

目录
简介
之前的文章中,我们使用JOL工具简单的分析过String,数组和集合类的内存占用情况,这里再做一次更详细的分析和介绍,希望大家后面再遇到OOM问题的时候不再抱头痛哭,而是可以有章可循,开始吧。
数组
//byte array
log.info("{}",ClassLayout.parseInstance("www.flydean.com".getBytes()).toPrintable());
输出结果:
INFO com.flydean.CollectionSize - [B object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 22 13 07 00 (00100010 00010011 00000111 00000000) (463650)
12 4 (object header) 0f 00 00 00 (00001111 00000000 00000000 00000000) (15)
16 15 byte [B.<elements> N/A
31 1 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 0 bytes internal + 1 bytes external = 1 bytes total
注意,本文的结论都在64位的JVM中运行得出了,并且开启了COOPs压缩对象指针技术。
可以看到数组对象的对象头大小是16字节,再加上数组里面的内容长度是15字节,再加上1位补全。最后得到的大小是32字节。
同样的,我们计算存有100个对象的数组,可以得到下面的结论:
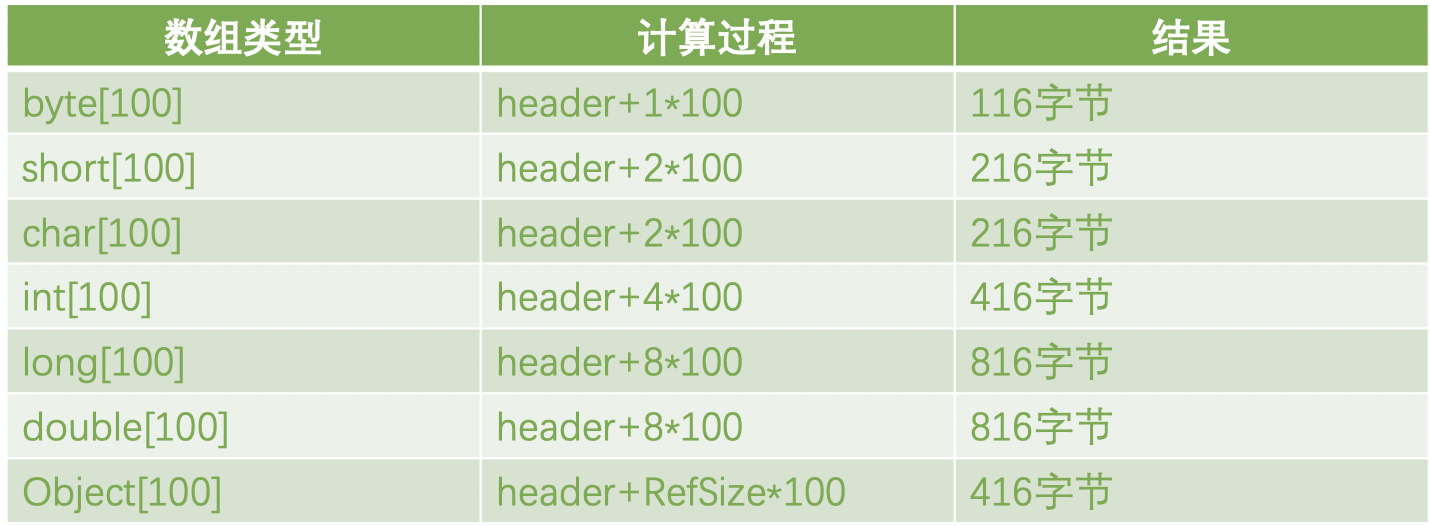
注意最后面的Object数组,如果数组中存储的不是基础类型,那么实际上存储的是执行该对象的指针,该指针大小是4个字节。
String
String是一个非常特殊的对象,它的底层是以byte数组存储的。
注意,在JDK9之前,String的底层存储结构是char[],一个char需要占用两个字节的存储单位。
因为大部分的String都是以Latin-1字符编码来表示的,只需要一个字节存储就够了,两个字节完全是浪费。
于是在JDK9之后,字符串的底层存储变成了byte[]。
同样的我们还是用JOL来分析:
//String
log.info("{}",ClassLayout.parseInstance("www.flydean.com").toPrintable());
输出结果:
INFO com.flydean.CollectionSize - java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 77 1a 06 00 (01110111 00011010 00000110 00000000) (399991)
12 4 byte[] String.value [119, 119, 119, 46, 102, 108, 121, 100, 101, 97, 110, 46, 99, 111, 109]
16 4 int String.hash 0
20 1 byte String.coder 0
21 1 boolean String.hashIsZero false
22 2 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 2 bytes external = 2 bytes total
可以看到String中的对象头是12字节,然后加上4字节的指针指向一个byte数组。再加上hash,coder,和hasIsZero属性,最后的大小是24字节。
我这里使用的是JDK14的String版本,不同的版本可能有所不同。
当然这只是这个String对象的大小,不包含底层数组的大小。

