

简介
字符数组的存储方式
字符串常量池
字符串在java程序中被大量使用,为了避免每次都创建相同的字符串对象及内存分配,JVM内部对字符串对象的创建做了一定的优化,在Permanent Generation中专门有一块区域用来存储字符串常量池(一组指针指向Heap中的String对象的内存地址)。
在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个HashTable,默认值大小长度是1009;这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。字符串常量由一个一个字符组成,放在了StringTable上。在JDK6.0中,StringTable的长度是固定的,长度就是1009,因此如果放入String Pool中的String非常多,就会造成hash冲突,导致链表过长,当调用String#intern()时会需要到链表上一个一个找,从而导致性能大幅度下降;
- 在JDK6.0及之前版本中,String Pool里放的都是字符串常量;
- 在JDK7.0中,由于String#intern()发生了改变,因此String Pool中也可以存放放于堆内的字符串对象的引用。关于String在内存中的存储和String#intern()方法的说明。
字符串Hashcode
不通方式创建字符串在JVM存储的形式
-
双引号方式
双引号引起来的字符串,首先从常量池中查找是否存在此字符串。如果不存在,则在常量池中添加此字符串。在堆中创建字符串对象,因String底层是通过char数组形式存储的,所以同时会在堆中生成一个TypeArrayOopDesc用来存储char数组对象。如果存在,则直接引用此字符串对象。

测试代码1:
public static void test1(){
String s1="11";
String s2="11";
System.out.println(s1==s2);
}
测试结果:

原因分析:
s1代码执行后,常量池中添加了“11”这个常量,在堆中也创建了String对象并引用此常量的。当s2代码执行时,先在常量池中查找是否存在“11”这个常量,发现常量池中存在这个值,就找到引用此常量的字符串对象,将s2的引用指向找到的字符串对象。因为s1和s2指向同一个地址,所以比较结果为true。

-
new String
1、首先从常量池中查找是否存在括号内的常量,如果不存在,则在常量池中添加此字符串。在堆中创建字符串对象,因String底层是通过char数组形式存储的,所以同时会在堆中生成一个TypeArrayOopDesc用来存储char数组对象。如果存在,则直接引用堆中存在的字符串对象。
2、通过new方式创建的String对象,每次都会在Heap上创建一个新的实例。并将此新实例中char数组对象,指向第一步堆中的已经存在的TypeArrayOopDesc。
测试代码:
public static void test2() {
String s1 = new String("11");
String s2 = new String("11");
System.out.println(s1 == s2);
}
测试结果:

原因分析:
通过new方式创建的String对象,每次都会在Heap上创建一个新的实例。所以s1和s2的分别指向了不同的实例,引用地址不同。

测试代码:
public static void test3() {
String s1 = new String("11");
String s2 = "11";
System.out.println(s1 == s2);
}
测试结果:
原因分析:
当执行s1时,首先会将括号内的字面量常量“11”添加到常量池中,并且在堆中生成字符串实例及char数组实例TypeArrayOopDesc。再通过new方式创建的String对象,会在Heap上新创建一个实例,此新实例中char数组不需要新的实例,指向堆中的已存在的TypeArrayOopDesc。
当执行s2时,在常量池中发现常量已存在,则直接将虚拟机栈的指向堆中代表此常量的字符串实例。
因此s1和s2的分别指向了不同的实例,引用地址不同。
【缺图】
字符串在JVM中是如何拼接的
测试代码:
public static void test4(){
String s2="1"+"1";
String s1="11";
System.out.println(s1==s2);
}
测试结果:

原因分析:
文件在编译期成字节码时,编译器将“1”+“1”变成了“11”,编译后,相当于s2="11"。就与上面的测试代码1相同了,具体原因见测试代码1的原因分析。
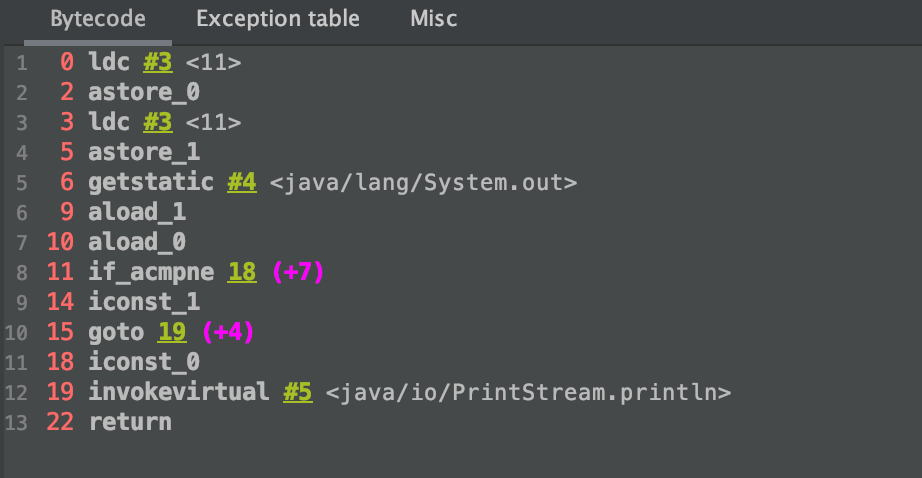
测试代码:
public static void test5(){
String s1="1";
String s2="1";
String s3=s1+s2;
String s4="11";
System.out.println(s3==s4);
}
测试结果:

原因分析:
编译器在编译时无法确定s3的值,是在运行时才能确定,保存在jvm的堆里面,在拼接的时候,先在常量池里面生成是s1、s2的字符串,在执行加号的时候,会从常量池中取出s1、s2常量,在堆中生成两个字符串对象,然后再生成第三个字符串对象来保存两个对象拼接后的值。
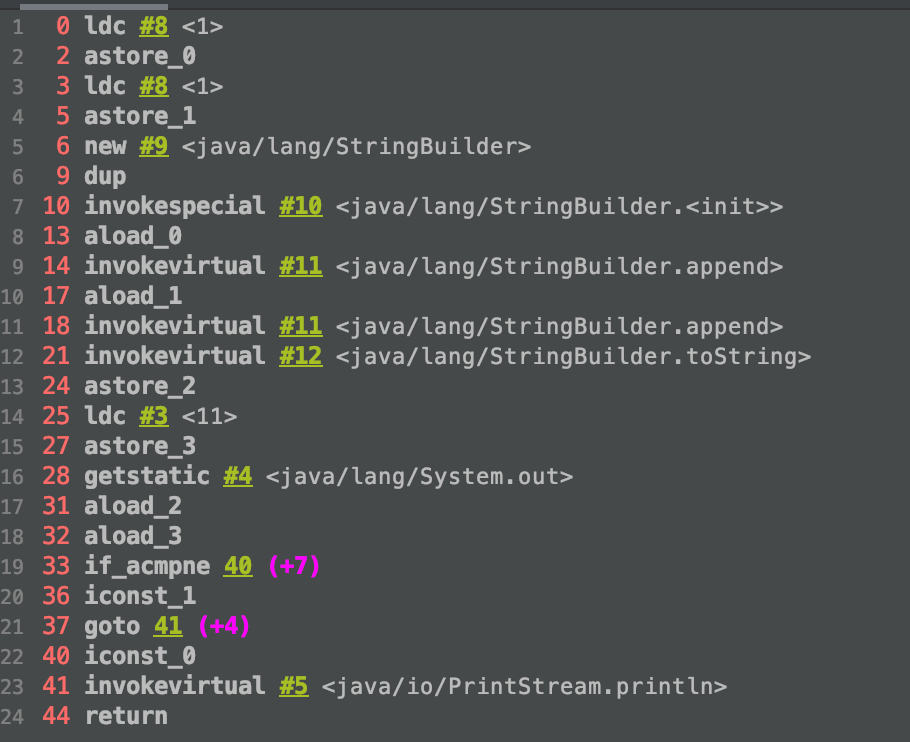
测试代码:
public static void test6() {
final String s1 = "1";
final String s2 = "1";
String s3 = s1 + s2;
String s4 = "11";
System.out.println(s3 == s4);
}
测试结果:

原因分析:
通过s1、s2增加final修饰符,s1和s2的值赋值后不允许改变,这样编译器在编译时会把s3编译成s3="11",所以在执行时会字符串常量池中添加“11”这个常量,执行s4时会在常量池中找到“11”这个常量, s4会执行堆中已存在的字符串对象。因此s3和s4相等。

intern做了什么
intern()方法:
public String intern()
JDK源代码如下图:

返回字符串对象的规范化表示形式。
一个初始时为空的字符串池,它由类 String 私有地维护。
当调用 intern 方法时,如果池已经包含一个等于此 String 对象的字符串(该对象由 equals(Object) 方法确定),
则返回池中的字符串。否则,将此 String 对象添加到池中,并且返回此 String 对象的引用。
它遵循对于任何两个字符串 s 和 t,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true。
所有字面值字符串和字符串赋值表达式都是内部的。
返回:
一个字符串,内容与此字符串相同,但它保证来自字符串池中。
尽管在输出中调用intern方法并没有什么效果,但是实际上后台这个方法会做一系列的动作和操作。
在调用”ab”.intern()方法的时候会返回”ab”,但是这个方法会首先检查字符串池中是否有”ab”这个字符串,
如果存在则返回这个字符串的引用,否则就将这个字符串添加到字符串池中,然会返回这个字符串的引用。
测试代码:
public static void test8_3(){
String s1="11";
String s2=new String("11");
String s3=s2.intern();
System.out.println(s1==s2);//#1
System.out.println(s1==s3);//#2
}
测试结果:
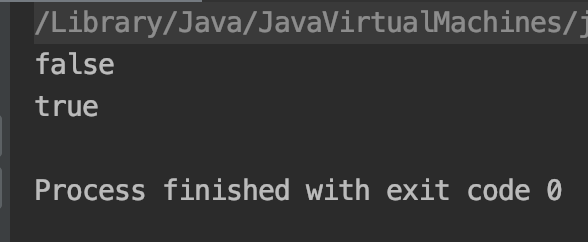
原因分析:
结果 #1:因为s1指向的是字符串中的常量,s2是在堆中生成的对象,所以s1==s2返回false。
结果 #2:s2调用intern方法,会将s2中值(“string”)复制到常量池中,但是常量池中已经存在该字符串(即s1指向的字符串),
所以直接返回该字符串的引用,因此s1==s2返回true。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
