

集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / Datanode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
服务器系统设置
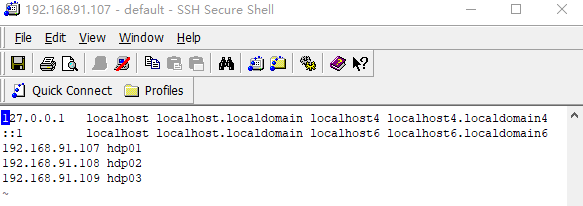
[root@hdp01 hadoop]# vi /etc/hosts
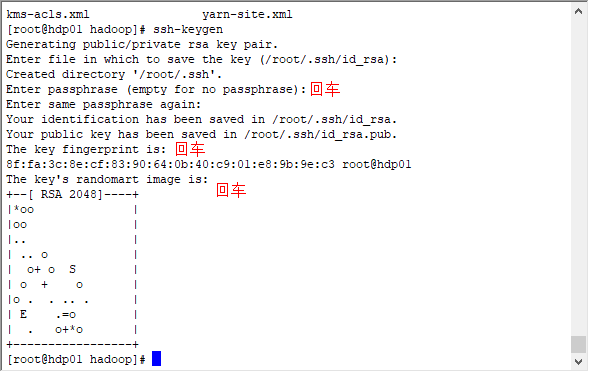
配置ssh免密登陆
[root@hdp01 hadoop]# ssh-keygen
yum安装ssh服务 在三个节点都要安装
[root@hdp01 hadoop]# yum -y install openssh-clients.x86_64
[root@hdp02 hadoop]# yum -y install openssh-clients.x86_64
[root@hdp03 hadoop]# yum -y install openssh-clients.x86_64
将生成的秘钥发到hdp01、hdp02、hdp03上
[root@hdp01 hadoop]# ssh-copy-id hdp01
[root@hdp01 hadoop]# ssh-copy-id hdp02
[root@hdp01 hadoop]# ssh-copy-id hdp03
在hdp01上测试一下,看一看能不能不输入密码,就能登录到hdp02、hdp03上
[root@hdp01 hadoop]# ssh hdp02
[root@hdp01 hadoop]# ssh hdp03
Jdk环境安装
解压jdk
[root@hdp01apps]#tar -zxvf jdk-8u181-linux-x64.tar.gz
配置环境变量
[root@hdp01 jdk1.8.0_181]# vi /etc/profile
export JAVA_HOME=/home/hadoop/apps/jdk1.8.0_181
export PATH=$JAVA_HOME/bin:$PATH
保存退出。Shift+zz
[root@hdp01 jdk1.8.0_181]# vi /etc/profile
查看java是否存在
[root@hdp01 jdk1.8.0_181]# java -version
HADOOP安装部署
解压安装包
[root@hdp01 apps]# tar -zxvf hadoop-2.8.0.tar.gz
修改配置文件
[root@hdp01 hadoop]# vi /etc/profile
添加一下内容:
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