我们来计算一下String对象的真实大小:
String对象的大小+byte数组的大小=24+32=56字节。
ArrayList
我们构建一个非常简单的ArrayList:
//Array List
log.info("{}",ClassLayout.parseInstance(new ArrayList()).toPrintable());
输出结果:
INFO com.flydean.CollectionSize - java.util.ArrayList object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 87 81 05 00 (10000111 10000001 00000101 00000000) (360839)
12 4 int AbstractList.modCount 0
16 4 int ArrayList.size 0
20 4 java.lang.Object[] ArrayList.elementData []
Instance size: 24 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
画个图来直观的表示:
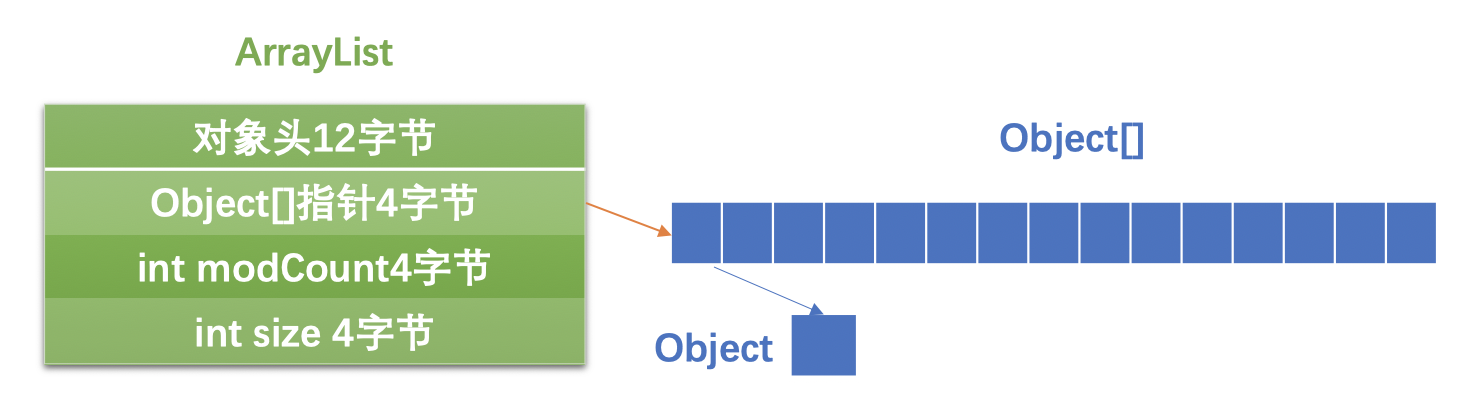
这里modCount和size的初始值都是0。
HashMap
因为文章篇幅的限制,这里就不把代码列出来了,我只贴个图上来:
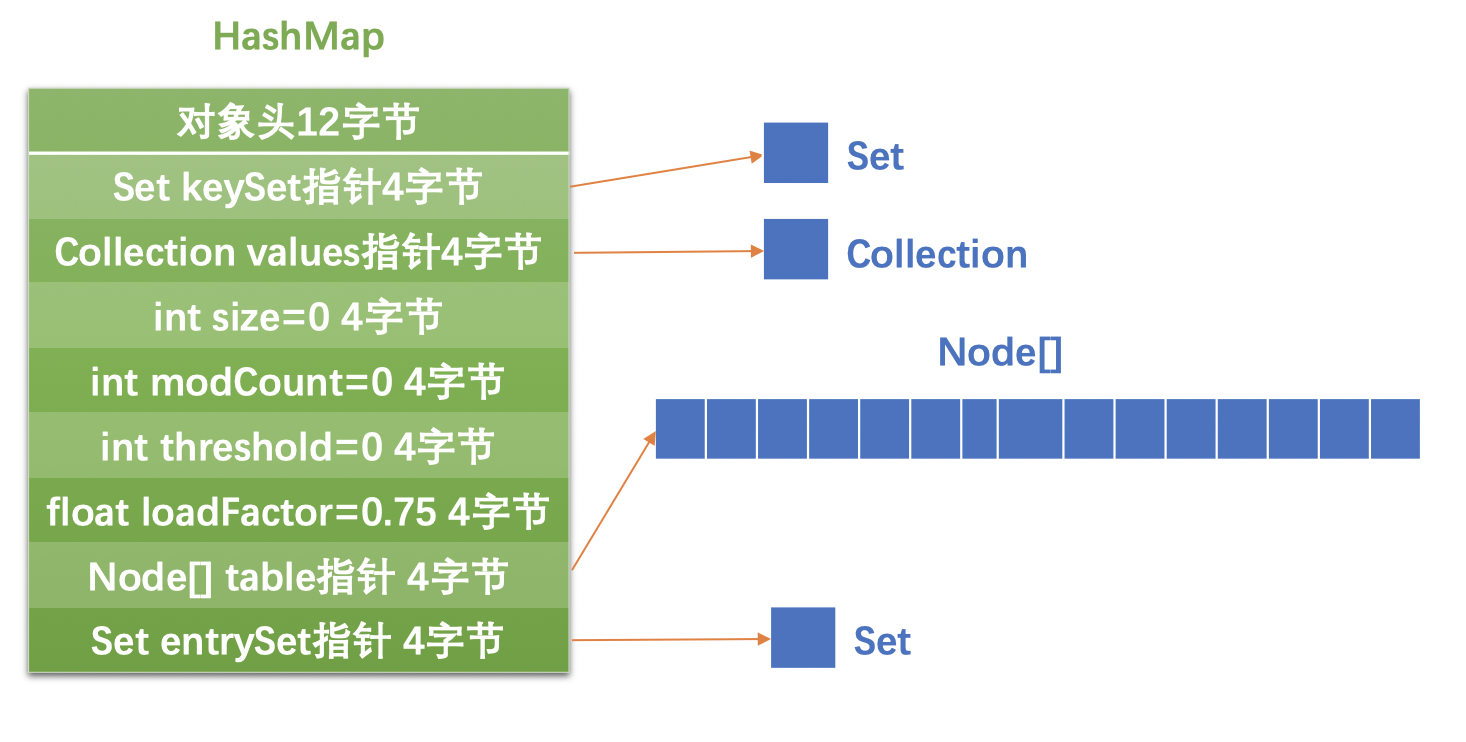
HashSet

LinkedList

treeMap
来个比较复杂的TreeMap:

总结
本文用图形的形式形象的展示了集合对象,数组和String在内存中的使用情况。
后面的几个集合我就没有一一计算,有兴趣的朋友可以在下方回复你计算的结果哟。
本文作者:flydean程序那些事
本文链接:http://www.flydean.com/jvm-collections-size/
本文来源:flydean的博客
欢迎关注我的公众号:程序那些事,更多精彩等着您!
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
