

本博文为概览性介绍。后面有空了再分几篇博文分别介绍所用到的技术细节。
1.编解码目标
编码和解码是个逆过程。jpeg编码的目的在于图形去冗余,进行数据压缩,解码的目的在于还原图像,使能够进行预览。
2.编码过程
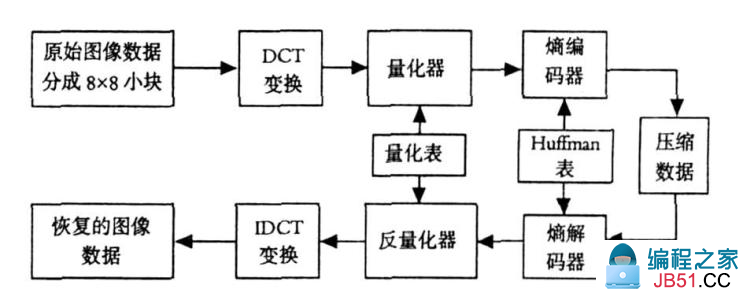
贴一张网上复制来的图片,该图虽然缺少了一些步骤,但能大体描述主要步骤。下面用文字来描述编码时必须进行的每一个步骤,按照先后顺序来介绍。
2.1.采样。
8位采样,像素值的范围锁定在0-255,无符号,都为正数。
2.2.分块(block)
将整幅图形分成8x8的像素块,对于宽和高不是8的整数倍的,right侧和bottom侧补充一些像素使成为8x8的block,方便后续进行8x8的DCT2变换。
2.3.零偏置(LevelOffset)
通过减28-1=128,使各个像素值以0为中心分布(如果像素统计以128为中心的高斯分布的话)。变换前为unsigned char类型,变换后为signed char类型。变换后的值有正有负,在[-128,127]区间分布。零偏置的主要目的为了减小下一步的DCT2的系数矩阵值。
2.4.8x8的二维离散余弦变换(DCT2)。
DCT变换是最小均方误差条件下的得出的最佳正交变换,将8x8的像素矩阵变成8x8的系数矩阵。DCT变换可以去相关性,将时域数据变换到频域,将能量集中于低频分量附近。
变换过程可以看到:变换前的8x8个数据值,大小都很接近;变换后,能量集中于左上角,右下角的较小。对于绝大多数图像而言,高频分量比较小,因为其代表着边缘处细节部分,左上角——直流分量值的绝对值一般变成了最大的值。
2.5.量化(quantization)。
将较大的值按一定的倍数(量化表,或称量化矩阵,一般有两张表,一个表为Y分量的,另外一个为UV分量公用的表)进行缩小,而这个缩小倍数(称之为量化步长,或量化值)视位置不同而不同(左上角值较小用于细量化低频部分,右下角较大用于粗量化高频部分,可以理解为低通滤波器)。补充说明:该步骤可以与下一步颠倒。如果先量化再扫描,可以看到:在量化后,后下角的值大部分都变成接近0的较小的值,而左上角的值由于量化值较小,通常较大。
2.6.z字形编码(zigzag scan)。
由二维系数矩阵变成一维。由于矩阵数据在内存中是按行来存储的,而DCT2后得到的系数矩阵,在相邻处的值比较接近(某行的行尾的值与下一行行首的值往往相差较大),通过zigzag扫描后,相邻的值通常比较接近,低频数据排在前面,高频数据排在后面,而后面数据几乎全部变成了0,在编码时可以用特殊的标记表示这之后的数据全是0,从而减少数据量。
2.7.差分脉冲编码(DPCM)对直流系数(DC)进行编码。
相同component分量的每个block的直流分量值,设置为一个差值:cur_block_dc_val - last_block_dc_val,DPCM也由此而来,即DC值的差分。
2.8.行程编码(RLE,或称游程编码)对交流系数(AC)进行编码。
8x8的数据块,除了第一个DC值外,其他63个都是交流值,需要用到RLE编码。
RLE也称为游程编码,由一对值来表示,例如(m,n),m表示距离下一个非零值的距离,n表示下个值的值大小。例如(0,12)表示紧接着的值是12,而(4,6)表示中间经过4个0后,下个值为6。
2.9.熵编码(entropy encode)。
一般使用范式霍夫曼编码(huffman_encode——可变长编码算法中的一种),高概率的字符分配较短的code来表示,低概率的字符分配较长的code来表示。
3.其他补充说明
1.有损和无损
采样和量化都是有损编码,而DCT变换、DPCM、RLE、HuffmanEncode为无损编码。
2.压缩率
通常通过调整量化表中的量化步长来控制压缩率。量化步长越大,压缩后的size越小,但信息损失越多,图片失真越严重。
3.采样因子
分为水平采样因子和垂直采样因子(共三组六个值,Y分量使用一种采样因子,UV分量采样因子一般相同),会记录在jpeg头部的SOF部分。通常采用两种格式的,YUV444或YUV420,前者YUV分量的水平和垂直采样因子都为1,而后者,Y分量水平和垂直采样因子都为2,U和V分量的采样因子为1。
采样因子含义为采样多少个点来表示一个像素值,例如,16x16分辨率的图像块,若采用YUV444的,则得到16x16的三个分量的像素块;若采用YUV420的,则得到16x16的Y分量的像素块,以及8x8的U和V像素块。
4.MCU(最小编码单元含义)和block(DCT2变换的最小单元)
采样有MCU的概念,其是编码(具体来说是DPCM和RLE)的基本单元。YUV444格式的一个MCU(大小为8x8)包含三个block(block——DCT2变换的最小单元,8x8大小的矩阵,三个是指YUV的三个分量),而YUV420的一个MCU(大小为16x16)包含Y分量的四个block和UV分量的各一个block。除YUV444和YUV420的方形MCU外,还存在8x16和16x8的矩形MCU,但比较少见,二者Y分量的水平/垂直采样因子分别为:1/2、2/1,而U和V分量的水平和垂直采样因子都为1(其实,各种格式的UV分量h/v采样因子都为1)。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
