。
问题起因
用benchmarksql_for_MysqL对原生MyCAT-1.6.1和DBLE-2.17.07版做性能测试对比,发现DBLE性能只到原生版MyCAT的70%左右。
问题分析过程
分析过程主要有以下内容:包括现象,收集数据,分析猜测原因,验证猜测的方式来进行。
1.分析瓶颈
通过对cpu火焰图的比较,发现DBLE用在纯排序上的cpu占用在15%以上,而MyCAT在排序上没有看到明显的cpu占用。( 复盘时的思考:这里有明显的可疑之处,应当及早观察两者是否公平)
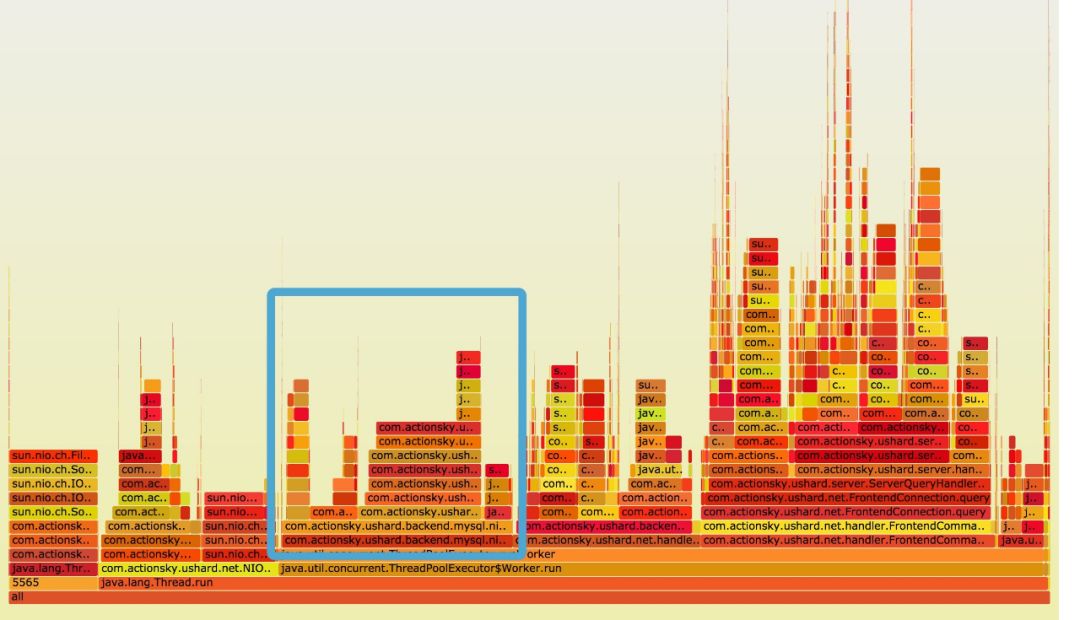
1.2 首先猜测可能的原因
-
a.由于MyCAT对以下这条用例实现有bug,实现方式是直接下发sql,收到结果后做加法;而DBLE则是收集所有列的结果集,然后检查该数据是否会存在,其实存在一个比较的过程。所以对比的两者在这个case上是不公平的。
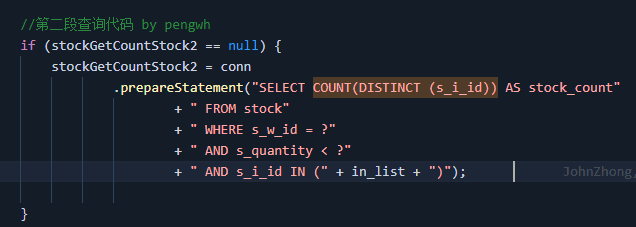
1.3 对猜测原因的验证
2.分析DBLE排序的问题
2.1 猜测一:源码实现原因
-
2.1.1 猜测描述
梳理DBLE源码排序逻辑的实现细节,是多路归并的排序,理论上是最优选择。
实际上具体的实现上有可优化的空间,如下图, N个数的K路排序的初始化值理论最优复杂度是O(N),而这里变成了O(N*logK*2) ,并且由于K本身是4,所以这里的2不能忽视。
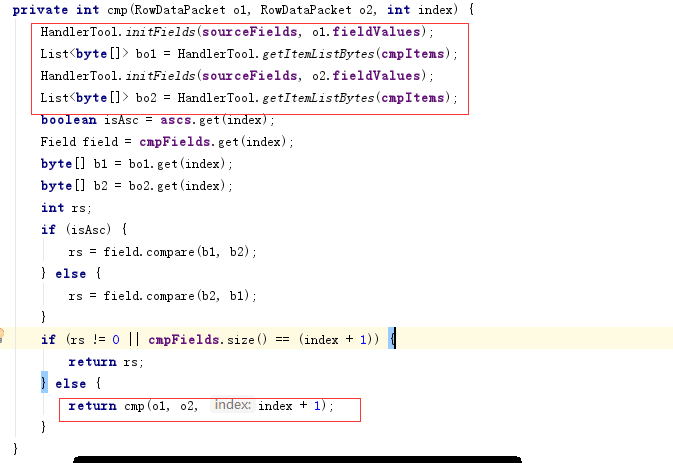
-
2.1.2 验证猜测
为了快速将排序的因素排除,将cmp函数直接返回1再次做测试。结果提升了10%的性能,所以虽然cmp是有性能问题,但致性能如此大还有其他原因。Todo()
2.2 猜测二:limit不公平原因
-
2.2.1 猜测描述
由于DBLE实现时,对聚合函数以及排序的sql并没有做limit 的改写,猜测是这样导致的不公平。
-
2.2.2 验证猜测
将limit配置改到10000,测试结果是性能问题仍旧。
解释:即使没有limit 100的sql改写,本身结果集也就平均为大约300以内,并不会造成如此大的差异。(复盘思考:这里应当做一次函数调用统计来证明排序次数是公平的)
2.3 猜测三:线程池实现原因
-
2.3.1 猜测描述
DBLE线程池有2个,一个是专门处理复杂查询的,是个无界的线程池。而mycat只有一个有界的线程池。
-
2.3.2 验证猜测
2.4 猜测四:并发数有关
验证:将压力并发数改成1,仍然有10%的性能差距。
2.5 猜测五:回到排序sql
之上的猜测都没有命中,重新回到排序sql;
查看源码和抓包的输出,发现MyCAT对排序有bug却没有报出响应的错误。查看原因是B-sql的排序case实际只使用了1个(这里吐槽下B-sql的实现,HardCode使得)。所以以上所有的性能问题是都是一个排序sql引起的。
-
2.5.1 考察 单个sql排序
使用单一排序的sysbench压力压排序,结果诡异:
这个结论和B-sql复合压测结论是相反的,B-sql的结论是:
-
1.没有排序的情况下,MyCAT和DBLE性能相当
-
2.排序参与的情况下,单线程压力,DBLE下降10%。
-
3.排序参与的情况下,多线程压力,DBLE下降接近30%。
2.5.2 收集线程信息
-
发现MyCAT的BussinessExecutor为1024,高出DBLE很多。
-
查看配置原因是MyCAT和DBLE配置参数不同导致的。
2.7 调整参数 校准结果,结论如下:
-
1.sysbench多线程压测唯一的ORDER BY, DBLE的性能变得更好。
-
2.B-sql多线程压力(排除排序),DBLE性能变为MyCAT的90%(未调参数时性能相同的现象解释:MyCAT开了过大的线程池影响了性能)
3.分析多线程10%性能差距原因
3.1 猜测聚合函数的影响
-
3.1.1 猜测描述
猜测这10%是由于聚合函数引起的,但yourkit的结果并不支持这个擦测。
-
3.1.2 猜测验证
3.2 猜测流量不同
-
3.2.1 猜测描述
猜测发给MyCAT 和DBLE的流量不同导致延迟
-
3.2.2 测试验证
单线程压力抓包分析DBLE会多发一个SET SESSION TRANSACTION ISOLATION,但理论上不会有更大的延迟(复盘思考:这里其实是很重要的线索,不应放掉每一处不同的细节)。
3.3 观测发现线程切换问题
-
3.3.1 perf观测结果发现DBLE的线程切换远大于mycat
通过yourkit观察调用发现DBLE采用的是异步处理IO,MyCAT是同步的。
这个变更是因为前后端连接池是公用的,前端同步IO在某些场景会阻塞等待后端IO的返回结果,可能引发死锁。(注:未来考虑需要阻塞的部分和计算过于复杂的IO请求变更为异步的,其余部分用同步即可)
-
3.3.2 验证测试:
考虑在目前测试场景中并没有引发死锁的case,将代码变更回滚。(注:实际是有的,复杂查询建立新连接时就会, 简单的代码回滚会有hang死的问题,此问题可以在hang住时通过jstack发现)
结论:
-
1:配置16/64, 单线程, SELECT压测, IO模型改为NIO同步:
DBLE性能略好于MyCAT。
-
2:配置16/64, Bsql压测参数228/256, 去除ORDER_BY/AGGR, IO模型改为NIO同步:
DBLE性能与MyCAT相同
至此,IO问题影响10%的性能确认。未来对此项需要做改进 。
4.回到排序问题
4.1 改进cmp函数问题
-
4.1.1 改进cmp函数问题
修改DBLE源码,将cmp中的初始化逻辑复杂度改为O(n)。
-
4.1.2 验证测试
-
1.配置40/64, sysbench 32并发压order by, IO模型改为NIO同步, 时间60s, 前30s预热, 取后30s数据,DBLE为无limit版本,MyCAT单压力需要排序的数据有400条,DBLE是2000+条:
DBLE明显差于MyCAT,大约只有1/3.
