

1. 大数据和Hadoop
研究学习大数据,自然要从Hadoop开始。 Hadoop不是一个简单的软件,而是有一些列软件形成的生态,其核心思想来自Google当初发布的三篇论文,后来做了开源的实现, 谷歌的实现和Hadoop的实现大致可以做这样的对应:
Google Map/Reduce <---> Hadoop MapReduce
Google GFS <---> Hadoop HDFS
Google BigTable <---> Hadoop HBase
Hadoop生态的所有组成部分,都是跑在linux环境下的,自然我们首先需要搭建linux环境。另外Hadoop之所以能处理“大”数据,是因为其分布式的特性,可以利用分布式计算构建服务器集群,并可根据需要扩展。为了学习,我们先在本地计算机上利用虚拟机搭建linux环境,要模型集群环境,就多创建几个虚拟机就可以了。
为了玩儿这套东西,因为要创建几个虚拟机,所以的你的电脑内存最好不小于8G,因为跑Hadoop一般一个虚拟机需要2G,随便开3台虚拟机就占不少内存了。 不过前期为了学习,我先只给每台虚拟机分配1G内存,后面不够了在调整就行了。
2. 为什么选VirtualBox?
提起虚拟机,自然首先想到的就是大名鼎鼎的VMware。 VMware是老牌虚拟机软件,网上教程也很多。我之所以选用VirtualBox,主要是因为license的问题。 我手头只有一台MacBook pro, 不想话太多时间在软件license上折腾,所以选择了免费的VirtualBox. VirtualBox的安装过程乏善可陈,就是常规操作,不说了。

image.png
3. 虚拟机中安装CentOS
前面提到,我的主力计算机是一台MacBook Pro. 之前为方面,利用Parallel Desktop虚拟了一台Windows 出来,这里不提。
linux系统我选择了CentOS,首先从CentOS官网下载系统的ISO文件。在VirtualBox里新建一个虚拟机,类型选Linux,版本随便选一个就行了,因为里面没有看到有CentOS,不过随便选一个也没问题。 注意最好选一下文件夹,也就是虚拟机文件存放的位置,因为随着装的东西越来越多,虚拟机文件可能会越来越大。我的电脑硬盘都快撑满了,所以挂了个外接硬盘,把虚拟机文件放在了外接硬盘上,需要时插上用,虽然不方便,但也只好将就了。

