
1.创建数据库
语法
use 数据库名字
例如:创建hero数据库
use hero
查询当前数据库
db

如果想查询所有的数据库
show dbs
发现并没有刚刚创建的数据库,如果要显示创建的数据库,需要向表中插入一条记录
db.hero.insert({
name: "zs",age: 20,country: "china",sex: "男",idno: "2131243234"
})
表数据
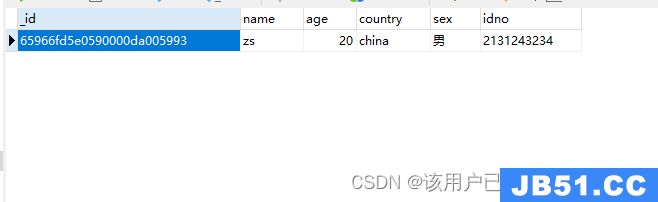
显示数据库hero

2.删除数据库
创建数据库test,并删除
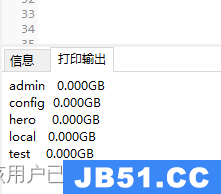
删除test数据库命令
db.dropDatabase()
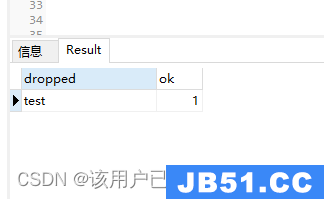
查询所有的数据库,test已经删除
show dbs
3.创建集合
创建集合命令
db.createCollection(name,options)
name:创建集合的名字
options:可选参数,指定有关内存大小及索引的选项,可以是下面的参数
capped:布尔值,如果为true,会创建固定集合,具有固定大小的集合,当达到集合最大值的时候,会自动覆盖最早的文档,当该值为true时,必须指定集合的大小
autoIndexId:布尔值,会自动在_id字段创建索引,默认值为false
size:为固定集合指定一个最大值,单位为字节
max:指定固定集合中最大的文档数量
例如:在hero数据库中创建mycollection1与mycollection2
use hero
db.createCollection(
"myCollection1"
)
db.createCollection(
"myCollection2",{
capped: true,size: 65535,max: 1024
}
)
查看已经存在的集合
show collections

4.删除集合
删除集合语法格式
db.集合名字.drop()
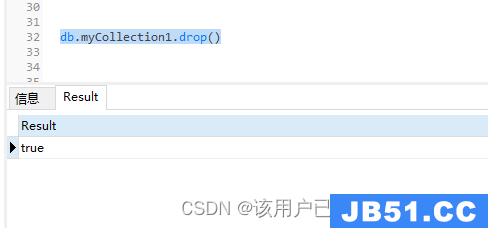
例如删除myCollection1
db.myCollection1.drop()
5.集合数据操作
查询数据基本语法
db.集合名字.insertOne(文档)
向users表中插入数据
db.users.insertOne(
{
name: "luccy",age: 19,status: "PP"
}
)
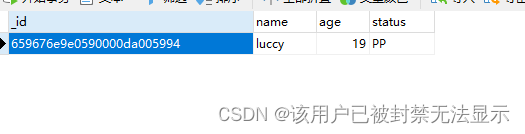
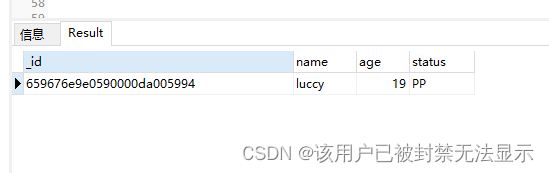
查询数据
db.users.find()
插入多条数据语法格式
db.集合名.insert([文档,文档])
例如:
db.users.insertMany(
[
{
name: "bool",age: 99,status: "AA"
},{
name: "yool",age: 98,{
name: "hoos",age: 66,status: "DD"
}
]
)
插入数据如下
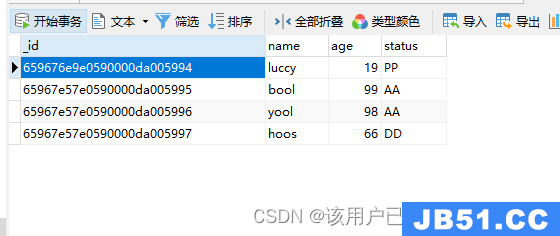
6.数据查询
比较条件查询语法
db.集合名.find(条件)
等于:{key:val}
大于:{key:$gt:val}
小于:{key:$lt:val}
大于等于:{key:$gte:val}
小于等于:{key:$lte:val}
不等于:{key:$ne:val}

