


2022年7月26日,Taier1.2版本正式发布!
本次版本发布更新功能:
新版本的使用文档已在社区中推送,大家可以随时下载查阅,欢迎大家体验新版本功能(喜欢我们的项目欢迎大家点个Star),体验地址:
Github:
https://github.com/DTStack/Taier
Gitee:
https://gitee.com/dtstack_dev_0/taier
社区:
https://dtstack.github.io/Taier/
Taier1.2版本介绍
Taier 是一个大数据分布式可视化的DAG任务调度系统,旨在降低ETL开发成本、提高大数据平台稳定性,大数据开发人员可以在 Taier 直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
Taier 脱胎于袋鼠云数栈,技术实现来源于数栈分布式调度引擎DAGScheduleX,是数栈产品的重要基础设施之一,负责大数据平台所有任务实例的调度运行。
2022年2月22日,Taier正式开源并发布1.0版本。
2022年5月8日,Taier1.1版本发布,更新对Flink的支持升级到Flink1.12,支持多种流类型任务等功能。
2022年7月26日,Taier1.2版本发布,本次发布重点新增工作流功能,实现配置化编排业务;租户简化绑定,不同类型计算组件无强制依赖等功能。
Taier1.2新增功能详解
1.新增工作流
通过可视化操作拖动任务节点到画板中,手动连接上下游任务组成依赖关系,形成一个DAG的工作流。同时支持任意类型的任务通过工作流拖拽的方式,直接实现配置化编排业务
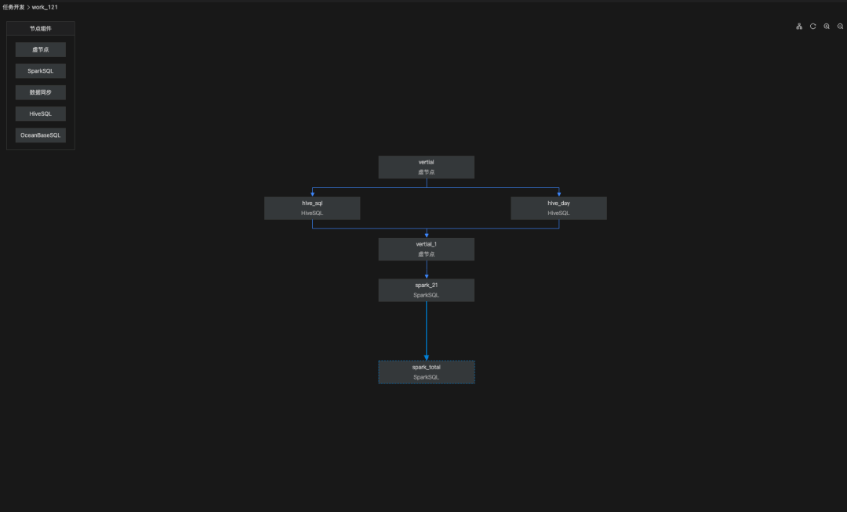
2.新增OceanBase sql
新增OceanBasesql 任务,支持OceanBasesql的任务调度和运维展示。
3.新增Flink jar任务
支持上传自定义开发的Flink jar任务,通过Taier提交运行和监控。
4. 数据同步、实时采集支持脏数据管理
数据同步、实时采集支持脏数据管理,可以配置脏数据数量限制和保存方式,可保存至数据库实时查看。
5.Hive UDF
6.控制台UI升级
控制台交互和页面全新升级,通过树形结构展示组件配置信息,同时支持扩展自定义组件进行配置。

7.租户绑定简化
集群和租户绑定简化,移除租户对接集群schema的强制绑定关系,不同类型计算组件无强制依赖;优化任务开发流程逻辑,支持自定义扩展任务类型。
未来规划
Taier自今年2月份开源以来,已更新迭代Taier1.1、Taier1.2两个版本,目前Taier1.3的版本已在规划中,在新版本中我们将着重解决以下几个问题:
-
适配开发者Window环境,支持Window环境下的任务提交流程
除了不断保持迭代更新外,Taier将持续保持每月一次开源技术直播,帮助Taier开发者们更好的使用产品,欢迎有兴趣的小伙伴们加入我们的交流社群(钉钉qun:30537511),一起交流Taier的技术问题及难点,和Taier一起共同进步!
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