其他参数可以都按默认,虚拟机创建成功后,点设置,切换到存储,在光驱那里选择下载的CentOS系统的ISO文件,这样虚拟机启动后就可以进入CentOS的安装了。

安装CentOS7 操作系统也不说了,都是图形化界面,没什么难度。
4. 网络环境配置遇到的坑
Linux安装成功后的网络设置这里需要说一下,我在这上面踩了不少坑。我希望我的网络环境是这样的。首先我们希望Linux虚拟机能够连接互联网,这样以后需要下载什么组件时能方便些。其次希望能用Host机器也就是MacBook中访问到Linux虚拟机,以便ssh登录上去。VirtualBox默认的小窗口实在很小,看着眼花,虽然也可以调大,但毕竟在宿主下操作更方便些,所以还是需要从MacBook上ssh过去。但是请注意,CentOS刚刚安装完成后是不能联网的,还需要做相关的设置才行。
4.1 Linux虚拟机连接互联网
虚拟机的网络设置默认可选用“网络地址转换NAT” ,虚拟机会创建一个NAT网络。
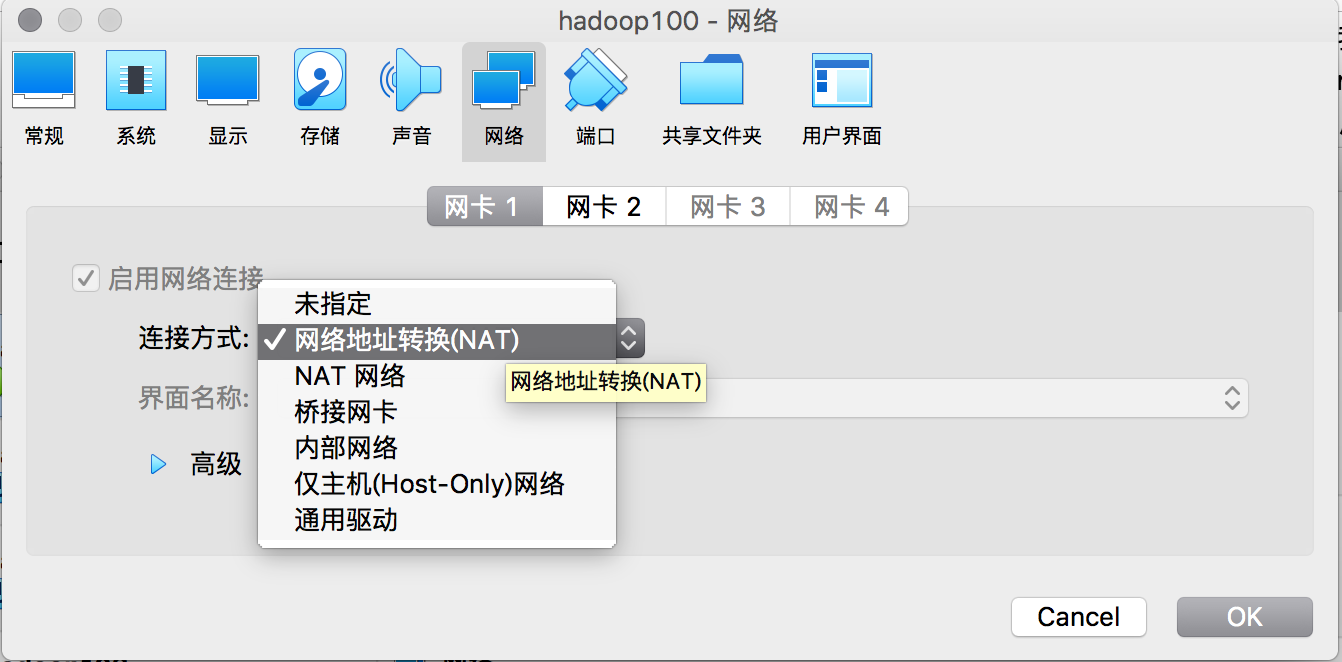
虚拟机安装后默认没有开启网络,所以不能联网,需要启动虚拟机,登录后更改网络配置。
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
把ONBOOT修改为yes,以便让linux 启动后即启动网络。 更改后按ESC,然后 :wq 退出保存。可以不用重启,通过下面的命令重启网络服务,以便使更改生效。
systemctl restart network

这时候可以通过命令 ``` ip addr``` 查看,你会看到网络已经有了一个IP地址,比如我的是 10.0.2.15。如图:

现在你如果 ping www.baidu.com ,应该发现已经能够联网了。
4.2 从宿主机Macbook访问Linux虚拟机
另外,但从主机Macbook还是不能ping通这个地址,就是说主机还不能访问虚拟机。要让主机MacBook和虚拟机linux互通,就需要让这两个机器在同一个网段里。 VirtualBox里的“管理”菜单下,打开“主机网络管理器”,创建一个,如图,可以看到创建了一个192.168.56.1的虚拟网卡。