分页条件查询语法
db.集合名.find({条件}).sort({排序字段:排序方式})).skip(跳过的行数).limit(一页显示多少
数据)
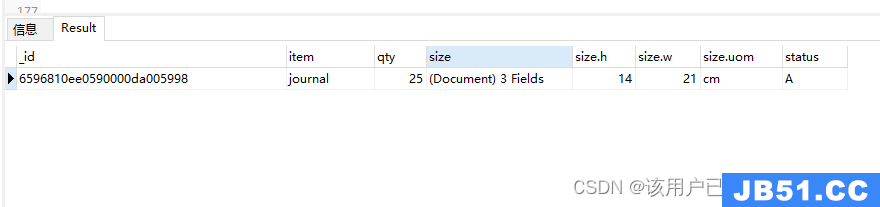
初始化数据
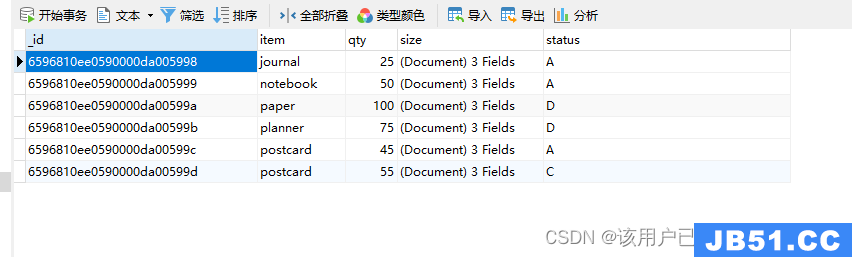
db.goods.insertMany([
{
item: "journal",qty: 25,size: {
h: 14,w: 21,uom: "cm"
},status: "A"
},{
item: "notebook",qty: 50,size: {
h: 8.5,w: 11,uom: "in"
},status:
"A"
},{
item: "paper",qty: 100,status: "D"
},{
item: "planner",qty: 75,size: {
h: 22.85,w: 30,status:
"D"
},{
item: "postcard",qty: 45,size: {
h: 10,w: 15.25,qty: 55,status:
"C"
}
]);
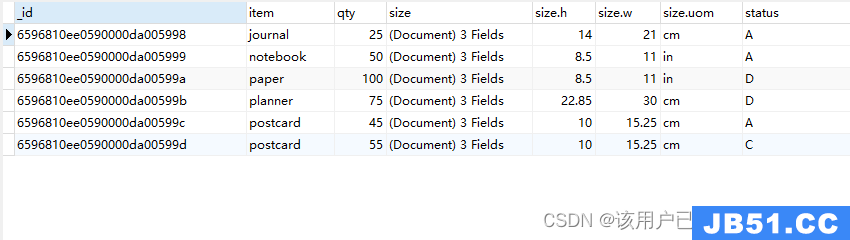
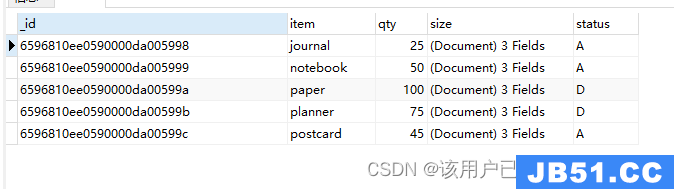
查询所有的数据
db.goods.find()
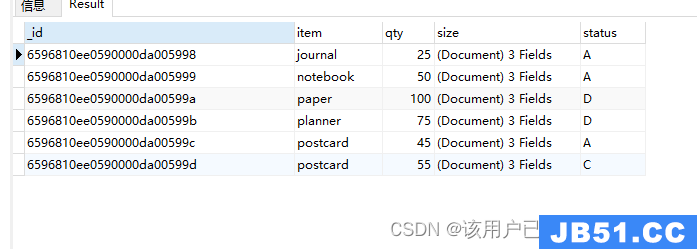
条件查询
db.goods.find(
{
status: "D"
}
)
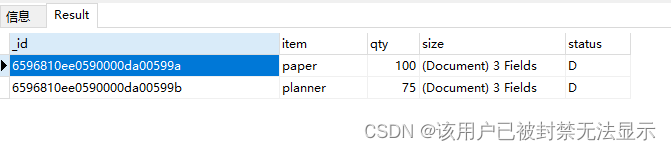
查询status带有A的,或者带有D的
db.goods.find(
{
status: {
$in: ["A","D"]
}
}
)
如果想查询status等于A,并且qty<30的
db.goods.find(
{
status: "A",qty: {
$lt: 30
}
}
)
查询status:A,或者qty<30的数据
db.goods.find(
{
$or: [{
status: "A"
},{
qty: {
$lt: 30
}
}]
}
)
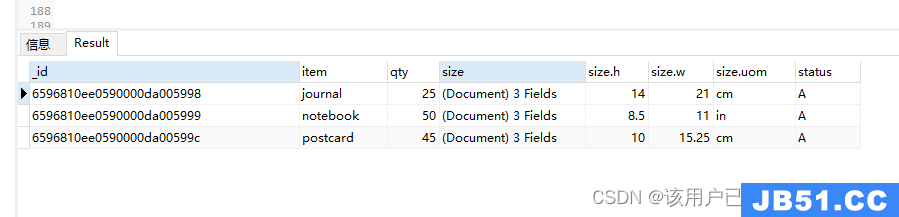
查询status:A,并且(qty<30 or item中是p开头的)
db.goods.find(
{
status: "A",$or: [{
qty: {
$lt: 30
}
},{
item: /^p/
}]
}
)
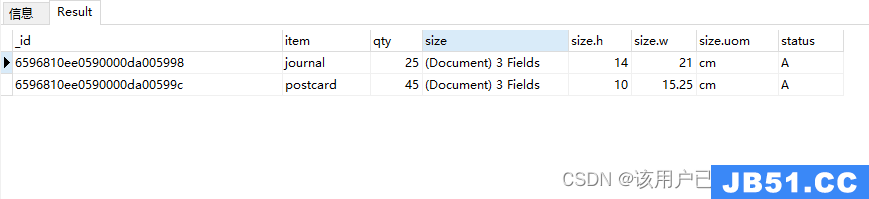
嵌套查询,查询size:{h:14,w:21,uom:“cm”}这条数据
db.goods.find(
{
size: {
h: 14,uom: "cm"
}
}
)