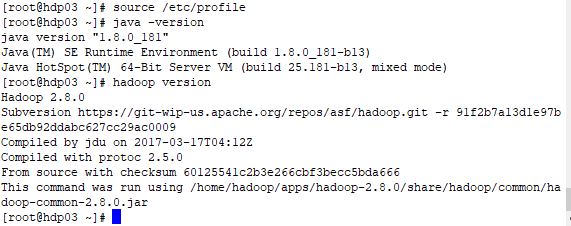
[root@hdp01 hadoop]# source /etc/profile
[root@hdp01 hadoop]# hadoop version
修改配置文件
修改配置文件 /home/hadoop/apps/hadoop-2.8.0/etc/hadoop/
最简化配置如下:
[root@hdp01 hadoop]# cd /home/hadoop/apps/hadoop-2.8.0/etc/hadoop
vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/home/hadoop/apps/jdk1.8.0_181
vi core-site.xml
<configuration>
<!-- 该配置是指定hadoop所用的分布式文件系统为hdfs,并且指定hdfs的namenode所在的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp01:9000</value>
</property>
ZZ
<!-- 该配置是指定hadoop集群的各个程序组件在运行时,产生的临时数据所存放的本地目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hdptmp</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hdp-Meta</value>
</property>
<!---namenode配置多个目录和datanode配置多个目录,有什么区别?---->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hdp-blocks</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>128m</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hdp01:50090</value>
</property>
</configuration>
[root@hdp01 hadoop]# cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hdp01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vi slaves
hdp01
hdp02
hdp03
在hdp02和hdp03是分别创建
[root@hdp02 home]# mkdir -p /home/hadoop/apps
[root@hdp03 home]# mkdir -p /home/hadoop/apps
