

前言
先解释一下什么是类加载器,通过一个类的全限定名来获取描述该类的二进制字节流,在虚拟机中实现这个动作的代码被称为“类加载器(Class Loader)”。
类与类加载器
类加载器虽然只用于实现类的加载动作,但它在Java程序中起到的作用却远超类加载阶段。每个类加载器都有一个独立的类名称空间,所以每个类唯一性都必须是建立在是否为同一个类加载器的前提下的。
否则,即使是两个类来源于同一个Class文件,被同一个Java虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
例如:
public class ClassLoaderOneTest {
public static void main(String[] args) throws Exception{
ClassLoader oneLoader = new ClassLoader() {
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
try {
String classFileName = name.substring(name.lastIndexOf(".")+1)+".class";
InputStream inputStream = getClass().getResourceAsstream(classFileName);
if(inputStream == null){
return super.loadClass(name);
}
byte[] bytes = new byte[inputStream.available()];
inputStream.read(bytes);
return defineClass(name,bytes,0,bytes.length);
}catch (IOException e){
throw new ClassNotFoundException(name);
}
}
};
Object object = oneLoader.loadClass("com.eurekaclient2.test.jvm3.sonClass").newInstance();
System.out.println(object.getClass());
System.out.println("instanceof result :"+ (object instanceof com.eurekaclient2.test.jvm3.sonClass));
}
}
运行结果:
class com.eurekaclient2.test.jvm3.sonClass
instanceof result :false
通过上面的运行结果可以看出,自定义的类加载器加载出来的类创建的对象和com.eurekaclient2.test.jvm3.sonClass在做类型检查时返回了false,这是因为在Java虚拟机中存在的两个SonClass,一个是由虚拟机的应用程序类加载器所加载的,另一个是由自定义的类加载器加载的,虽然来自同一个Class文件,但在Java虚拟机中是两个互相独立的类。
双亲委派模型
Java虚拟机把类加载器分为了两大类:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器是虚拟机的一部分。另外一种就是其他类加载器(全部继承自java.lang.classLoader)。
从JDK1.2开始至JDK9之前的Java应用绝大多数都会使用到如下3个系统提供的类加载器进行加载。
- 启动类加载器(Bootstrap Class Loader):这个类加载器复制加载存放在
<JAVA_HOME>\lib目录,或者被-Xbootclasspath参数所指定的路径中存放的,而且是Java虚拟机能够识别的类库加载到虚拟机的内存中。
如果需要使用引导类加载器去加载类,直接使用null代替即可。
如下是ClassLoader.getClassLoader()方法的源码:
/**
* Returns the class loader for the class. Some implementations may use
* null to represent the bootstrap class loader. This method will return
* null in such implementations if this class was loaded by the bootstrap
* class loader.
* /
@CallerSensitive
public ClassLoader getClassLoader() {
ClassLoader cl = getClassLoader0();
if (cl == null)
return null;
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
ClassLoader.checkClassLoaderPermission(cl, Reflection.getCallerClass());
}
return cl;
}
- 扩展类加载器(Extension Class Loader):这个类加载器是在类sun.misc.launcher$ExtClassLoader中以Java代码的形式实现的。它负责加载