嵌套查询,含有标点符号的查询
db.goods.find(
{
"size.uom": "in"
}
)

7.数组查询
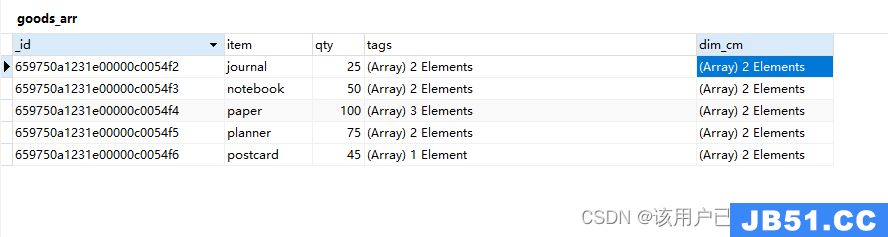
插入数据
db.goods_arr.insertMany([
{
item: "journal",tags: ["blank","red"],dim_cm: [14,21]
},tags: ["red","blank"],"blank","plain"],dim_cm: [22.85,30]
},tags: ["blue"],dim_cm: [10,15.25]
}
]);
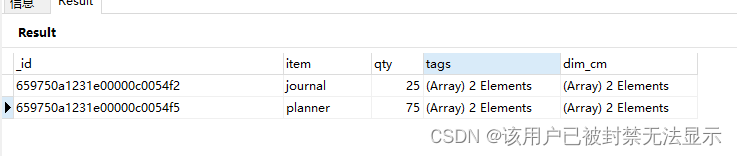
查询tags中包含两个元素blank,red的所有文档,顺序要一致
db.goods_arr.find(
{
tags: ["blank","red"]
}
)
查询tags中包含blank,red的元素,顺序可以不一致
db.goods_arr.find(
{
tags: {
$all: ["red","blank"]
}
}
)
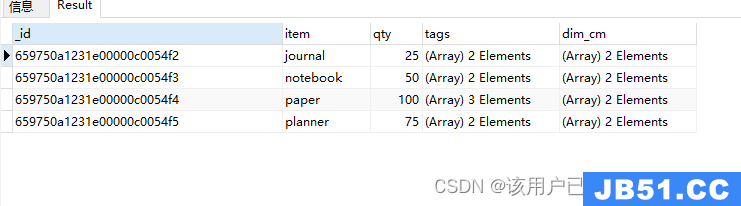
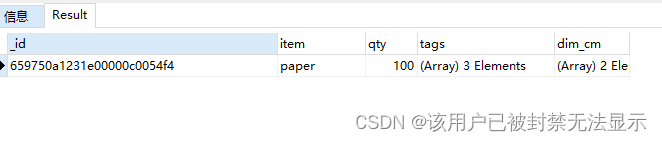
查询文档中dim_cm数组第二个参数大于25的文档
db.goods_arr.find(
{
"dim_cm.1": {
$gt: 25
}
}
)
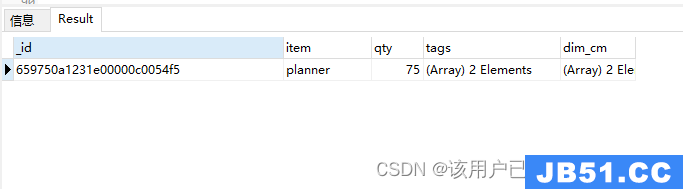
查询tags数组长度大于3的文档
db.goods_arr.find(
{
"tags": {
$size: 3
}
}
)
db.goods_null.insertMany([
{
_id: 1,item: null
},{
_id: 2
}
])
插入数据
db.goods_null.insertMany([
{
_id: 1,{
_id: 2
}
])
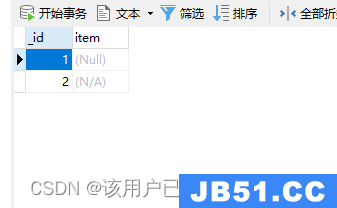
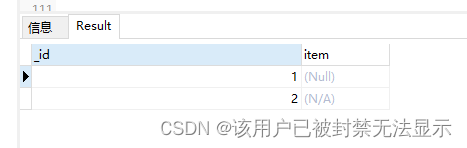
查询null或者丢失的字段
db.goods_null.find(
{
item: null
}
)
8.数据更新
数据更新语法
db.集合名.update(
< query >,< update >,{
upsert: < boolean >,multi: < boolean >,writeConcern: < document >
}
)



