
@
树的基本概念
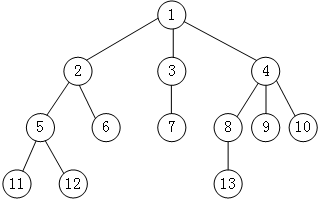
图1
树的结点
结点:使用树结构存储的每一个数据元素都被称为“结点”。例如,上图1中,数据元素 1 就是一个结点;
父结点(双亲结点)、子结点和兄弟结点:对于上图1中的结点 1,2,3,4 来说,1 是 2,4 结点的父结点(也称为“双亲结点”),而 2,4 都是 1 结点的子结点(也称“孩子结点”)。对于 2,4 来说,它们都有相同的父结点,所以它们互为兄弟结点。
树根结点(简称“根结点”):每一个非空树都有且只有一个被称为根的结点。上图1中,结点1就是整棵树的根结点。
叶子结点:如果结点没有任何子结点,那么此结点称为叶子结点(叶结点)。例如上图1中,结点 11,12,6,7,13,9,10都是这棵树的叶子结点。
子树和空树
子树:上图1中,整棵树的根结点为结点 1,而如果单看结点2,5,11,12 组成的部分来说,也是棵树,而且节点 2 为这棵树的根结点。所以称 2,12这几个结点组成的树为整棵树的子树;同样,结点 5,12 构成的也是一棵子树,根结点为5。
注意:单个结点也是一棵树,只不过根结点就是它本身。上图1中,结点 11,6 等都是树,且都是整棵树的子树。
知道了子树的概念后,树也可以这样定义:树是由根结点和若干棵子树构成的。
空树:如果集合本身为空,那么构成的树就被称为空树。空树中没有结点。
补充:在树结构中,对于具有同一个根结点的各个子树,相互之间不能有交集。例如,上图1中,除了根结点1,其余元素又各自构成了三个子树,根结点分别为 2,4,这三个子树相互之间没有相同的结点。如果有,就破坏了树的结构,不能算做是一棵树。
结点的度和层次
对于一个结点,拥有的子树数(结点有多少分支)称为结点的度(Degree)。例如,上图1中,根结点1下分出了 3 个子树,所以,结点 1 的度为 3。
一棵树的度是树内各结点的度的最大值。上图1表示的树中,各个结点的度的最大值为 3,所以,整棵树的度的值是 3。
结点的层次:从一棵树的树根开始,树根所在层为第一层,根的孩子结点所在的层为第二层,依次类推。对于上图1来说,1 结点在第一层,2,4 为第二层,5,8,10在第三层,11,13在第四层。
一棵树的深度(高度) 是树中结点所在的最大的层次。上图1树的深度为 4。
如果两个结点的父结点虽不相同,但是它们的父结点处在同一层次上,那么这两个结点互为堂兄弟。例如,上图1中,结点5,10 的父结点都在第二层,所以之间为堂兄弟的关系。
有序树和无序树
如果树中结点的子树从左到右看,谁在左边,谁在右边,是有规定的,这棵树称为有序树;反之称为无序树。
在有序树中,一个结点最左边的子树称为"第一个孩子",最右边的称为"最后一个孩子"。
拿上图1来说,如果是其本身是一棵有序树,则以结点 2 为根结点的子树为整棵树的第一个孩子,以结点 4 为根结点的子树为整棵树的最后一个孩子。
森林
由 m(m >= 0)个互不相交的树组成的集合被称为森林。上图1中,分别以2,4为根结点的三棵子树就可以称为森林。
前面讲到,树可以理解为是由根结点和若干子树构成的,而这若干子树本身是一个森林,所以,树还可以理解为是由根结点和森林组成的。用一个式子表示为:Tree =(root,F)
其中,root 表示树的根结点,F 表示由 m(m >= 0)棵树组成的森林。
二叉树的性质
经过前人的总结,二叉树具有以下几个性质:
- 二叉树中,第 i 层最多有 2i-1 个结点。
- 如果二叉树的深度为 K,那么此二叉树最多有 2K-1 个结点。
- 二叉树中,终端结点数(叶子结点数)为 n0,度为 2 的结点数为 n2,则 n0=n2+1。
- 二叉树还可以继续分类,衍生出满二叉树和完全二叉树。
满二叉树
如果二叉树中除了叶子结点,每个结点的度都为 2,则此二叉树称为满二叉树。
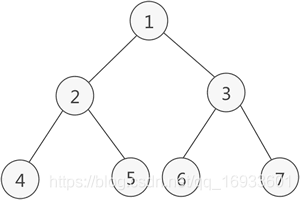
图2
如图2 所示就是一棵满二叉树。
- 满二叉树除了满足普通二叉树的性质,还具有以下性质:
- 满二叉树中第 i 层的节点数为 2n-1 个。
- 深度为 k 的满二叉树必有 2k-1 个节点 ,叶子数为 2k-1。
- 满二叉树中不存在度为 1 的节点,每一个分支点中都两棵深度相同的子树,且叶子节点都在最底层。
- 具有 n 个节点的满二叉树的深度为 log2(n+1)。
完全二叉树
如果二叉树中除去最后一层节点为满二叉树,且最后一层的结点依次从左到右分布,则此二叉树被称为完全二叉树。
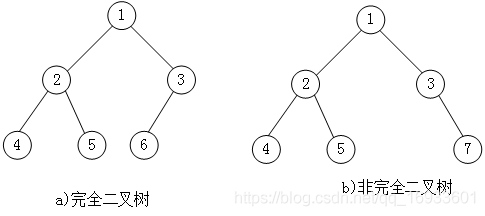
图3
如上图3a 所示是一棵完全二叉树,如上图3b中由于最后一层的节点没有按照从左向右分布,因此只能算作是普通的二叉树。
完全二叉树除了具有普通二叉树的性质,它自身也具有一些独特的性质,比如说,n 个结点的完全二叉树的深度为 ⌊log2n⌋+1。
[log2n]表示取小于 log2n 的最大整数。例如,[log24] = 2,而 [log25⌋]结果也是 2。
对于任意一个完全二叉树来说,如果将含有的结点按照层次从左到右依次标号(图3),对于任意一个结点 i ,完全二叉树还有以下几个结论成立:
- 当 i>1 时,父亲结点为结点 [i/2] 。(i=1 时,表示的是根结点,无父亲结点)
- 如果 2 * i>n(总结点的个数) ,则结点 i 肯定没有左孩子(为叶子结点);否则其左孩子是结点 2*i 。
- 如果 2 * i+1>n ,则结点 i 肯定没有右孩子;否则右孩子是结点 2*i+1 。
二叉树的顺序存储
二叉树的顺序存储,指的是使用顺序表(数组)存储二叉树。需要注意的是,顺序存储只适用于完全二叉树。换句话说,只有完全二叉树才可以使用顺序表存储。因此,如果我们想顺序存储普通二叉树,需要提前将普通二叉树转化为完全二叉树。
有读者会说,满二叉树也可以使用顺序存储。要知道,满二叉树也是完全二叉树,因为它满足完全二叉树的所有特征。
普通二叉树转完全二叉树的方法很简单,只需给二叉树额外添加一些节点,将其"拼凑"成完全二叉树即可。如图4所示:
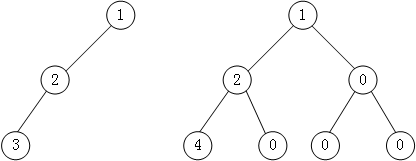
图4
下图中,左侧是普通二叉树,右侧是转化后的完全(满)二叉树。
解决了二叉树的转化问题,接下来学习如何顺序存储完全(满)二叉树。
完全二叉树的顺序存储,仅需从根节点开始,按照层次依次将树中节点存储到数组即可。