-
2.配置40/64, sysbench 1并发压order by, IO模型改为NIO同步, 时间60s, 前30s预热, 取后30s数据,DBLE为无limit版本,MyCAT单压力需要排序的数据有400条,DBLE是2000+条:
DBLE性能是MyCAT的85%左右。
-
3.配置40/64, sysbench 1并发压order by, IO模型改为NIO同步, DBLE 改进了cmp函数,DBLE为无limit版本,mycat单压力需要排序的数据有400条,DBLE是2000+条:
DBLE性能和MyCAT相当。
结论:改进cmp有效。
4.2 改进limit 问题
-
4.2.1 改进cmp函数问题
修改DBLE源码,将复杂查询中的聚合函数和排序加上limit逻辑。
-
4.2.2 验证测试
-
1.配置40/64, sysbench 1并发压order by, IO模型改为NIO同步, DBLE 改进了cmp, 修改MyCAT参数sqlLimit = 100000,使得mycat和DBLE单压力需要排序的数据都是2000+条:
DBLE排序性能是mycat的3倍以上。
-
2.配置40/64, sysbench 32并发压order by,DBLE 改进了cmp,两边都增加limit 100改写逻辑:
DBLE排序性能是MyCAT的3倍左右。
结论:limit改进有效。
5.复合B-sql压力问题
继续验证时但在使用B-sql复合压力时,仍然有问题出现:
现象如下:
-
2.64数据量,64并发,DBLE的性能迅速下降为mycat的65%左右,严重不符合预期。
-
3.有时会发生1205 lock wait timeout 的问题。
对于现象3 ,原因是DBLE和mycat对分布式事务处理方式不同,事务中,DBLE即使碰到插入数据主键冲突也要显式rollback,而B-sql的代码中没有做这个步骤,导致可能会在MysqL节点上有未提交的事务,如果超过innodb_lock_wait_timeout(50s)的设置就会发生。
所以问题就集中在现象2上了。
5.1 猜测原因是并发太多
-
5.1.1 猜测描述
并发数可能影响排序性能。
-
5.1.2 验证猜测
将排序除去,64数据量,64并发,DBLE的性能是MyCAT的96%。
证明确实和排序有关。
6.分析多并发压力排序性能的原因
6.1 猜测排序算法在特殊场景下的适用性
-
6.1.1 猜测描述
由于MyCAT排序采用的是timsort, 时间复杂度的可能最优是O(n)。
而DBLE的多路归并排序在B-sql这个场景下时间复杂度最差情况是O(n*(k-1)).
猜测timsort排序在B-sql多并发场景下可能会优于多路归并。
-
6.1.2 验证猜测
结论:
1.在sysbench场景下,
2.在B-sql场景下,
7. 分析DBLE的cmp函数次数调用多的原因
7.1 猜测是count(distinct) 的原因
-
7.1.1 猜测描述
因为有count(distinct) 的实现,所以DBLE 需要排序的次数多。
-
7.1.2 验证猜测
-
a.只去掉聚合函数 ,性能接近,这与之前测试与order by强相关性不符合。(复盘思考:这次测试可能是个偶然情况,恰好没有踩中B-sql的坑)
-
b.只去掉排序,性能接近。
-
c.尝试单独压测count(distinct) ,发现DBLE性能是mycat的76%,这无法解释复合压力35%的性能差距。
因为上述矛盾的结论,这里走了一些弯路,把焦点集中在了线程切换的消耗上了,尝试修改线程模型并测试发现相关性不强。
-
d.为了再次验证count(distinct)对性能的强相关性,将原版B-sql的count(distinct)直接改成count(*),结果发现即使除去IO模型的影响,DBLE仍然是MyCAT性能的75%左右。
在这种情况下yourkit拉取函数调用次数,发现DBLE比较函数(cmp)的调用次数是mycat的7倍以上,说明现象与 count(distinct)并不强相关。
8. 分析DBLE排序时cmp函数次数调用多的原因
8.1 验证压力下发的sql是否与cmp函数调用相符是否下发的sql就不公平
-
8.1.1收集数据
-