插入数据
db.users.insertMany(
[
{
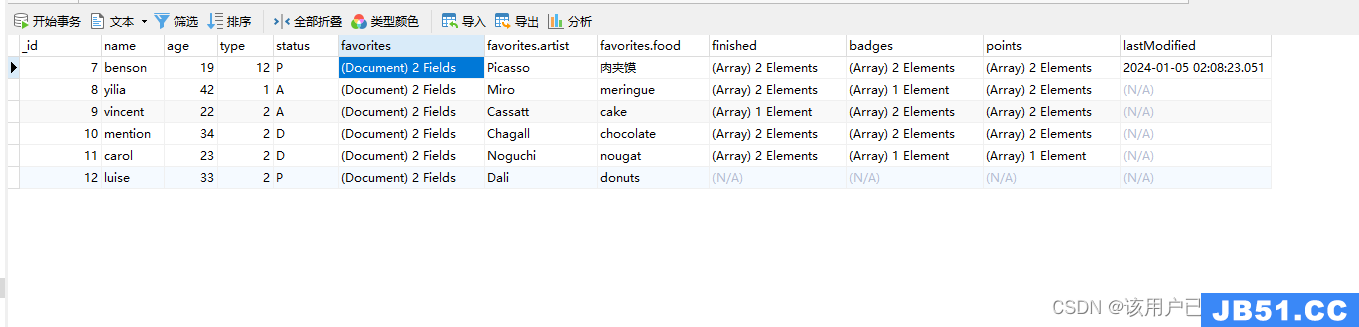
_id: 7,name: "benson",type: 1,status: "P",favorites: {
artist:
"Picasso",food: "pizza"
},finished: [17,3],badges: ["blue","black"],points: [{
points: 85,bonus: 20
},{
points: 85,bonus: 10
}]
},{
_id: 8,name: "yilia",age: 42,status: "A",favorites: {
artist:
"Miro",food: "meringue"
},finished: [11,25],badges: ["green"],{
points: 64,bonus: 12
}]
},{
_id: 9,name: "vincent",age: 22,type: 2,favorites: {
artist: "Cassatt",food: "cake"
},finished: [6],"Picasso"],points: [{
points: 81,bonus: 8
},{
points: 55,bonus: 20
}]
},{
_id: 10,name: "mention",age: 34,status: "D",favorites: {
artist: "Chagall",food: "chocolate"
},finished: [5,11],badges: [
"Picasso","black"
],points: [{
points: 53,bonus: 15
},{
points: 51,bonus:
15
}]
},{
_id: 11,name: "carol",age: 23,favorites: {
artist:
"Noguchi",food: "nougat"
},finished: [14,6],badges: ["orange"],points:
[{
points: 71,{
_id: 12,name: "della",age: 43,favorites: {
food:
"pizza",artist: "Picasso"
},finished: [18,12],badges: ["black","blue"],points: [{
points: 78,{
points: 57,bonus: 7
}]
}
]
)
案例:
下面的例子对 users 集合使用 db.users .update() 方法来更新过滤条件 favorites.artist 等于
“Picasso” 匹配的第一个 文档。
更新操作:
使用 $set 操作符把 favorites.food 字段值更新为 “ramen” 并把 type 字段的值更新为 0。
使用 $currentDate 操作符更新 lastModified 字段的值到当前日期。
如果 lastModified 字段不存在, $currentDate 会创建该字段;
db.users.find(
{
"favorites.artist": "Picasso"
}
)

db.users.update(
{
"favorites.artist": "Picasso"
},{
$set: {
"favorites.food": "famen",type: 0
},$currentDate: {
lastModified: true
}
}
)

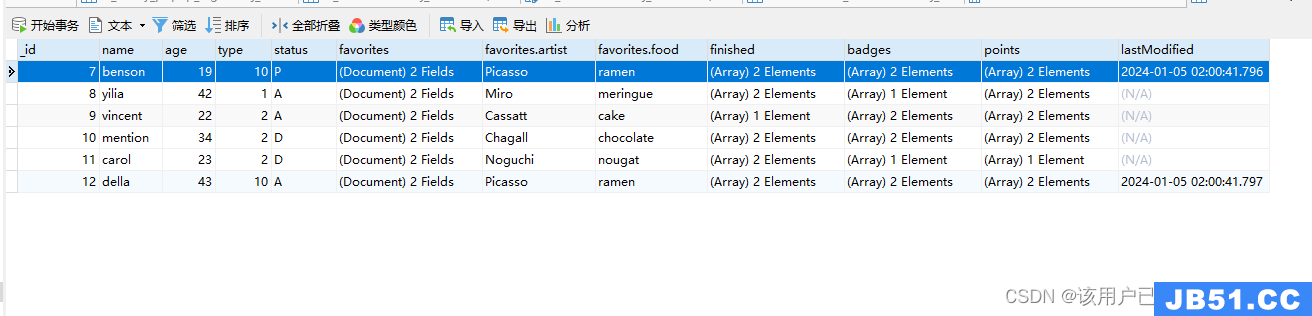
更新多个文档
db.users.update(
{
"favorites.artist": "Picasso"
},{
$set: {
"favorites.food": "ramen",type:10
},$currentDate: {
lastModified: true
}
},{
multi: true
}
)
更新单个文档
使用 $set 操作符更新 favorites.food 字段的值为 “Chongqing small noodles” 并更新 type 字段的
值为 3,
db.users.updateOne(
{
"favorites.artist": "Picasso"
},{
$set: {
"favorites.food": "狼牙土豆",type: 30
},$currentDate: {
lastModified: true
}
}
)