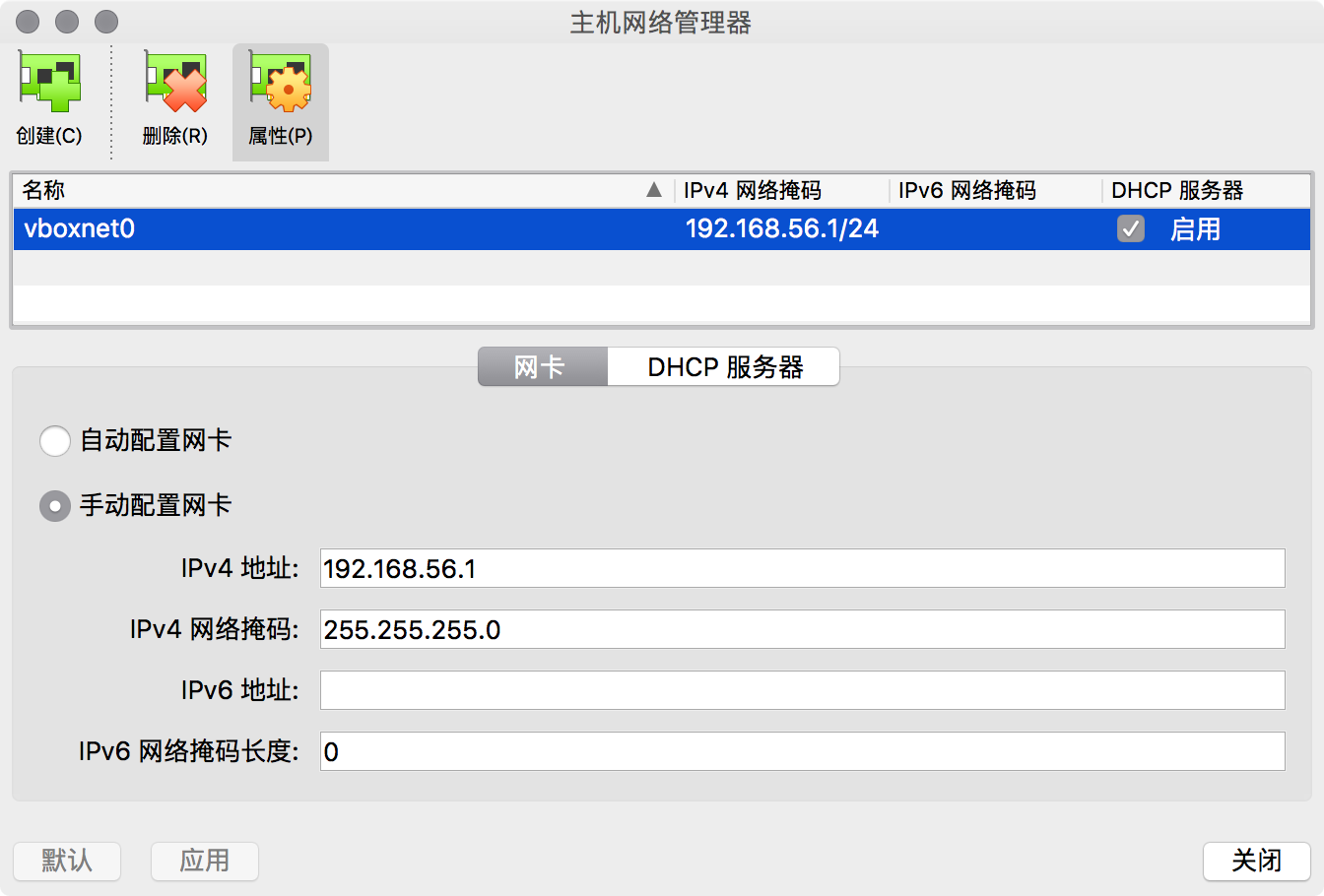
这时候如果你在MacBook的终端中使用ifconfig命令查看,你会发现,多出来一个vBoxnet0的网卡,ip地址就是192.168.56.1
danieldu@daniels-MacBook-Pro-857 ~ ifconfig
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
options=1203<RXCSUM,TXCSUM,TXSTATUS,SW_TIMESTAMP>
inet 127.0.0.1 netmask 0xff000000
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x1
nd6 options=201<PERFORMNUD,DAD>
gif0: flags=8010<POINTOPOINT,MULTICAST> mtu 1280
stf0: flags=0<> mtu 1280
en0: flags=8863<UP,broADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether ac:bc:32:c1:ed:dd
inet6 fe80::1c82:47a:64f:460f%en0 prefixlen 64 secured scopeid 0x4
inet 192.168.31.46 netmask 0xffffff00 broadcast 192.168.31.255
nd6 options=201<PERFORMNUD,DAD>
media: autoselect
status: active
....
vBoxnet0: flags=8943<UP,broADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> mtu 1500
ether 0a:00:27:00:00:00
inet 192.168.56.1 netmask 0xffffff00 broadcast 192.168.56.255
utun1: flags=8051<UP,POINTOPOINT,RUNNING,MULTICAST> mtu 1380
inet6 fe80::f655:9c6f:ca10:240e%utun1 prefixlen 64 scopeid 0xc
nd6 options=201<PERFORMNUD,DAD>...
然后需要VirtualBox中对应的虚拟机设置中,增加一个网卡2. 选择“仅主机(Host-Only)网络”,界面名称就是之前看到的vBoxnet0.

