

@
1、线性表的概念
线性表是最常见也是最简单的一种数据结构。简言之, 线性表是n个数据元素的有限序列。 其一般描述为:
一个数据元素通常包含多个数据项, 此时每个数据元素称为记录, 含有大量的记录的线性表称为文件。
例如十二生肖,就是一个线性表:

在稍微复杂的线性表中, 一个数据元素可以由若干个数据项组成。
例如例如,学生名单,含学生的学号、姓名、年龄、性别等信息。
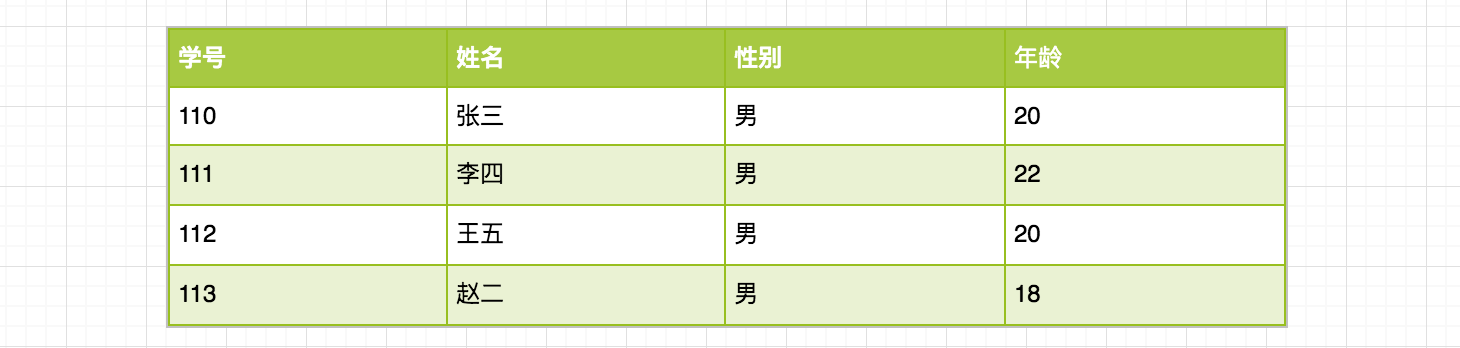
从上例中可以看出每个数据元素具有相同的特性:
- 即每个数据元素最多只能有一个直接前趋元素, 每个数据元素最多只能有一个直接后继元素
- 只有第一个数据元素没有直接前趋元素, 而最后一个数据元素没有直接后继元素
线性表是一个比较灵活的数据结构, 它的长度根据需要增长或缩短, 也可以对线性表的数据元素进行不同的操作(如访问数据元素, 插入、 删除数据元素等)。
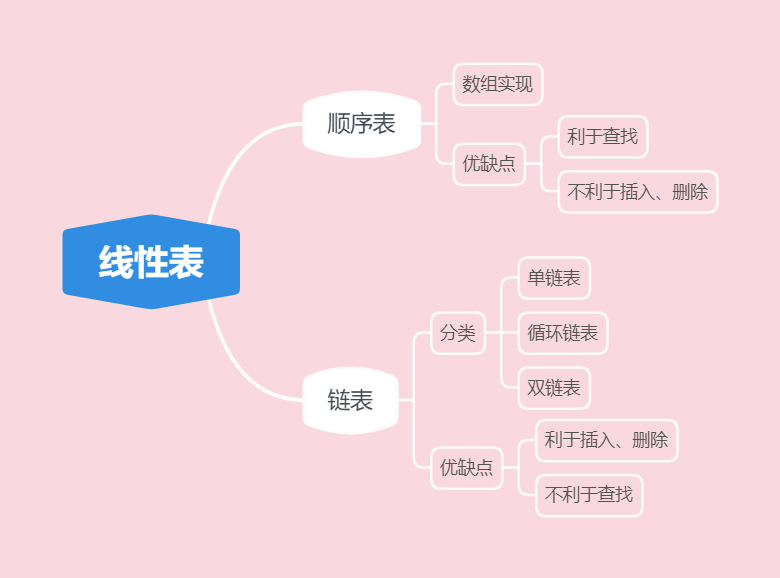
线性表的存储结构分为顺序存储和链式存储。
2、顺序表
线性表的顺序存储, 也称为向量存储, 又可以说是一维数组存储。 线性表中结点存放的物理顺序与逻辑顺序完全一致, 它叫向量存储(一般指一维数组存储)。
顺序表存储结构如下:

线性表的第一个数据元素的位置通常称做起始位置或基地址。
表中相邻的元素之间具有相邻的存储位置。
2.1、顺序表初始化
顺序分配的线性表可以直接使用一维数组描述为:
type arraylist[]; //type 的类型根据实际需要确定//
在Java中,由于所有类都是Object的子类,所以,可以声明一个Object数组:
//存放元素的数组
private Object list[];
该代码只是对应用数组的声明, 还没有对该数组分配空间, 因此不能访问数组。 只有对数组进行初始化并申请内存资源后, 才能够对数组中元素进行使用和访问。
//默认容量
private static int defaultSize=10;
//表长:实际存储元素的个数
private int length;
public SequenceList() {
//初始化数组,声明内存资源
this.list=new Object[defaultSize];
}
2.2、添加
在这个方法里,我们对数组进行了动态扩容,一旦数组空间溢出(size>=defaultSize),就创建一个新的数组,容量为原来的两倍,将原数组的元素搬到新数组。示意图如下
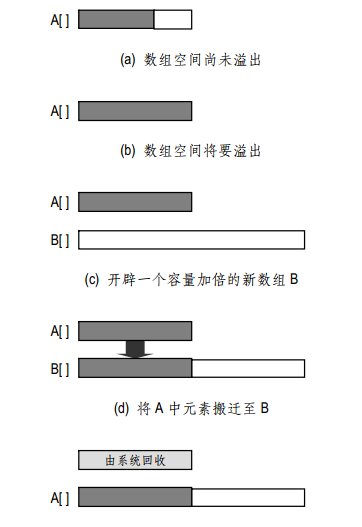
插入操作是将将操作位置的所有后继元素向后顺次移动。
/**
* 添加元素
* @param item 数据元素
* @param index 位置
*/
public void add(Object item,int index){
//list[0]=item;
if (index>=size||index<0){
System.out.println("index can not be this value");
return;
}
//数组扩容
if (size>=defaultSize){
defaultSize=2*defaultSize;
//数组容量扩充两倍
Object[] newArray=new Object[defaultSize];
for (int j=0;j<list.length;j++){
newArray[j]=list[j];
}
list=newArray;
}
//插入
for (int k=size;k>=index;k--){
//所有元素后移一位
list[k+1]=list[k];
list[index]=item;
