

分享Java技术文以及学习经验也有一段时间了,实际上作为程序员,我们都清楚学习的重要性,毕竟时代在发展,互联网之下,稍有一些落后可能就会被淘汰掉,因此我们需要不断去审视自己,通过学习来让自己得到相应的提升。
近段时间,我也了解到很多小伙伴不清楚作为Java程序员应该掌握什么样的核心知识?该如何学?折成了一个问题,所以花了一个星期,整理了这份1132页的"高分宝典",从Java集合到Spring底层源码分析,一滴不漏、全部概括清楚
因PDF内容过多,平台无法放外站链接。需要完整版PDF的朋友,关注、点赞后直接点点我**【Java进阶宝典】即可免费领取哦~

JVM虚拟机
- 理解Java虚拟机的原理
- Java虚拟机的架构
- 学会设置Java虚拟机的参数
- 跟踪垃圾回收——读懂虛拟机日志
- 类加载/卸载的跟踪
- 常用Java虚拟机参数
- 垃圾回收概念与算法
- 垃圾收集器和内存分配
- 性能监控工具
- 分析Java堆
- 深度解析Class文件结构

IO/NIO
- 阻塞 IO 模型
- 非阻塞 IO 模型
- 信号驱动 IO 模型
- 异步 IO 模型
- 多路复用 IO 模型

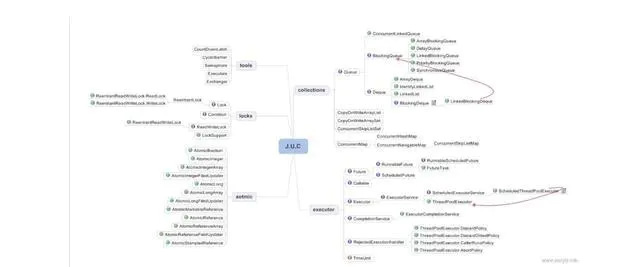
多线程并发
JAVA 并发知识库
JAVA 线程实现/创建方式
基于线程池的方式
4 种线程池
Spring原理
它是一个全面的、企业应用开发一站式的解决方案,贯穿表现层、业务层、持久层。但是 Spring仍然可以和其他的框架无缝整合。
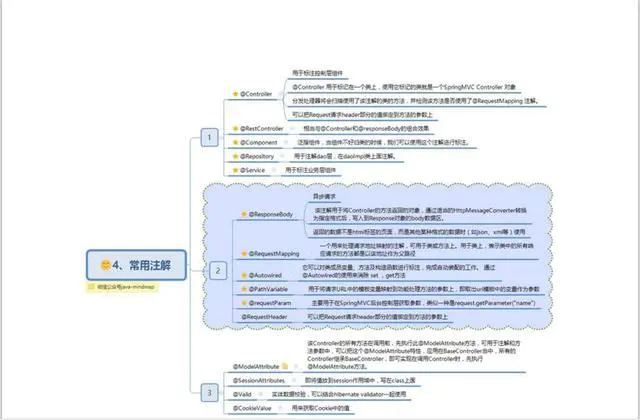
Spring常用注解
bean 注入与装配的的方式有很多种,可以通过 xml,get set 方式,构造函数或者注解等。简单易用的方式就是使用 Spring 的注解了,Spring 提供了大量的注解方式。
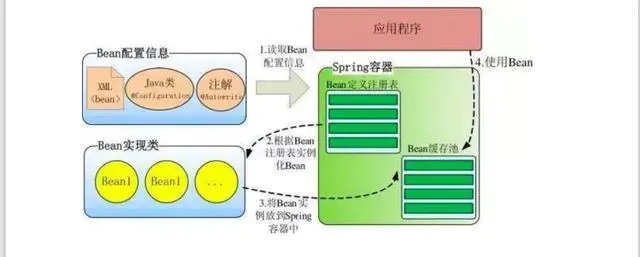
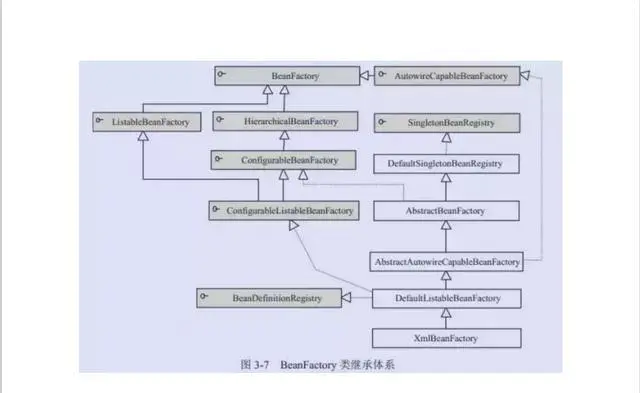
Spring IOC 原理
Spring 通过一个配置文件描述 Bean 及 Bean 之间的依赖关系,利用 Java 语言的反射功能实例化Bean 并建立 Bean 之间的依赖关系。** Spring 的 IoC 容器**在完成这些底层工作的基础上,还提供了 Bean 实例缓存、生命周期管理、 Bean 实例代理、事件发布、资源装载等高级服务。

beanfactory-框架基础设施
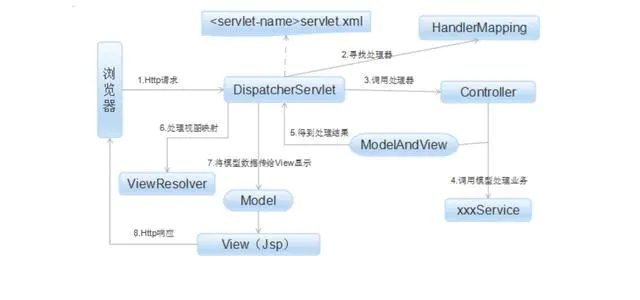
Spring MVC 原理
Spring 的模型-视图-控制器(MVC)框架是围绕一个 dispatcherServlet 来设计的,这个 Servlet会把请求分发给各个处理器,并支持可配置的处理器映射、视图渲染、本地化、时区与主题渲染等,甚至还能支持文件上传。
Spring Boot 原理
Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化新 Spring 应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot 致力于在蓬勃发展的快速应用开发领域(rapid applicationdevelopment)成为领导者。

