
Replica Set在国内叫做副本集,简单来说就是一份数据在多个地方存储。
1.为什么要用副本集,什么时候使用副本集?
有人说一份数据在多个地方存储占用了大量的额外空间,是一种浪费。
这个说法不能说对也不能说不对,要从不同的角度考虑。如果公司的业务量很少,数据不多,一台服务器就可以搞定,那就不需要将一份数据存储在多个地方。随着公司的发展壮大,业务量越来越多,数据也越来越多,这时就需要考虑使用分布式集群的方式来解决了,将数据分散在不同的服务器中。此时仍可以不使用副本,通过将数据分散在不同的服务器中来分散各服务器的压力也可以跟上公司目前的业务量。如果公司规模进一步扩大,用户量越来越多,有可能很多客户要访问同一份资源,此时就有可能造成存放该资源的服务器压力过大。副本的必要性就显现出来了。
2.使用副本集有什么好处?
副本集提供了容错性,高可用性。当然容灾备份,读写分离等也使用到了副本。
3.MongoDB Replica Set集群介绍
先上一个典型的 Replica Set图:

为方便介绍,以下简称rs集群
(1).rs集群是由多个Mongod实例节点组成,其中只有一个节点是primary,其它节点是secondary,还有一个是可有可无的仲裁节点。当集群有偶数个节点时,通过会添加一个仲裁节点,如果集群有奇数个节点时,就不需要使用仲裁节点了。仲裁节点不存储数据,只用于投票选举出哪个节点是primary,而且仲裁节点不要求有专门的服务器,但不能运行在已经安装了primary或secondary节点的服务器上,可以运行在应用或监控服务器上(之前看到有人说仲裁节点除了投票外,还可以在primary节点失效后,在secondary节点中再选举出一个primary,这是不对的,仲裁节点的作用仅仅是有一票之权)。
(2).primary用于接收client的读和写请求,并记录操作日志,secondary用于从primary处异步同步primary的操作日志,并更新自己的数据集。通常情况下secondary不能响应client的读操作,以免读取脏数据。但rs集群有多个数据中心时,client可以请求读取secondary数据,当primay在北京的服务器上,其中一个Secondary在重庆,重庆的用户在读取数据时,考虑到地理位置和网速的关系,可选择只读primary,primary优先,只读secondary,secondary优先和读取最近(nearest)节点的数据。
(3).当primary不能访问时,剩下的secondary节点中会再选出一个primary节点。
4.RS集群部署示例
(1).有三台服务器,由于是奇数服务器,所以不选择仲裁节点。
(2).下载MongodDB手动安装版(我下载的是Linux 64位版本),并解压到一个目录下,将解压的文件夹名字改成mongoDB,进入mongoDB目录,新建一个配置文件mongod.conf
#mongod.conf
#数据保存路径
dbpath=mongodb/data/mongod
#日志保存路径
logpath=mongodb/log/mongod.log
logappend=true
#后台运行保存的进程pid
pidfilepath=/home/yanggy/mongodb/mongod.pid
#每个数据库一个目录
directoryperdb=true
#replica set的名字
replSet=testrs
#绑定IP与Host
bind_ip=server1
port=27001
#日志文件大小
oplogSize=100
#后台运行
fork=true
#不提前加载数据到内存
noprealloc=true
将此配置文件复制到其它服务器中,修改绑定的IP即可,并手动在各服务器建立相应的数据和日志目录。
(3).在各服务器启动mongod实例
mongod -f mongodb/mongod.conf
(4).使用mongo连接其中一台服务器
mongo --host server1 --port 27001
(5).初始化rs集群
> cfg = {_id:"testrs",members:[{_id:0,host:"server1:27001",priority:3},
{_id:1,host:"server2:27001",priority:2},
{_id:2,host:"server3:27001",priority:1}]}
输出:
{
"_id" : "testrs","members" : [
{
"_id" : 0,"host" : "server1:27001","priority" : 3
},{
"_id" : 1,"host" : "server2:27001","priority" : 2
},{
"_id" : 2,"host" : "server3:27001","priority" : 1
}
]
}
>rs.initiate(cfg)
输出:
{
"ok" : 1,"operationTime" : Timestamp(1521190572,1),"$clusterTime" : {
"clusterTime" : Timestamp(1521190572,"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),"keyId" : NumberLong(0)
}
}
}
>rs.status()
输出:
{
"set" : "testrs","date" : ISODate("2018-03-16T08:56:23.948Z"),"myState" : 1,"term" : NumberLong(1),"heartbeatIntervalMillis" : NumberLong(2000),"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(0,0),"t" : NumberLong(-1)
},"appliedOpTime" : {
"ts" : Timestamp(1521190572,"durableOpTime" : {
"ts" : Timestamp(1521190572,"t" : NumberLong(-1)
}
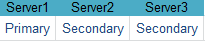
},"name" : "server1:27001","health" : 1,"state" : 1,"stateStr" : "PRIMARY","uptime" : 220,"optime" : {
"ts" : Timestamp(1521190572,"t" : NumberLong(-1)
},"optimeDate" : ISODate("2018-03-16T08:56:12Z"),"infoMessage" : "could not find member to sync from","electionTime" : Timestamp(1521190582,"electionDate" : ISODate("2018-03-16T08:56:22Z"),"configVersion" : 1,"self" : true
},"name" : "server2:27001","state" : 2,"stateStr" : "SECONDARY","uptime" : 11,"optimeDurable" : {
"ts" : Timestamp(1521190572,"optimeDurableDate" : ISODate("2018-03-16T08:56:12Z"),"lastHeartbeat" : ISODate("2018-03-16T08:56:22.733Z"),"lastHeartbeatRecv" : ISODate("2018-03-16T08:56:19.659Z"),"pingMs" : NumberLong(0),"configVersion" : 1
},"name" : "server3:27001","lastHeartbeatRecv" : ISODate("2018-03-16T08:56:19.641Z"),"configVersion" : 1
}
],"ok" : 1,"$clusterTime" : {
"clusterTime" : Timestamp(1521190582,"keyId" : NumberLong(0)
}
}
}
可以看到priority值越大的节点越有可能成为primary。
好了,相信大家对Replica Set已经有了初步体验和认识,如果上文中有什么表述的不准备或者错误的地方,欢迎指出,大家共同探讨进步。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。