}
size++;
}
时间复杂度分析
-
数组扩容
在数组扩容的操作中,需要把旧数组复制到新的数组,时间复杂度是O(n)。 -
插入操作
插入操作的主要时间消耗是移动数组元素,该语句最坏的情况下, 移动次数是 list.length,最好的情况下是 0。时间复杂度是O(n)。
2.3、删除
/**
* 移除数据元素
* @param index
*/
public void remove(int index){
if (index>list.length-1||index<0){
System.out.println("index can not be this value");
return;
}
//所有元素前移
for (int k=index;k<list.length;k++){
list[k]=list[k+1];
}
size--;
}
时间复杂度分析
删除的操作和添加类似,删除是将元素前移,最好情况是移动0次,最坏情况是移动list.length次,时间复杂度为O(n)。
2.4、删除
/**
* 取数据元素
* @param index
* @return
*/
public Object get(int index){
return list[index];
}
时间复杂度分析
取数据元素直接根据数组下标获取即可,不存在元素的移动,所以时间复杂度为O(1)。
2.5、更新
/**
* 更新数据元素
* @param o
* @param index
*/
public void set(Object o,int index){
if (index>=size||index<0){
System.out.println("index can not be this value");
return;
}
list[index]=o;
}
时间复杂度分析
更新和上面的获取类似,时间复杂度为O(1)。
2.6、AraayList和Vector
Java本身也提供了顺序表的实现:java.util.ArrayList和java.util.Vector。
实际上,java.util.ArrayLis的实现用了一些Native方法,可以直接操作内存效率会高很多。了解ArrayList源码:ArrayList源码阅读笔记
java.util.Vector是一个历史遗留类,并不建议使用。
3、链表
线性表的顺序存储结构的特点是逻辑关系上相邻的两个元素在物理位置上也相邻, 因此随机存取元素时比较简单, 但是这个特点也使得在插入和删除元素时, 造成大量的数据元素移动, 同时如果使用静态分配存储单元, 还要预先占用连续的存储空间, 可能造成空间的浪费或空间的溢出。 如果采用链式存储, 就不要求逻辑上相邻的数据元素在物理位置上也相邻, 因此它没有顺序存储结构所具有的缺点, 但同时也失去了可随机存取的优点。
3.1、单向链表
单项链表是最简单的链表,每个节点包含两部分,数据域 (data)和指针域 (next),数据域存放数据元素的值,指针域存放存放相邻的下一个结点的地址。
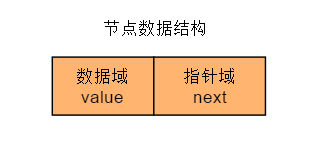
单向链表是指结点中的指针域只有一个沿着同一个方向表示的链式存储结构。示意图如下:
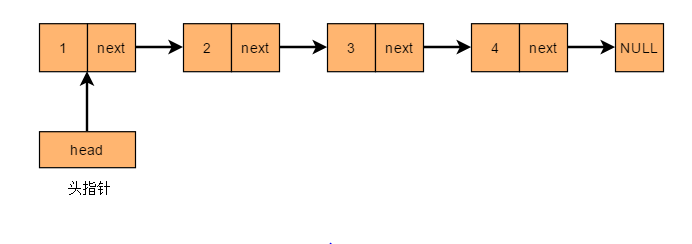
3.1.1、节点类
因为结点是一个独立的对象, 所以需要一个独立的结点类。 以下是一个结点类的定义:
/**
* 节点类
*/
class Node<T>{
private Object data; //数据
private Node next; //下一个节点
Node(Object it,Node nextVal){
this.data=it;