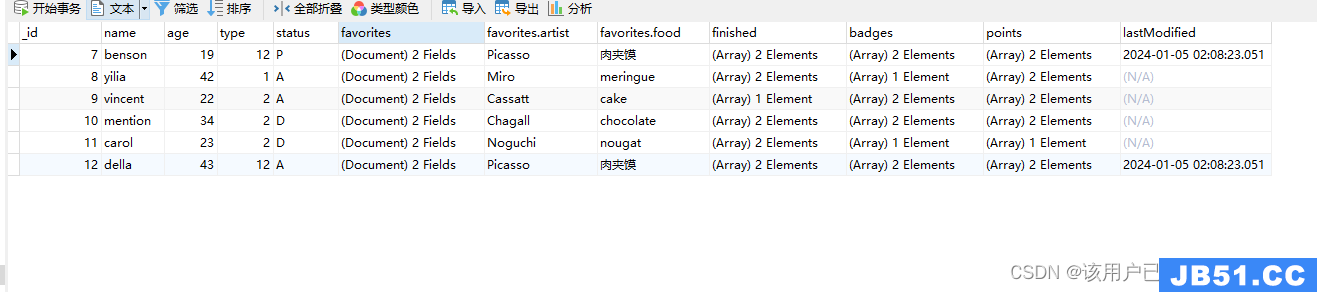
更新多个文档
db.users.updateMany(
{
"favorites.artist": "Picasso"
},{
$set: {
"favorites.food": "肉夹馍",type: 12
},$currentDate: {
lastModified: true
}
}
)
替换文档,_id是不可变的,如果包含_id,需要与原来的_id一样
db.users.find(
{
"name": "della"
}
)

db.users.replaceOne(
{
name: "della"
},{
name: "luise",age: 33,favorites: {
"artist": "Dali",food: "donuts"
}
}
)
9.数据删除
db.collection.remove(
< query >,{
justOne: < boolean >,writeConcern: < document >
}
)

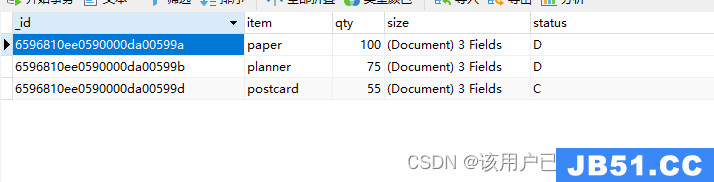
根据条件删除数据
db.goods.remove(
{
status: 'A'
}
)
删除所有数据
db.goods.remove({})
删除一条数据
db.goods.deleteOne({status:"A"})
删除多条数据
db.goods.deleteMany({status:"A"})
10.聚合操作
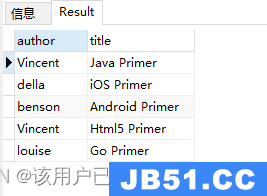
添加数据
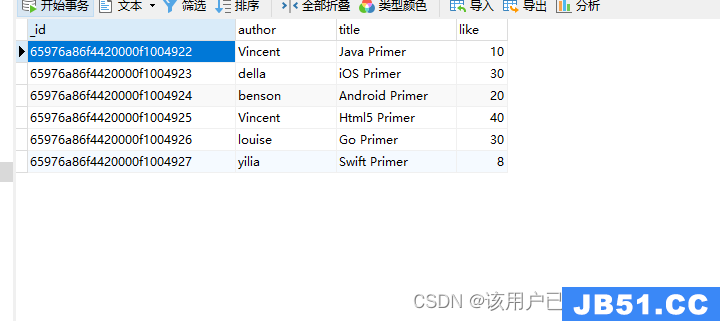
db.authors.insertMany([
{
"author": "Vincent","title": "Java Primer","like": 10
},{
"author": "della","title": "iOS Primer","like": 30
},{
"author": "benson","title": "Android Primer","like": 20
},{
"author": "Vincent","title": "Html5 Primer","like": 40
},{
"author": "louise","title": "Go Primer",{
"author": "yilia","title": "Swift Primer","like": 8
}
])
求数量
db.authors.count()
db.authors.count(
{
"author": "Vincent"
}
)

