

目录:
- 类加载机制简介
- 类加载机制流程
类加载机制简介
类加载机制就是虚拟机把描述类的数据从Class文件中加载到内存中的一种机制,并且在加载的过程中会对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的java类型。
类加载机制流程
类从被加载到虚拟机的内存中开始,直到类被卸载出内存为止,它的整个生命周期主要分为包括:加载、验证、准备、初始化、使用、卸载7个阶段。
其中准备、验证、解析这三个部分统称为连接。

而类加载过程是加载、验证、准备、解析、初始化这五个阶段。
其中加载、验证、准备、初始化这四个阶段发生的顺序是确定的,而解析阶段则不一定,它在某些情况下可以在初始化阶段之后开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)
另外注意这里的几个阶段是按顺序开始,而不是按顺序进行或完成,因为这些阶段通常都是互相交叉地混合进行的,通常在一个阶段执行的过程中调用或激活另一个阶段。
加载:
加载时类加载过程的第一个阶段,此阶段虚拟机需要完成以下三件事情:
2、把字节流代表的静态存储结构(Class文件)转化为方法区运行时的数据结构。
什么意思呢,我们要知道字节码它只是定义了类的一些元数据,实际执行的时候还是需要通过JVM来加载类的元数据。
而类其实就是有大大小小的方法构成的(你会说不是还有属性嘛,是的有属性,但属性不也是为方法服务的嘛),方法区就是JVM加载到内存的那些类的元数据集。
这个又如何理解呢,首先方法的运行是一条条指令构成的,但这些指令都是需要内存加载后才能执行,这样才能正确得到后续指令的引用。
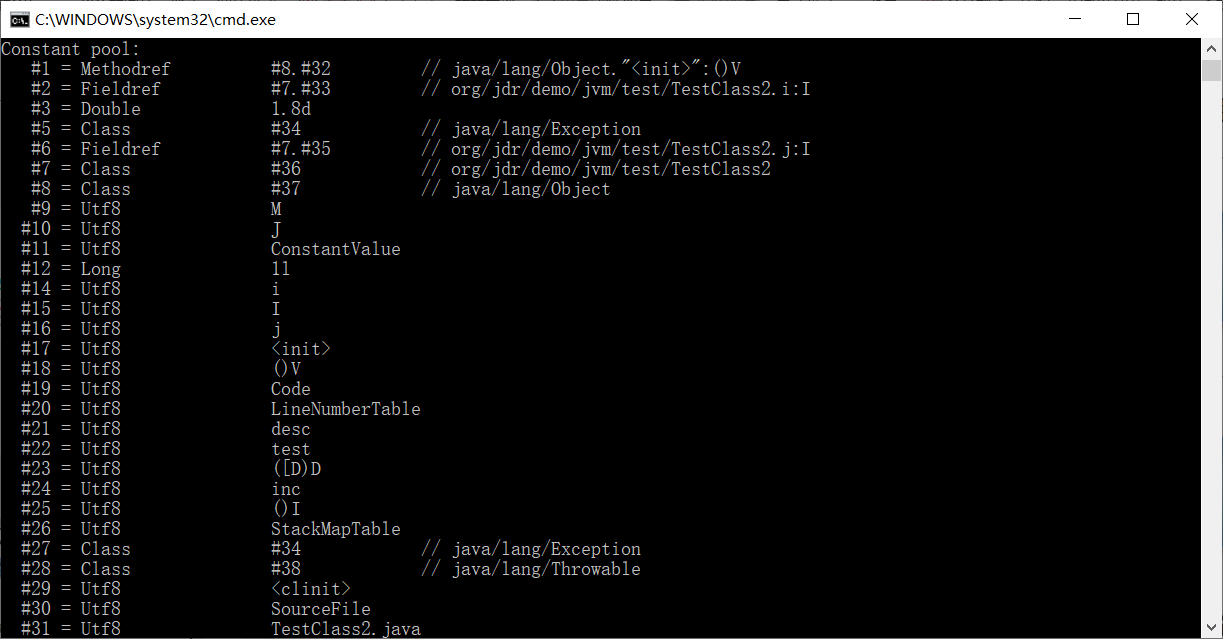
如常量池的引用,#1、#2、#3这些最后都需要换算成具体的内存地址。
验证:
验证是连接阶段的第一步,确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
验证阶段大致分下面4个动作:
- 文件格式验证:通过了这个阶段的验证后,字节流才会进入内存的方法区中进行存储。后面的验证会基于方法区的存储结构进行验证,而不再操作字节流进行验证。
- 元数据验证:该阶段主要对字节码描述的信息进行语义分析,以保证符合Java语言规范要求。
- 字节码验证:
- 符号引用验证:如常量池中的符号指向是否正确,符号引用验证的目的就是确保解析动作能正常执行。
在验证过程中大致会抛出如下几种错误:
- IncompatibleClassChangeError。
- Unsupported major.minor version。
- IllegalAccessError。
- NoSuchFieldError。
- NoSuchMethodError。
准备:
准备阶段是为类变量分配内存并设置类变量初始化的阶段,这些变量所使用的内存当将在方法区中进行分配。
只对类变量进行内存分配(static修饰),不包括实例变量,实例变量将会在对象实例化是随着对象一起分配在Java堆中。
如只会初始化如下变量:
1 public static int I = 1; 2 public static final int J = 2;
解析:
解析的目的就是将常量池内的符号引用替换为直接引用。
符号引用(Symbolic References):符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中。符号引用的字面量形式已经明确定义在Java虚拟机规范的Class文件格式中。
直接引用(Direct References):直接引用可以是直接指向目标的指针,相对偏移量或是一个能间接定位到目标的句柄。直接引用与虚拟机实现的内存布局相关,同一个符号引用在不用虚拟机实例上翻译出来的直接引用一般不同。如果有了直接引用,那引用的目标必定已经在内存中存在。
一句话总结:符号引用是以字面量的形式明确定义在常量池中;直接引用是指向目标的指针,或者相对偏移量。
解析动作主要对类或者接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行,分别对应于常量池:
- CONSTANT_Class_info。
- CONSTANT_Fieldref_info。
- CONSTANT_Methodref_info。
- CONSTANT_InterfaceMethodref_info。
- CONSTANT_MethodType_info。
- CONSTANT_Methodref_info。
- CONSTANT_MethodHandler_info。
- CONSTANT_invokeDynamic_info。
1、字段的解析:
1 class A extends B implements C, D {
2 private String str;
3 }
解析字段的顺序:A -> C, D -> B -> java.lang.NoSuchFieldError
- 先查找本类A,如果包含了简单名称和字段描述符都与目标相匹配的字段,则返回这个字段的直接引用,查找结束。
- 否则,在接口中查找。将会按照集成关系从下往上递归搜搜各个接口和它的父接口,如果接口中包含了简单名称和字段描述符都于目标相匹配的字段,则返回这个字段的直接引用,查找结束。
- 否则,在父类中查找,如果在父类中包含了简单名称和字段描述符都于目标相匹配的字段,则返回这个字段的直接引用,查找结束
- 否则,查找失败,抛出java.lang.NoSuchFieldError异常。
2、类方法的解析:
1 class A extends B implements C, D {
2 private void inc();
3 }
解析顺序:A -> B(父类递归) -> C, D(接口递归) -> java.lang.NoSuchMethodError
- 如果在类方法表中发现class_index中索引的A是一个接口,哪就直接抛出java.lang.IncompatiableClassChangeError异常。
- 如果通过了第一步,先查找本类A,是否由简单名称和描述符都于目标相匹配的方法,如果有则返回方法的直接引用,查找结束。
- 否则,父亲中递归查找是否又简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。
- 否则,在类实现的接口列表及它们的父接口之中查找是否有简单名名称和描述符都与目标相匹配的方法,如果存在匹配的方法,说明类C是一个抽象类,这时查找结束,抛出java.lang.AbastractMethodError异常。
- 否则,宣告方法查找失败,抛出java.lang.NoSuchMethodError。
3、接口方法的解析:
解析顺序:本接口 -> 父接口递归查找 -> java.lang.NoSuchMethodError ->
- 与类的方法解析不同,如果在接口方法表中发现class_index中的索引A是个类而不是接口,那就直接抛出java.lang.IncompatiableClassError异常。
- 否则,先查找本接口,是否有简单名称和描述符都与目标匹配的方法,如果有则返回这个方法的直接引用,查找结束。
- 否则,在接口的父接口中递归查找,直到java.lang.Object类(查找范围包括Object类)为止,看是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。
- 否则,宣告方法查找失败,抛出java.lang.NoSuchMethodError异常。
初始化:
1、<clinit>类的初始化:静态变量,静态块的初始化。所有的类变量初始化语句和类型的静态初始化器。Java在编译之后会在字节码文件中生成<clinit>方法,称之为类构造器,类构造器同实例构造器一样,也会对静态语句块,静态变量进行初始化。
2、<init>对象的初始化:Java在编译之后会在字节码文件中生成<init>方法,称之为实例构造器。该实例构造器会对语句块,变量进行初始化,并调用父类的构造器。
<clinit>方法是在类加载过程中执行的,而<init>是在对象实例化执行的,所以<clinit>一定比<init>先执行。所以整个顺序就是:
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