this.next=nextVal;
}
Node(Node nextVal){
this.next=nextVal;
}
Node(){}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
}
3.1.2、单链表类
需要定义一个单链表类,包含一些基本的属性,构造方法:
public class SinglyLinkedList<T> {
private Node head; //头结点
private Node tail; //尾节点
private int size; //链表长度
public SinglyLinkedList(){
head=null;
tail=null;
size=0;
}
}
3.1.2、获取元素
这里实现了按照序号获取元素和获取元素数据域的方法:
/**
* 获取元素
* @param index
* @return
*/
public Node getNodeByIndex(int index){
if (index>=size||size<0){
System.out.println("Out of bounds");
return null;
}
Node node=head;
for (int i=0;i<size;i++,node=node.next){
if (index==i){
return node;
}
}
return null;
}
/**
* 获取数据元素数据域
* @param index
* @return
*/
public Object get(int index){
return getNodeByIndex(index).getData();
}
时间复杂度分析
这是一个循环,从头(head)开始, 然后再逐个向后査找,直到找到第index个元素,时间复杂度为O(n)。
3.1.3、插入元素
这里有三种插入方法:
- 头插入法
头插入法示意图如下:
/**
* 头插入法
* @param element
*/
public void addHead(T element){
head=new Node(element,head);
//如果插入的是空链表,尾结点即首节点
if(tail==null){
tail=head;
}
size++;
}
- 尾插入法
尾插入法和头插入法类似
/**
* 尾插入
* @param element
*/
public void addTail(T element){
//如果是空表
if (head==null){
head=new Node(element,null);
tail=head;
}else {
Node node=new Node(element,null);
//旧的尾结点指向插入的节点
tail.setNext(node);
//尾结点后移
tail=node;
}
size++;
}
- 中间插入法
中间插入,改变前面节点的指向和插入元素的指向就可以了,示意图如下: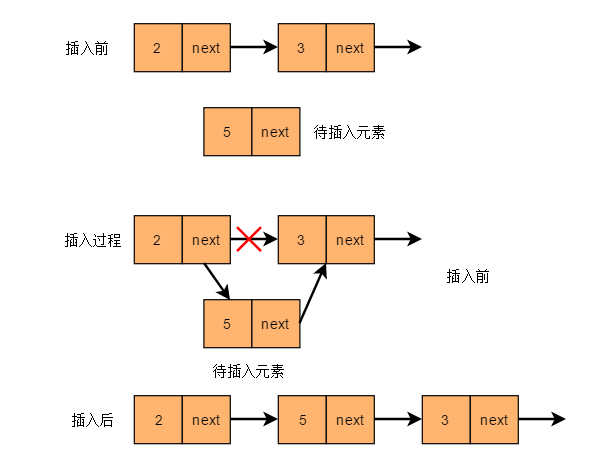
/**
* 在指定位置插入数据元素
* @param element
* @param index
*/
public void add(T element,int index){
if (index>size||size<0){
System.out.println("Out of bounds");
return;
}
if (index==0){
addHead(element);
}else if (index==size){
addTail(element);
}else{
//index位置前节点