<JAVA_HOME>\lib\ext目录中,或者被java.ext.dirs系统变量所指定的路径中所有的类库。这是Java系统类库的扩展机制,但是在JDK9之后,被模块化能力所替代了。 - 应用程序类加载器(Application Class Loader):这个类加载器由
sun.misc.Launcher$AppClassLoader来实现的。它负责加载用户类路径(Classpath)上所有的类库,开发者同样可以直接在代码中使用这个类加载器。如没有自定义的类加载器,这个就是默认的类加载器。
在JDK9之前的Java应用都是由这三类加载器互相配合来完成加载的,如果有自定义的类加载器,会先执行自定义的类加载器。各种的类加载器之间的层次关系被称为类加载器的“双亲委派模型(Parents Delegation Model)”。
各种类加载器的关系如下图:
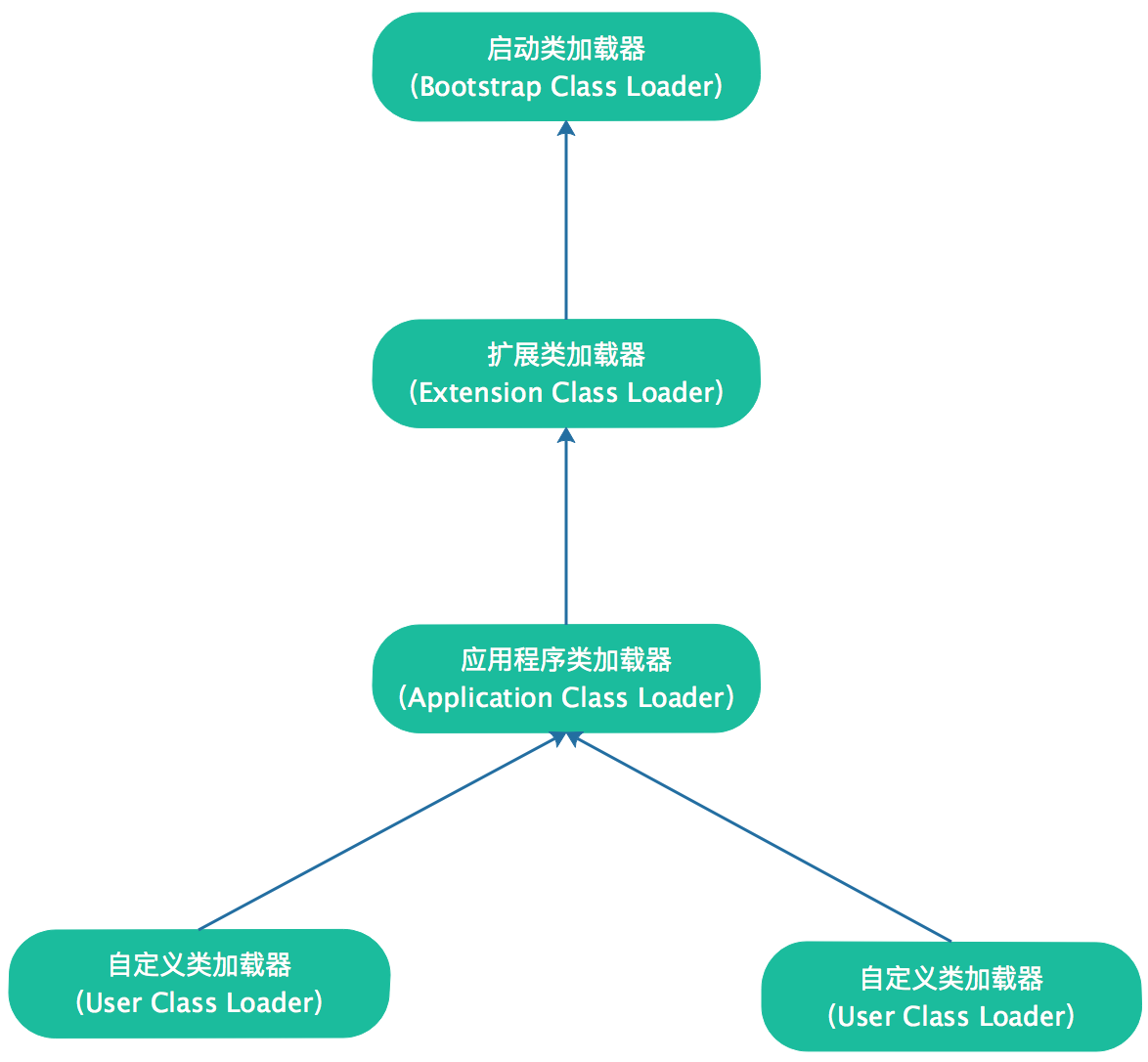
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。
这里的加载器之间的子父关系不是继承,通常使用组合关系来复用父加载器的代码。
双亲委派模型并不是一个强制性约束力的模型而是Java设计者推荐给开发者的一种类加载器实现的最佳实践。
双亲委派模型的工作过程
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶端的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载才会尝试自己去完成加载。
使用双亲委派模型来组织类加载器之间的关系的好处就是能保证java类型体系中最基础的类的唯一。
例如:类java.lang.Object无论哪一个类加载器加载最终都会委派给启动类加载器,因此能够保证各种类加载器环境中的都是同一个类。这样就能保证我们创建出来的类的拥有最基础的行为。
记得以前在面试的时候有被问到,让自己写一个java.lang.String类然后会被虚拟机加载运行吗?这个问题考察的就是类的加载机制的双亲委派模型。
双亲委派模型的源码其实非常简洁,先检查请求加载的类型是否已经被加载过,若没有则调用父加载器的loadeClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。假如父加载器加载失败,抛出ClassNotFoundException异常,才会调用自己的findClass方法尝试进行加载。
源码如下:
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先,检查请求的类是否已经被加载过了
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 如果父类加载器抛出ClassNotFoundException
// 说明父类加载器无法完成加载请求
}
if (c == null) {
// 在父类加载器无法加载时
// 在调用本身的findClass方法来进行类加载
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClasstime().addelapsedtimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
破坏双亲委派模型
上面也提到了,双亲委派模型并不是一个具体强制性约束的模型,虽然在Java的世界大部分的类加载器都遵循这个模型,但也有例外的情况,直到JDK9(模块化)为止,主要出现过3次较大规模“被破坏”的情况。
- 第一次“被破坏”其实发生在双亲委派模型出现之前,由于双亲委派模型在JDK1.2之后才被引入,但是类加载器的概念和抽象类
java.lang.classLoader则在Java的第一个版本中就已经存在了。为了向前兼容,只能在JDK1.2之后的java.lang.classLoader中添加一个新的protected方法findClass(),并引导用户编写类的加载逻辑时尽可能去重写这个方法,而不是在loadClass()中编写代码。 - 第二次“被破坏”是因为自身的一些局限性导致的,双亲委派模型很好的解决了各个类加载器协作时基础类型的一致性问题,即越基础的类由越上层的加载器进行加载。
但是如果基础的类需要调用下面的用户代码时该怎么办呢?Java设计团队用了一个不太优雅的方案,引入了一个名叫线程上下文的类加载器(Thread Context ClassLodar)。这个类加载器可以通过java.lang.Thread类的setContextClassLoader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。
像JNDI、JDBC、JCE、JAXB、JBI等都是用的这种类型加载器实现的功能。最常见的tomcat中就用到了线程上下文的类加载器。 - 第三次“破坏”,是为了实现热部署、模块化。在更新了一部分代码后,不需要停机重启,只需要将类加载器和类都替换掉就可以了。典型的就是Osgi的模块化热部署。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