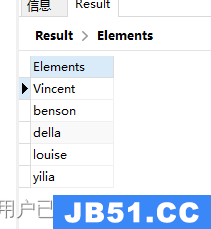
查询字段去重
db.authors.distinct(
"author"
)
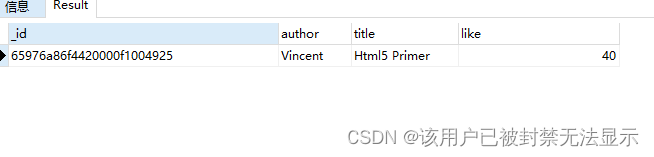
管道操作

找出like大于10的
db.authors.aggregate(
{
"$match": {
"like": {
"$gt": 30
}
}
}
)
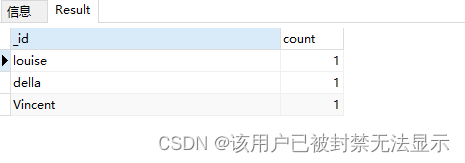
分组,按照id分组
db.authors.aggregate(
{
"$match": {
"like": {
"$gte": 25
}
}
},{
"$group": {
"_id": "$author","count": {
"$sum": 1
}
}
}
)
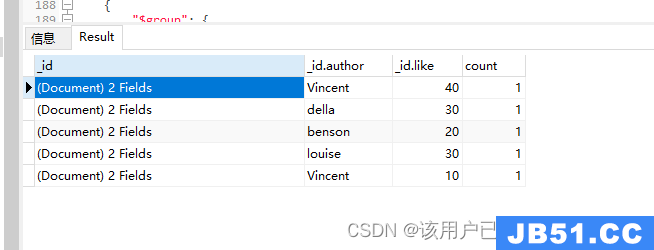
多个字段分组
db.authors.aggregate(
{
"$match": {
"like": {
"$gte": 10
}
}
},{
"$group": {
"_id": {
"author": "$author","like": "$like"
},"count":
{
"$sum": 1
}
}
}
)
分组求最大值
db.authors.aggregate(
{
"$group": {
"_id": "$author","count": {
"$max": "$like"
}
}
}
)

分组求平均值
db.authors.aggregate(
{
"$group": {
"_id": "$author","count": {
"$avg": "$like"
}
}
}
)
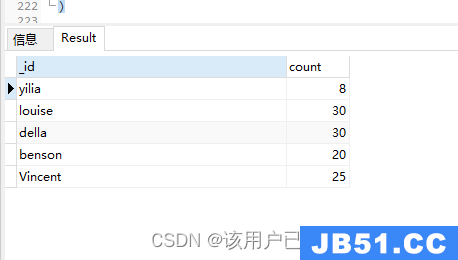
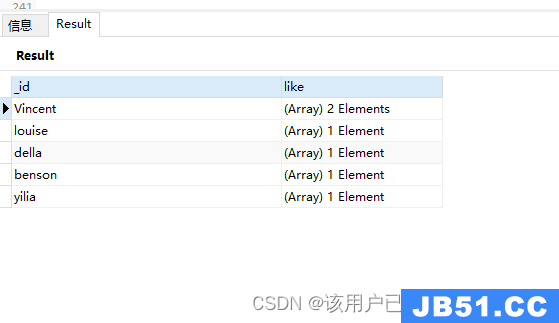
分组后放在set集合,不重复,无序
db.authors.aggregate(
{
"$group": {
"_id": "$author","like": {
"$addToSet": "$like"
}
}
}
)
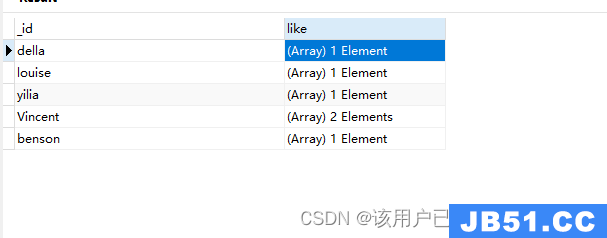
分组后放在set集合,有序
db.authors.aggregate(
{
"$group": {
"_id": "$author","like": {
"$push": "$like"
}
}
}
)
$project:投射案例
作用:用来排除字段,也可以对现有的字段进行重命名
字段名:0 就是不显示这个字段
字段名:1 就是显示这个字段
db.authors.aggregate(
{
"$match": {
"like": {
"$gte": 10
}
}
},{
"$project": {
"_id": 0,"author": 1,"title": 1
}
}
)
db.authors.aggregate(
{
"$match": {
"like": {
"$gte": 10
}
}
},"B_Name": "$title"
}
}
)

$sort:排序案例
用于对上一次处理的结果进行排序,1:升续 -1:降续
db.authors.aggregate(
{
"$match": {
"like": {
"$gte": 10
}
}
},"count": {
"$sum": 1
}
}
},{
"$sort": {
"count": - 1
}
}
)

$limit: 限制条数案例
db.authors.aggregate(
{
"$match": {
"like": {
"$gte": 10
}
}
},{
"$sort": {
"count": - 1
}
},{
"$limit": 1
}
)
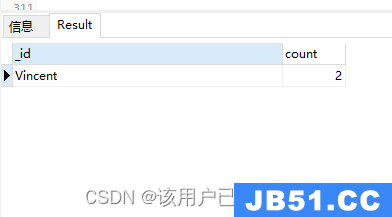
11.算术表达式案例
对like字段值进行+1操作
db.authors.aggregate(
{
"$project": {
"newLike": {
"$add": ["$like",1]
}
}
}
)
对like字段值减2操作
db.authors.aggregate(
{
"$project": {
"newLike": {
"$subtract": ["$like",2]
}
}
}
)

