

JVM学习笔记之栈区
本文主要内容:
栈是什么?栈帧又是什么?在JVM中,main方法调用say方法后,是怎么运行的?本文将详细讲解栈。希望大家学了之后,对栈有更深的了解。
心法:在JVM中,栈管运行,堆管存储。
栈数据结构特点:先进后出。生活中常见的case就是弹夹。最后一个压进弹夹的子弹,最先出弹夹。
Stack栈:
栈也叫栈内存,主管Java程序的运行,是在线程创建时创建,它的生命周期跟随线程的生命周期,线程结束,栈内存也就被释放了。对于栈来说,不存在垃圾回收问题,只要是线程一结束,该栈就over了。生命周期和线程一直的,是线程私有的。
8中基本类型的变量+对象的引用变量+实例方法都是在函数的栈内存中分配的。
栈中存储的是什么?
在了解栈之前,先来了解另一个概念:栈帧。
栈帧
栈帧(Stack Frame):用于支持虚拟机进行方法调用和方法执行的数据结构。它是虚拟机运行时数据区中的虚拟机栈的栈元素。
栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。每个方法从调用开始至执行完成的过程,都对应这一个栈帧在虚拟机栈里面从入栈到出栈的过程。
额,什么叭叭叭的,说的什么意思呢?简单如下:
栈帧中主要保存3类数据:
本地变量(Local variables):输入参数和输出参数以及方法内的变量;
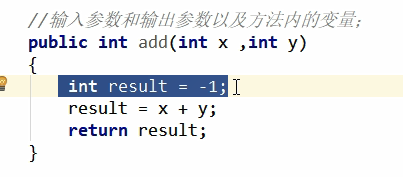
编辑
如上图中的 int x,int y就是输入参数
Int result就是输出参数。
