

文章目录
1. RecordReader概述
RecordReader又叫记录读取器,是用来加载数据并把数据转换为适合mapper读取的键值对。RecordReader实例是由输入格式定义的,默认的输入格式为TextInputFormat,提供了一个LineRecordReader。这个类会把输入文件的每一行作为一个新的值,关联到每一行的键则是该行在文件中的字节偏移量。RecordReader会在输入块上被重复地调用直到整个输入块被处理完毕,每一次调用RecordReader都会调用Mapper的map()方法。
SequenceFileInputFormat对应的RecordReader是SequenceFileRecordReader。LineRecordReader是每行的偏移量作为读入map的key,每行的内容作为读入map的value。很多时候hadoop内置的RecordReader并不能满足需求,比如在读取记录时,希望map读入的key值不是偏移量而是行号或者是文件名,这个时候可以自己定义RecordReader。
2. RecordReader的应用
2.1 RecordReader的实现步骤
- 继承抽象类RecordReader,实现RecordReader的一个实例。
- 实现自定义的InputFormat类,重写InputFormat中的CreateRecordReader()方法,返回值是自定义的RecordReader实例。
2.2 需求分析
分别计算奇数行和偶数行的累加和。
2.3 上传测试文件

hadoop fs -put recordread /recordread
2.4 执行代码
MyInputFormat:
package com.mapreduce.recordread;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
import java.nio.file.FileSystem;
import java.nio.file.Path;
public class MyInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
//返回自定义的RecordReader
return new MyRecordReader();
}
//为了使切分数据时行号不发生混乱,这里设置为不进行切分
protected boolean isSplitable(FileSystem fileSystem, Path filename){
return false;
}
}
MyRecordReader:
package com.mapreduce.recordread;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.LineRecordReader;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.LineReader;
import java.io.IOException;
public class MyRecordReader extends RecordReader<LongWritable, Text> {
private long start; //起始位置(相对于整个分片而言)
private long end; //结束位置(相对于整个分片而言)
private long pos; //当前位置
private FSDataInputStream fin = null; //文件输入流
private LongWritable key = null;
private Text value = null;
private LineReader reader = null; //定义行阅读器
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException{
FileSplit fileSplit = (FileSplit)split; //获取分片
start = fileSplit.getStart(); //获取起始位置
end = start + fileSplit.getLength(); //获取结束位置
Configuration configuration = context.getConfiguration(); //创建配置
Path path = fileSplit.getPath(); //获取文件路径
FileSystem fileSystem = path.getFileSystem(configuration); //根据路径获取文件系统
fin = fileSystem.open(path); //打开文件输入流
fin.seek(start); //找到开始位置开始读取
reader = new LineReader(fin); //创建一个行阅读器
pos = 1; //将位置设为1,从第一行开始记录行号
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if(key == null){
key = new LongWritable();
}
key.set(pos);
if(value == null){
value = new Text();
}
if(reader.readLine(value) == 0){ //此处的value时用来存储给定的行,而返回值是读取的字节数,包括换行
//如果只有一个换行也算一行
return false;
}
pos++;
return true;
}
@Override
public LongWritable getCurrentKey(){return key;}
@Override
public Text getCurrentValue() {return value;}
@Override
public float getProgress(){return 0;}
@Override
public void close() throws IOException{
if(fin != null) fin.close();
}
}
MyMapper:
package com.mapreduce.recordread;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text, LongWritable, Text> {
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException{
//System.out.println("key = "+key+" value = "+value);
context.write(key, value); //直接将读取的记录写出去
}
}
MyPartitioner:
package com.mapreduce.recordread;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<LongWritable, Text> {
@Override
public int getPartition(LongWritable key, Text value, int numPartitions) {
//偶数放到第二个分区进行计算
if(key.get()%2 == 0){
//偶数行将输入到reduce的key设置为1
key.set(1);
return 1;
}else {
//奇数放在第一个分区进行计算
key.set(0);
return 0;
}
}
}
MyReducer:
package com.mapreduce.recordread;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<LongWritable, Text, Text, LongWritable> {
private Text outKey = new Text();
private LongWritable outValue = new LongWritable();
protected void reduce(LongWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException{
System.out.println("奇数行还是偶数行:"+key);
long sum = 0;
for(Text value:values){
sum += Long.parseLong(value.toString());
}
//判断奇偶数
if(key.get() == 0){
outKey.set("奇数之和为:");
}else{
outKey.set("偶数之和为:");
}
outValue.set(sum);
context.write(outKey, outValue);
}
}
RecordReaderApp:
package com.mapreduce.recordread;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.net.URI;
public class RecordReaderApp {
private static final String INPUT_PATH = "hdfs://master001:9000/recordreader";
private static final String OUTPUT_PATH = "hdfs://master001:9000/recordput";
public static void main(String[] args) throws Exception{
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
//提升代码的健壮性
final FileSystem fileSystem = FileSystem.get(URI.create(INPUT_PATH), conf);
if(fileSystem.exists(new Path(OUTPUT_PATH))){
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "RecordReaderApp");
//run jar class 主方法
job.setJarByClass(RecordReaderApp.class);
//设置map
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
//设置reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置partition
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(2);
//设置input format
job.setInputFormatClass(MyInputFormat.class);
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
//设置output format
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
//提交job
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
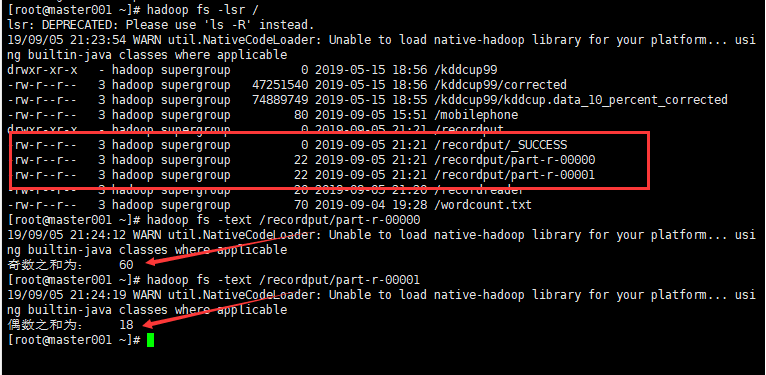
2.5 效果截图
3. 小结
如果程序或者集群出现任何BUG,欢迎下方留言讨论。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。