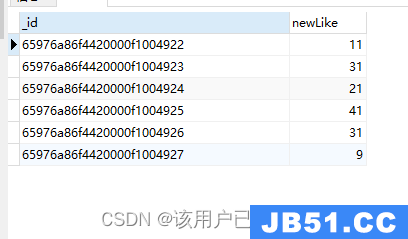
$multiply
对数组中的多个元素相乘
db.authors.aggregate(
{
"$project": {
"newLike": {
"$multiply": ["$like",10]
}
}
}
)
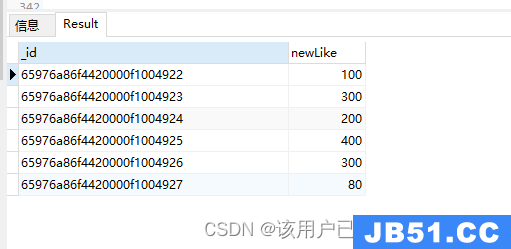
$divide
数组中的第一个元素除以第二个元素
db.authors.aggregate(
{
"$project": {
"newLike": {
"$divide": ["$like",10]
}
}
}
)
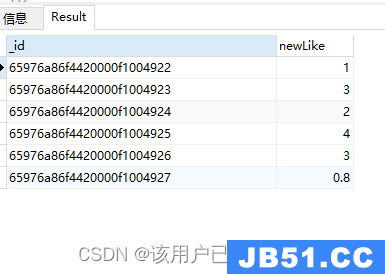
$mod
求数组中第一个元素除以第二个元素的余数
db.authors.aggregate(
{
"$project": {
"newLike": {
"$mod": ["$like",3]
}
}
}
)
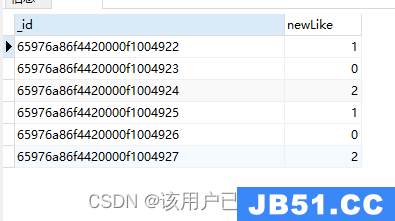
$substr
字符串截取操作
db.authors.aggregate(
{
"$project": {
"newTitle": {
"$substr": ["$title",1,2]
}
}
}
)
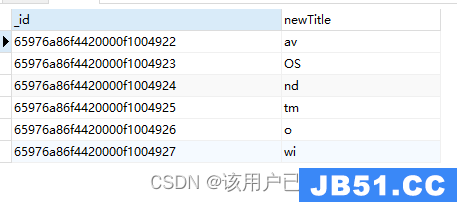
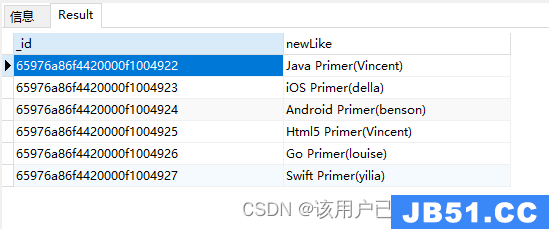
$concat
字符串操作:将数组中的多个元素拼接在一起
db.authors.aggregate(
{
"$project": {
"newLike": {
"$concat": ["$title","(","$author",")"]
}
}
}
)
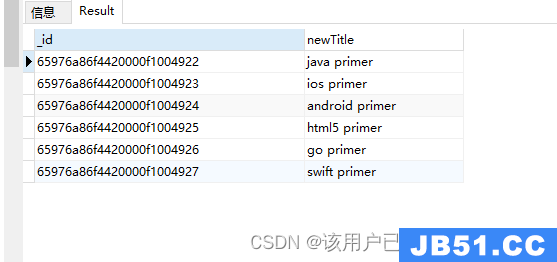
$toLower
字符串转小写
db.authors.aggregate(
{
"$project": {
"newTitle": {
"$toLower": "$title"
}
}
}
)
$toUpper
字符串操作,转大写
db.authors.aggregate(
{
"$project": {
"newAuthor": {
"$toUpper": "$author"
}
}
}
)
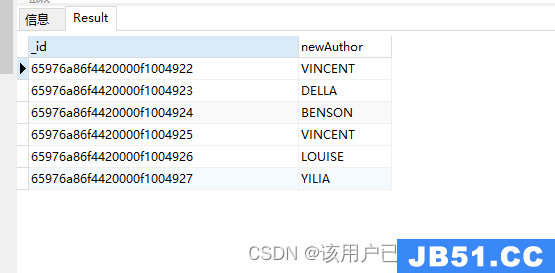
新增字段
db.authors.update(
{},{
"$set": {
"publishDate": new Date()
}
},true,true
)
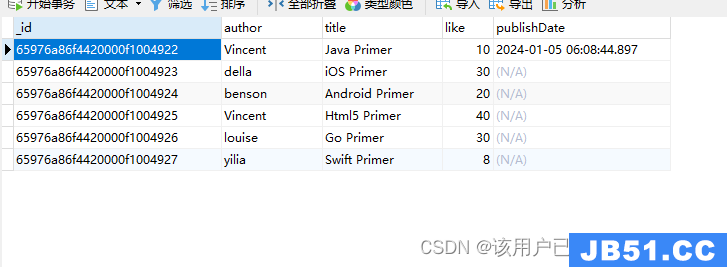
查询月份
db.authors.aggregate(
{
"$project": {
"month": {
"$month": "$publishDate"
}
}
}
)
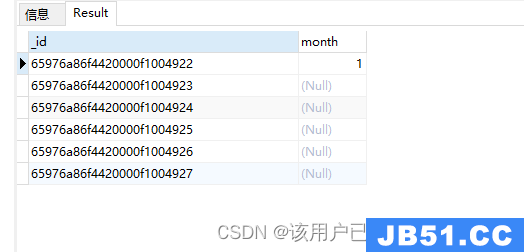
$cmp比较
$cmp: [exp1,exp2]:
等于返回 0