其中的X、Y、result都是方法内的变量
栈操作(Operand Stack):记录出栈、入栈的操作;
栈帧数据(fram Date):包括类文件、方法等等。
栈运行的原理:
栈中的数据都是以栈帧的格式存在,栈帧是一个内存区块,是一个数据集,是一个有关方法(Method)和运行期,数据的数据集。
当一个方法A被调用的时候,就产生了一个栈帧F1,并被压到栈中;
A方法调用了B方法,于是产生了栈帧F2也被压入栈中;
B方法又调用了C方法,于是产生栈帧F3,也被压入到栈中;
依次类推。
当执行完毕后,先弹出F3栈帧,在弹出F2栈帧,在弹出F1栈帧。依次类推。
遵循”先进后出/后进先出”的原则。
代码演示:
写个main函数,在main方法中,调用say方法。然后查看输出结果。
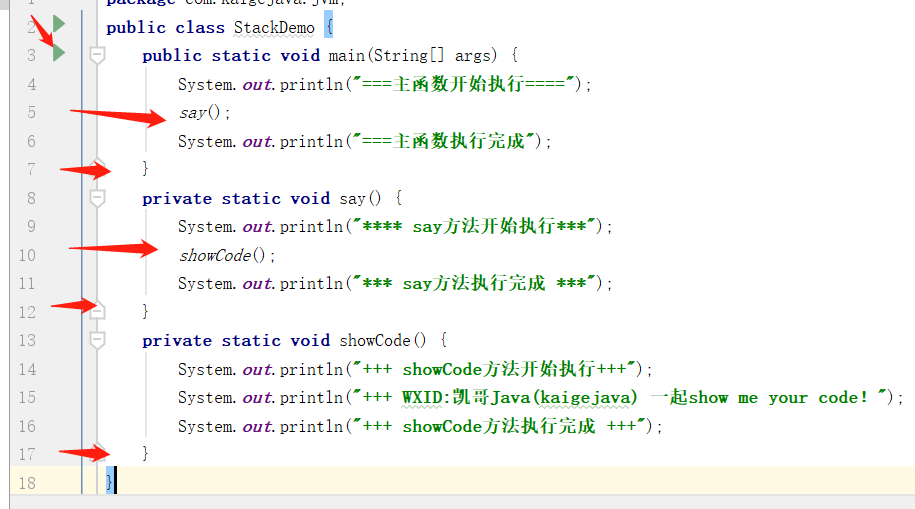
编辑
运行结果:

编辑
当程序运行到3行的时候,调用了主线程main函数,这个时候产生了栈帧F1,被压入栈,代码继续向下走;
当代码执行到第5行的时候,调用了say方法,这个时候产生了栈帧F2,发现后面还有代码需要执行,F2就被压入栈;
当执行第10行的时候,say方法调用了showCode方法,这个时候就产生了F3。进入方法showCode方法后,后面还有代码,F3压栈,继续执行。
当执行到第17行的时候,发现没有需要执行的了。F3就从栈里面被弹出栈了;
接着回到say方法里面,继续执行,程序走到第12行的时候,发现say方法执行完成了,于是F2就被弹出栈了;