Node preNode=getNodeByIndex(index-1);
//index位置节点
Node indexNode=getNodeByIndex(index);
//插入的节点,后继执行之前index位置的节点
Node insertNode=new Node<T>(element,indexNode);
//前趋节点指向插入的节点
preNode.setNext(insertNode);
size++;
}
}
3.1.4、删除元素
删除元素,找到目标元素,改变前节点的指向。
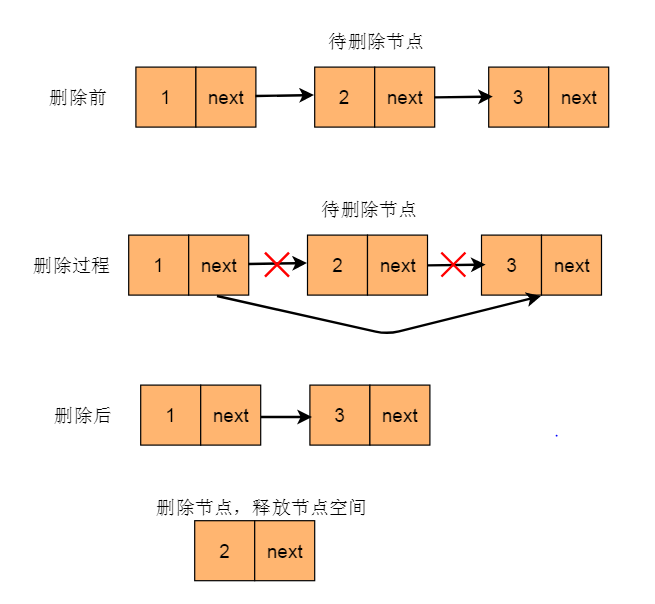
/**
* 删除元素
* @param index
*/
public void remove(int index){
if (index>size||size<0){
System.out.println("Out of bounds");
return;
}
//删除头节点,只需将头节点置为下一个节点
if (index==0){
head=head.next;
} else {
//将要被删除的节点
Node indexNode=getNodeByIndex(index);
//被删除节点的前一个节点
Node preNode=getNodeByIndex(index-1);
//前节点指向目标节点的后节点
preNode.setNext(indexNode.next);
//如果删除的是最后一个元素,尾结点前移
if(index==size-1){
tail=preNode;
}
}
size--;
}
3.2、循环链表
循环链表又称为循环线性链表, 其存储结构基本同单向链表。
它是在单向链表的基础上加以改进形成的, 可以解决单向链表中单方向查找的缺点。 因为单向链表只能沿着一个方向, 不能反向查找, 并且最后一个结点指针域的值是 null,为解决单向链表的缺点, 可以利用末尾结点的空指针完成前向查找。 将单链表的末尾结点的指针域的 null 变为指向第—个结点, 逻辑上形成一个环型, 该存储结构称之为单向循环链表。 示意图如下:
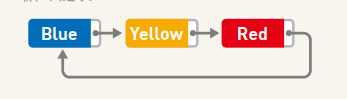
它相对单链表而言, 其优点是在不增加任何空间的情况下, 能够已知任意结点的地址,可以找到链表中的所有结点(环向查找)。
空的循环线性链表根据定义可以与单向链表相同, 也可以不相同。 判断循环链表的末尾结点条件也就不同于单向链表, 不同之处在于单向链表是判别最后结点的指针域是否为空, 而循环线性链表末尾结点的判定条件是其指针域的值指向头结点。
循环链表的插入、 删除运算基本同单向链表, 只是查找时判别条件不同而已。 但是这种循环链表实现各种运算时的危险之处在于: 链表没有明显的尾端, 可能使算法进入死循环。
3.3、双链表
在前面的单链表里,链表只有一个指向后一个节点的指针,而双链表多出一个指向前一个节点的指针。这样可以从任何一个节点访问前一个节点,当然也可以访问后一个节点,以至整个链表。

3.3.1、节点类
对比单链表,节点类里需要添加前趋节点。
/**
* 节点类
*/
class Node<T>{
private Object data; //数据
private Node next; //下一个节点
private Node prev; //上一个节点
Node(Node prevVal,Object it,Node nextVal){
this.data=it;
this.next=nextVal;
this.prev=prevVal;
}
Node(Node prevVal,Node nextVal){
this.prev=prevVal;
this.next=nextVal;
}