在hdp01上,经之前安装好jdk、/etc/profile 、 /etc/hosts
文件分别发送到hsp02和hdp03上
[root@hdp01 hadoop]# scp -r /home/hadoop/apps/jdk1.8.0_181/ hdp02:/home/hadoop/apps/
[root@hdp01 hadoop]# scp -r /home/hadoop/apps/jdk1.8.0_181/ hdp03:/home/hadoop/apps/
[root@hdp01 hadoop]# scp -r /home/hadoop/apps/hadoop-2.8.0 hdp02:/home/hadoop/apps/
[root@hdp01 hadoop]# scp -r /home/hadoop/apps/hadoop-2.8.0 hdp03:/home/hadoop/apps/
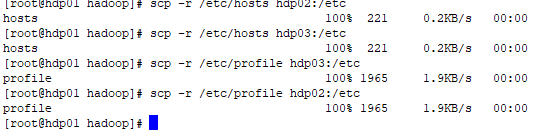
[root@hdp01 hadoop]# scp -r /etc/hosts hdp02:/etc
[root@hdp01 hadoop]# scp -r /etc/hosts hdp03:/etc
[root@hdp01 hadoop]# scp -r /etc/profile hdp02:/etc/profile
[root@hdp01 hadoop]# scp -r /etc/profile hdp03:/etc/profile
分别在hdp02、hdp03上执行以下命令
[root@hdp02 hadoop]# source /etc/profile
[root@hdp03 hadoop]# source /etc/profile

启动集群
在hdp01上执行
初始化HDFS
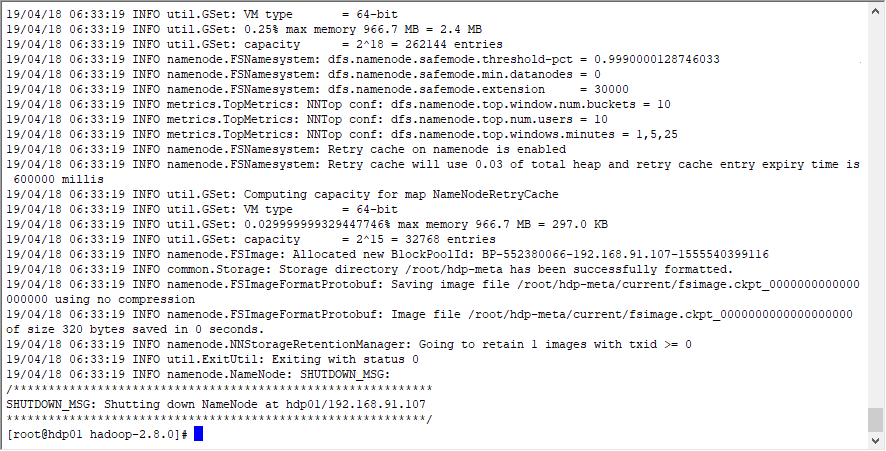
[root@hdp01 hadoop]# hadoop namenode -format
自动化脚本启动:
[root@hdp01 hadoop-2.8.0]# start-all.sh
查看hadoop启动的线程:
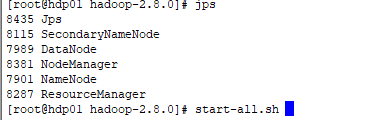
在hdp01
[root@hdp01 hadoop-2.8.0]# jps
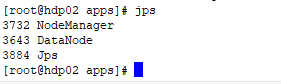
在hdp02
[root@hdp02 hadoop-2.8.0]# jps
在hdp03
[root@hdp03 hadoop-2.8.0]# jps

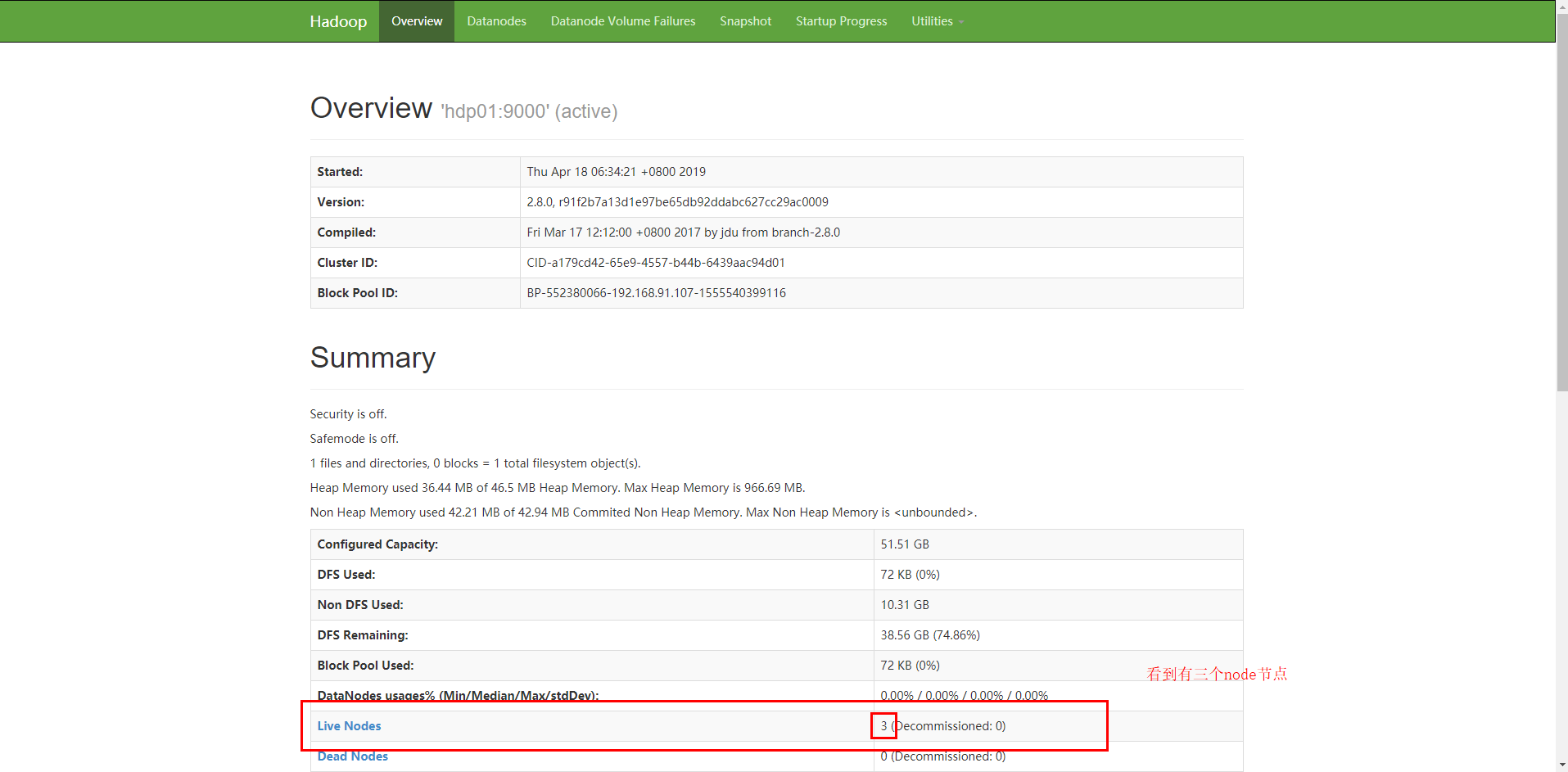
namenode在浏览器的界面
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