Spring事务
- 本地事务
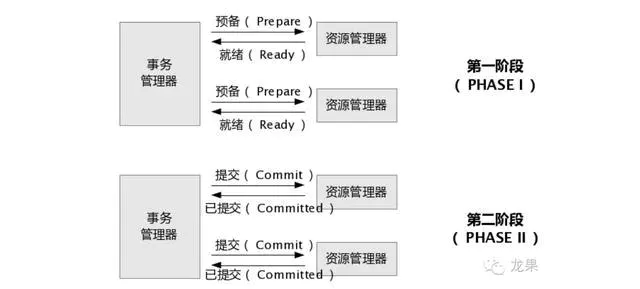
- 分布式事务
- 两阶段提交
Mybatis 缓存
Mybatis 中有一级缓存和二级缓存,默认情况下一级缓存是开启的,而且是不能关闭的。一级缓存是指 sqlSession 级别的缓存,当在同一个 sqlSession 中进行相同的 sql 语句查询时,第二次以后的查询不会从数据库查询,而是直接从缓存中获取,一级缓存最多缓存 1024 条 sql。二级缓存是指可以跨 sqlSession 的缓存。是 mapper 级别的缓存,对于 mapper 级别的缓存不同的sqlsession 是可以共享的。

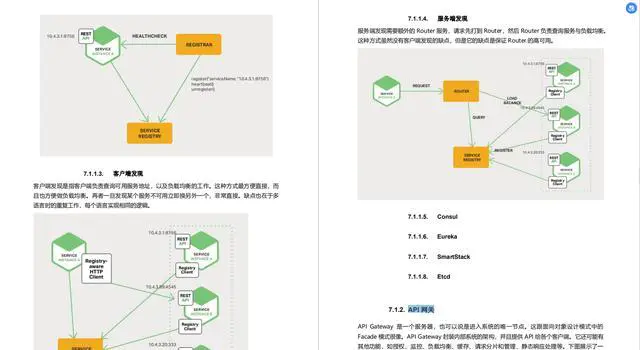
微服务
日志
- Slf4j
- Log4j
- LogBack
- ELK
- Logback 优点
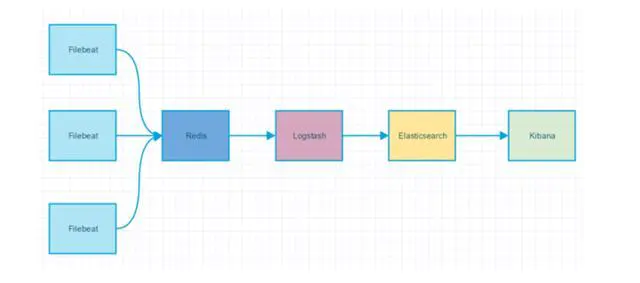
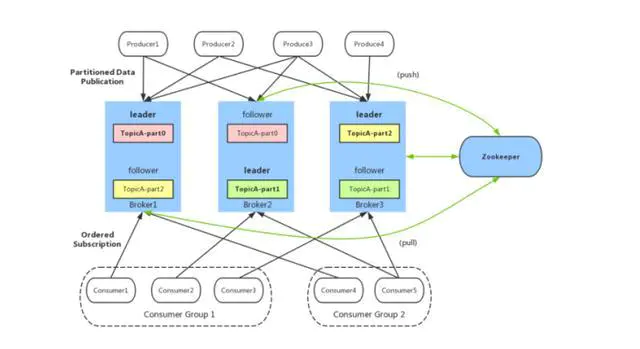
Kafka
Kafka 是一种高吞吐量、分布式、基于发布/订阅的消息系统,最初由 LinkedIn 公司开发,使用Scala 语言编写,目前是 Apache 的开源项目。

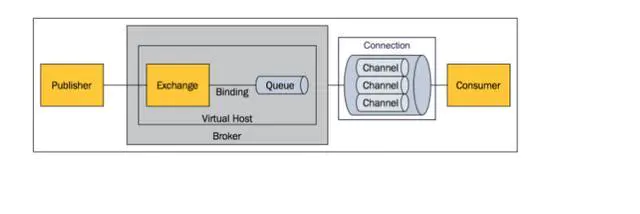
RabbitMQ
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
MongoDB
MongoDB 是由 C++语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下,添加更多的节点,可以保证服务器性能。MongoDB 旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。

因PDF内容过多,平台无法放外站链接。需要完整版PDF的朋友,关注、点赞后直接点点我**
【Java进阶宝典】即可免费领取哦~**
结束发言
文章概括到这里基本上就差一个结尾了,需要PDF的文档的朋友看上面。最后小编祝大家前程似锦,殊途同归。

版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