Node(){}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
public Node getPrev() {
return prev;
}
public void setPrev(Node prev) {
this.prev = prev;
}
}
3.3.2、双链表类
定义一个双链表类,包含构造方法和一些基本的属性。
public class DoublyLinkedList<T> {
private Node head; //头结点
private Node tail; //尾节点
private int size; //链表长度
public DoublyLinkedList(){
head=null;
tail=null;
size=0;
}
}
3.3.3、获取元素
双向链表查询结点的实现基本同单向链表, 只要按照 next 的方向找到该结点就可以了。
/**
* 获取数据元素
* @param index
* @return
*/
public Node getNodeByIndex(int index){
if (index>=size||size<0){
System.out.println("Out of bounds");
return null;
}
Node node=head;
for (int i=0;i<=size;i++,node=node.next){}
return node;
}
/**
* 获取数据元素数据域
* @param index
* @return
*/
public Object get(int index){
return getNodeByIndex(index).getData();
}
3.3.4、插入元素
- 头插入法:将新的节点前趋指向null,后继指向头结点,头节点的前趋指向新节点
/**
* 头插入法
* @param element
*/
public void addHead(T element){
Node node=new Node(null,element,null);
// 如果表头为空直接将新节点作为头节点
if (head==null){
head=node;
}else{
//新节点后继指向头节点
node.next=head;
//头结点前趋指向新节点
head.prev=node;
//头结点重新赋值
head=node;
}
}
- 尾插入法:尾结点的后继指向新节点,新节点的前趋指向尾结点
/**
* 尾插入
* @param element
*/
public void addTail(T element){
//新节点
Node node=new Node(null,null);
// 如果表头为空直接将新节点作为头节点
if (head==null){
head=node;
}else{
//尾结点的后继指向新节点
tail.next=node;
//新节点的前趋指向尾结点
node.prev=tail;
//尾结点重新赋值
tail=node;
}
size++;
}
- 中间插入法:根据索引插入数据元素,找到插入位置的元素,改变此元素的前趋指向,和前趋元素的后继指向
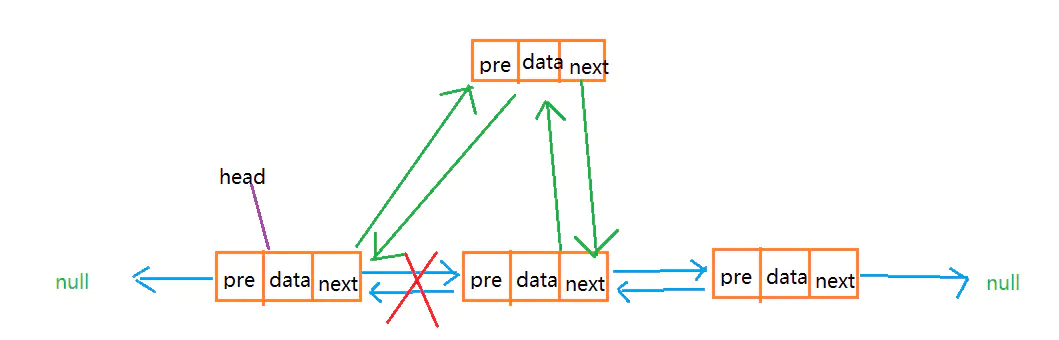
/**
* 从指定位置插入
* @param element
* @param index
*/
public void add(T element,int index){
if (index>size||size<0){
System.out.println("Out of bounds");
return;
}
if (index==0){
addHead(element);