程序回到main方法中,也就是该执行第6行了,执行完第6行,当到底7行的时候,发现主函数也执行了了,于是F1就被弹出栈了;
整个线程执行完成,栈区被清空。程序结束。如下图:
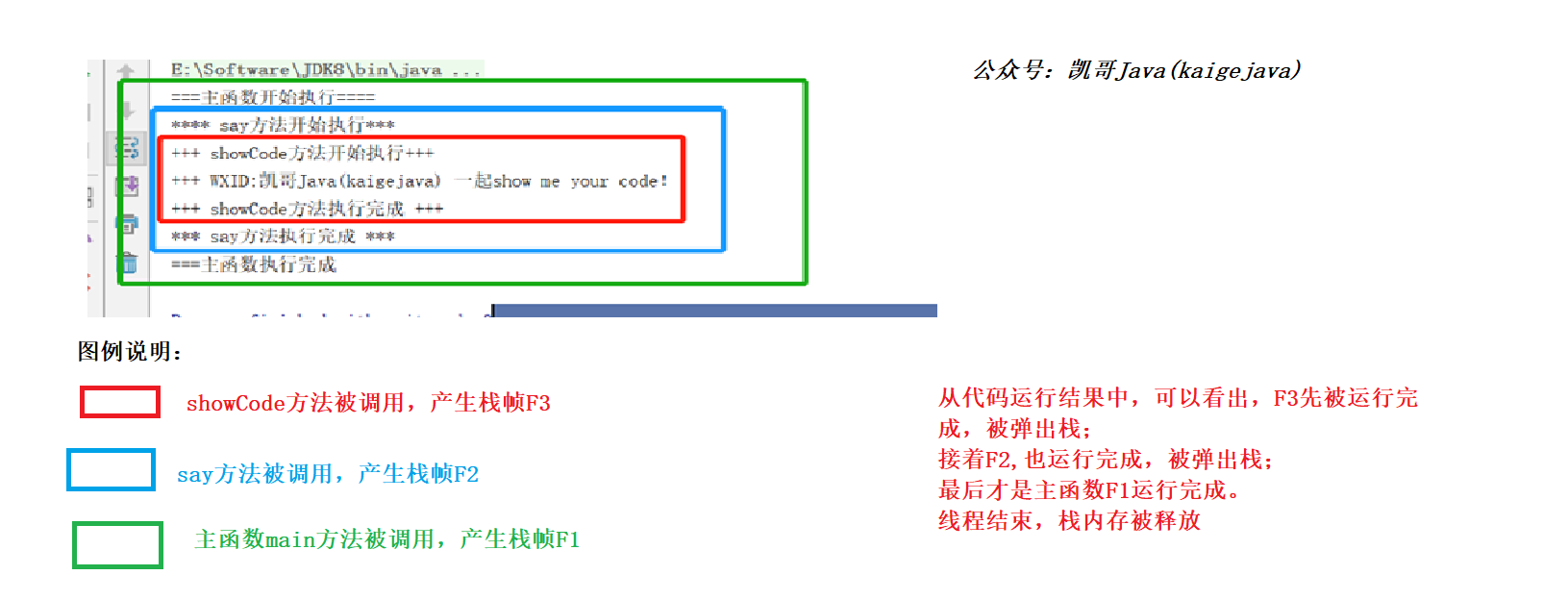
编辑
一个线程中的方法调用链可能会很长,很多方法都同时处于执行状态。对于执行引擎来说,在活动线程中(争抢到CPU执行权的),只有位于栈顶的栈帧才是有效的,成为当前栈帧(Current Stack Frame),与这个栈帧相关联的方法称为当前方法(Current Method)。执行引擎运行的所有字节码指令都是只针对于当前栈帧进行操作的。
栈帧概念模型如下图:
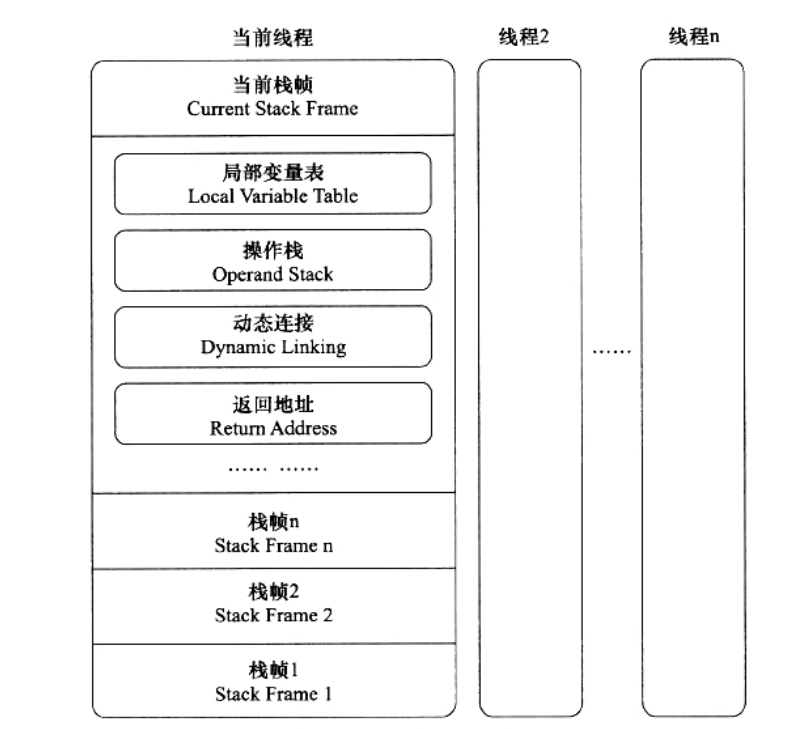
编辑
需要说明的是:每个方法执行的同时都会创建一个栈帧,用于存放局部变量表、操作数栈、动态连接、方法返回等等数据。每个方法从被调用至执行完成的过程,就对应着一个栈帧在虚拟机中入栈和出栈的过程。栈的大小和具体JVM的实现有关,通常在256K~756K之间,约等于1Mb左右。
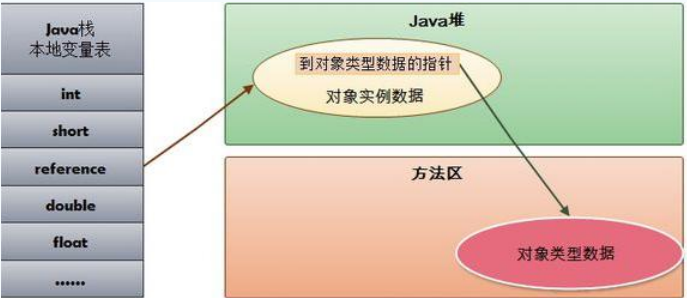
栈+堆+方法区的交互关系
编辑
HotSpot是使用指针的方法来访问对象的:
Java堆中会存放访问类元数据的地址,reference存放的就直接是对象的地址。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