用抓包的方式分别抓取B-sql发给MyCAT和DBLE的包,结果发现 DBLE的所有sql中排序这条sql的发生次数是MyCAT的10倍左右。
-
再次用yourkit 查看调用次数和cpu分布验证,发现调用次数确实符合抓包的结论,cpu分布也是DBLE分了大量的时间用于排序,而MyCAT对排序的分配几乎可以忽略。这也与最一开始的火焰图结论一样。
-
用wireshark分析DBLE抓包结果,发现某条连接大量的出现排序+delete的连续请求直到压力结束。
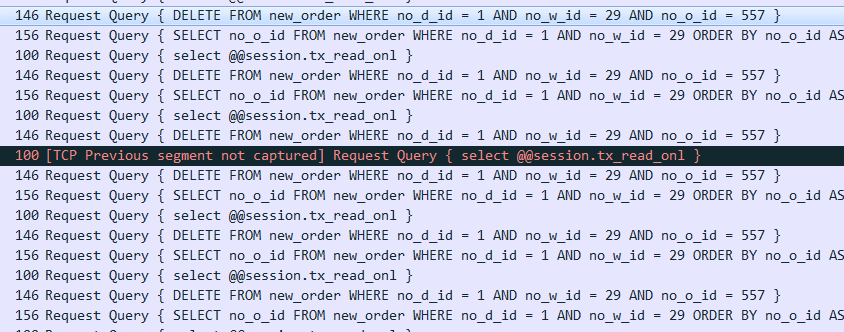
-
8.1.2 分析原因
分析B-sql源码这里发现只有delete的数据为0才会引发死循环。

-
8.1.3 验证测试
在引发死循环的原因找到之前,先修改代码验证测试。无论result是否是0都设置newOrderRemoved=true使得B-sql跳出死循环。
验证测试,DBLE性能终于符合预期,是mycat的93%,如果改成IO模型为同步,则变为mycat的105%。
至此,B-sql有排序引发DBLE性能下降的原因找到了,某种场景下B-sql对DBLE执行delete,影响行数为0,导致此时会有死循环,发送了大量排序请求,严重降低了DBLE性能,并且并发压力越大越容易出现,但也有一定几率不会触发。
9.分析哪种场景下delete行数为0
9.1隔离级别测试
因为对隔离级别并不熟悉,花了很长时间才想到原因,在MysqL上做了一个实验:

也就是说,在并发情况下确实有可能有死循环出现。
9.2 分析一下为什么只有在DBLE上有这个问题而在MyCAT上没有这个问题
原因是DBLE和mycat的默认隔离级别都是REPEATED_READ,但mycat的实现有bug,除非客户端显式使用set语句,mycat后端连接使用的隔离级别都是下属结点上的默认隔离级别,而DBLE会在获取后端连接后同步上下文,使得session级别的隔离级别和DBLE配置相同。而后端的四个结点中除了102是REPEATED_READ,其他三个结点都是READ_COMMITTED。这样同样的并发条件,DBLE100%会触发,而mycat只有25%的概率触发。
9.3 验证测试
将DBLE上的配置添加<property name="txIsolation">2</property>(默认是3)与默认做对比,
10. 吐槽
最后吐槽一下B-sql,找了官方的B-sql4.1版和5.0版,4.1版并未对此情况做任何改进,仍有可能陷入死循环影响测试。
而5.0的对应代码处有这么一段注释,不知道PGsql是否这里真的会触发异常,但MysqL并不会触发异常,仍有可能陷入死循环。
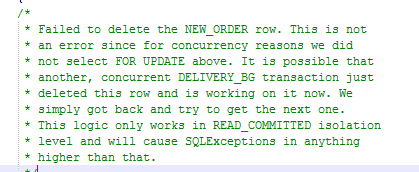
11. 性能原因回顾
1.IO模型的不同,DBLE有10%的损失。未来可以调整模型改进
2.cmp函数时候初始化值的问题,已改进。
3.limit的问题,已改进
4.配置参数的不同,要调整为一致。
5.隔离级别的问题,需要将MysqL结点都改为READ_COMMITED,再将配置改为<property name="txIsolation">2</property>,避开MyCAT和B-sql的bug。
6.不算性能问题,由于要保证分布式事务的原子性,事务中插入数据时发生类似主键冲突的错误也必须显式回滚,这点和MysqL行为不同,暂时没有更好的解决方案。
12. 收获
1.测试环境的搭建无论是配置参数还是各个节点的状态都要同步,保证公平。
2.性能分析工具的使用。
3.性能测试可能一次的结果具有偶然性,需要多次验证。
4.当有矛盾的结论时候,可能就快接近问题的真相了,需要持续关注。
最后,感谢黄炎对于性能优化的指导,感谢朱妮娜辛苦的测试与收集数据。
开源分布式中间件DBLE
GitHub主页:https://github.com/actiontech/dble
技术交流群:669663113
开源数据传输中间件DTLE
GitHub主页:https://github.com/actiontech/dtle
技术交流群:852990221
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