}else if (index==size){
addTail(element);
}else{
//插入位置的节点
Node indexNode=getNodeByIndex(index);
//插入位置前趋节点
Node preNode=indexNode.prev;
//新节点,设置新节点的前趋和后继
Node node=new Node(preNode,indexNode);
//插入位置节点前趋指向新节点
indexNode.prev=node;
//前节点后继指向新节点
preNode.next=node;
}
}
3.3.5、删除元素
删除元素,只需要找到被删除的元素,改变前趋节点的后继,后继节点的前趋
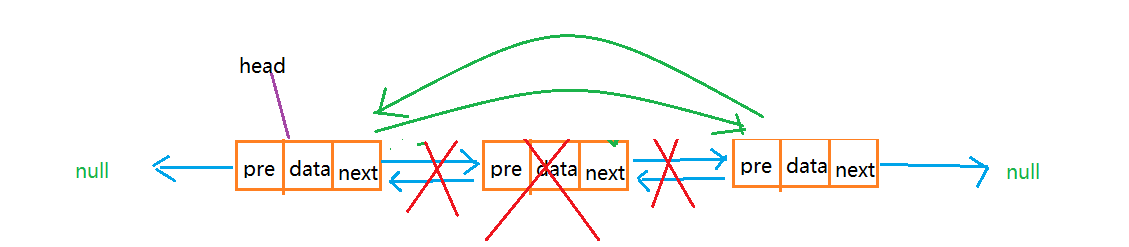
/**
* 删除元素
* @param index
*/
public void remove(int index){
if (index>size||size<0){
System.out.println("Out of bounds");
return;
}
//被删除的节点
Node node=getNodeByIndex(index);
//前趋
Node preNode=node.prev;
//后继
Node nextNode=node.next;
//尾结点
if (nextNode==null){
//前趋节点后继置为null
preNode.next=null;
//尾结点重新赋值
tail=preNode;
}else if(node.prev==null){ //头节点
//后继节点前趋置为null
nextNode.prev=null;
//头结点重新赋值
head=nextNode;
}else{
//前趋节点的后继指向后继节点
preNode.next=nextNode;
//后继节点的前趋指向前趋节点
nextNode.prev=preNode;
}
}
双向循环链表
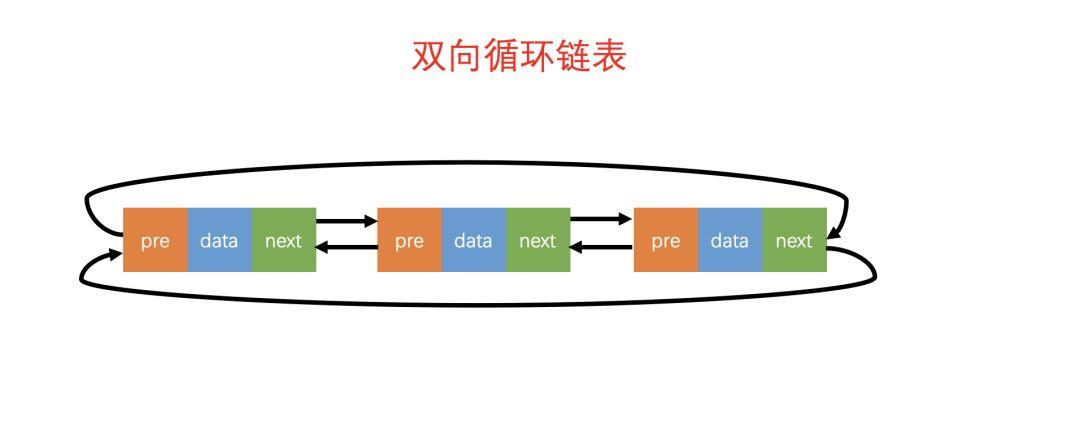
双向循环链表的各种算法与双向链表的算法大同小异, 其区别与单链表和单向循环链表的区别一样, 就是判断末尾结点的条件不同。
- 双向链表的末尾结点后继指针域为空, 而双向循环链表的末尾结点的后继指针域指向第一个结点;
- 而反向査找时, 双向链表的头结点前趋指针域为空, 而双向循环链表的头结点的前趋指针域指向最后一个结点。
3.3、LinkedList
在Java的集合中,LinkedList是基于双向链表(jdk1.8以前是双向循环链表)实现的。
具体源码分析可查看:LinkedList源码阅读笔记
4、总结
本文为学习笔记类博客,主要资料来源如下!
参考:
【1】:邓俊辉 编著. 《数据结构与算法》
【2】:王世民 等编著 . 《数据结构与算法分析》
【3】: Michael T. Goodrich 等编著.《Data-Structures-and-Algorithms-in-Java-6th-Edition》
【4】:严蔚敏、吴伟民 编著 . 《数据结构》
【5】:程杰 编著 . 《大话数据结构》
【6】:数据结构知否知否系列之 — 线性表的顺序与链式存储篇
【7】:线性表及其算法(java实现)
【8】:数据结构与算法Java版——单链表的实现
【9】:数据结构与算法——单链表
【10】:《我的第一本算法书》
【11】:看动画轻松理解「链表」实现「LRU缓存淘汰算法」
【12】:java实现双向链表
【13】:双向链表的实现(Java)
【14】:双向链表和双向循环链表
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。