小于返回一个负数
大于返回一个正数
db.authors.aggregate(
{
"$project": {
"result": {
"$cmp": ["$like",20]
}
}
}
)
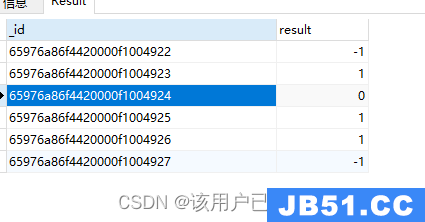
db.authors.aggregate(
{
"$project": {
"result": {
"$eq": ["$author","Vincent"]
}
}
}
)
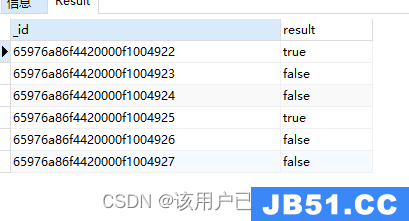
$and且
$and:[exp1,exp2,…,expN]
用于连接多个条件,一假and假,全真and为真
db.authors.aggregate(
{
"$project": {
"result": {
"$and": [{
"$eq": ["$author","Vincent"]
},{
"$gt": ["$like",20]
}]
}
}
}
)
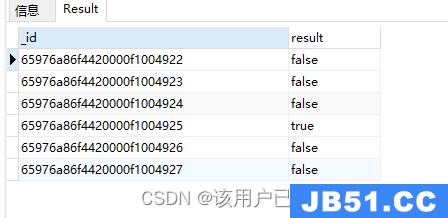
$or或
$or: [exp1,expN]
用于连接多个条件,一真or真,全假and为假
db.authors.aggregate(
{
"$project": {
"result": {
"$or": [{
"$eq": ["$author",20]
}]
}
}
}
)
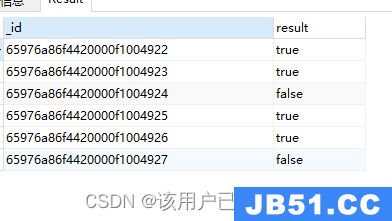
$not取反
$not: exp
用于取反操作
db.authors.aggregate(
{
"$project": {
"result": {
"$not": {
"$eq": ["$author","Vincent"]
}
}
}
}
)
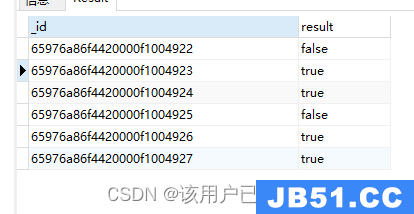
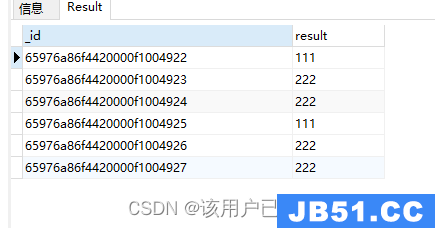
$cond三元运算符
$cond: [booleanExp,trueExp,falseExp]
db.authors.aggregate(
{
"$project": {
"result": {
"$cond": [{
"$eq": ["$author","111","222"]
}
}
}
)
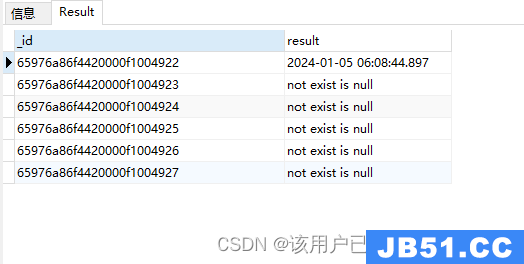
$ifNull非空
$ifNull: [expr,replacementExpr]
如果条件的值为null,则返回后面表达式的值,当字段不存在时字段的值也是null
db.authors.aggregate(
{"$project": {
"result": {"$ifNull": ["$publishDate","not exist is null"]}}
}
)
原文地址:https://blog.csdn.net/weixin_45810161/article/details/135390562
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。