然后登录到虚拟机, 利用“ip addr” 命令查看,你会发现多出来一个网卡enp0s8。 从enp0s3 复制一个,然后编辑这个文件,这次更改为固定IP地址。
cp /etc/sysconfig/network-scripts/ifcfg-enp0s3 /etc/sysconfig/network-scripts/ifconfig-enp0s8

然后 重启网络 "systemctl restart network". 这时候就可以从主机Macbook 访问虚拟机了。
4.3关闭Linux防火墙
从上面的设置看到, 主机MacBook 的IP是 192.168.56.1, 虚拟机Linux设置了静态地址为 192.168.56.100. 现在已经在一个网段内了,应该内ping通。如果你ping不通,那很可能是防火墙的问题。 首先MacBook要关闭防火墙。
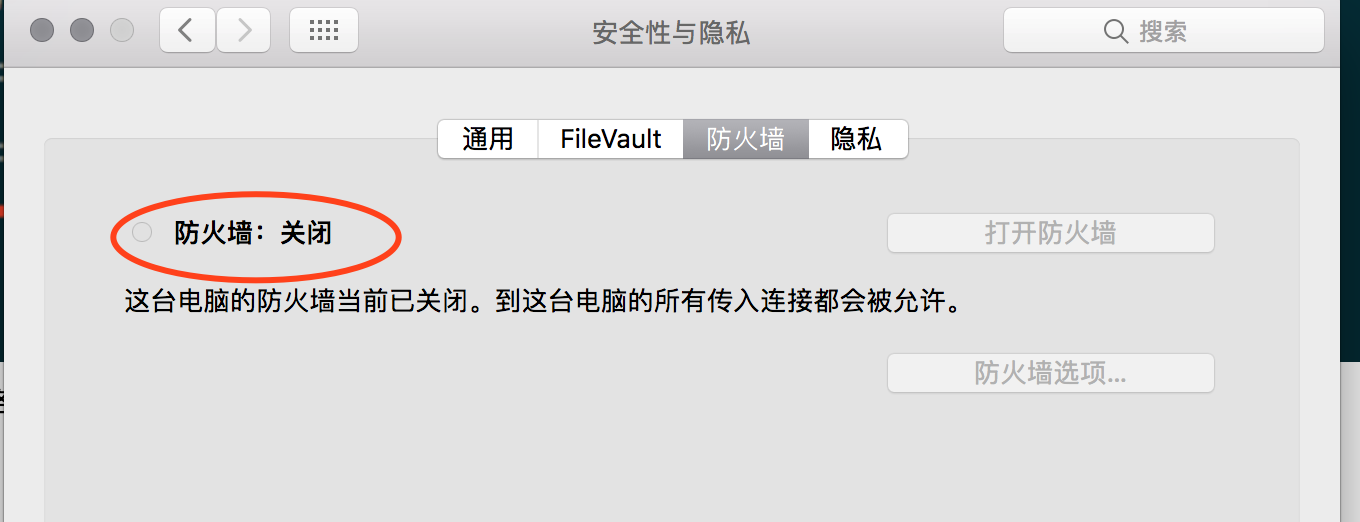
然后确保虚拟机Linux的也关闭防火墙,默认防火墙是开着的。
systemctl disable firewalld systemctl status firewalld

检查一下ssh服务,默认应该是开着的

你现在应该能从mac的终端通过ssh登录到linux了。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