图5
例如,存储图5如下 所示的完全二叉树,其存储状态如图 6 所示:

图6
同样,存储由普通二叉树转化来的完全二叉树也是如此。例如,图 4 中普通二叉树的数组存储状态如图7 所示:
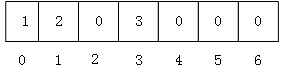
图7
由此,我们就实现了完全二叉树的顺序存储。
不仅如此,从顺序表中还原完全二叉树也很简单。我们知道,完全二叉树具有这样的性质,将树中节点按照层次并从左到右依次标号(1,...),若节点 i 有左右孩子,则其左孩子节点为 2i,右孩子节点为 2i+1。此性质可用于还原数组中存储的完全二叉树,也就是实现由图6到图5、由图 7到图4的转变。
二叉树的链式存储
二叉树并不适合用数组存储,因为并不是每个二叉树都是完全二叉树,普通二叉树使用顺序表存储或多或多会存在空间浪费的现象。
接下来我们介绍二叉树的链式存储结构。
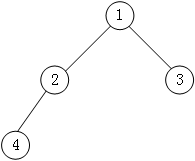
图8
如图 8 所示,此为一棵普通的二叉树,若将其采用链式存储,则只需从树的根节点开始,将各个节点及其左右孩子使用链表存储即可。因此,图8对应的链式存储结构如图9所示:
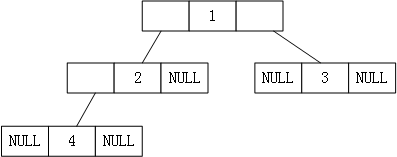
图9
由图9可知,采用链式存储二叉树时,其节点结构由 3 部分构成(如图10 所示):
- 指向左孩子节点的指针(Lchild);
- 节点存储的数据(data);
- 指向右孩子节点的指针(Rchild);

图10
链式存储代码实现:
/*
* @Description: 二叉树的链式存储
* @Version: V1.0
* @Autor: Carlos
* @Date: 2020-05-29 16:37:38
* @LastEditors: Carlos
* @LastEditTime: 2020-05-29 16:45:13
*/
#include <stdio.h>
#include <stdlib.h>
typedef struct BitNode
{
int data;
struct BitNode *lchild,*rchild;
}BitNode,*BitTree;
void CreateBiTree(BitTree *T){
*T=(BitNode*)malloc(sizeof(BitNode));
//根节点
(*T)->data=1;
(*T)->lchild=(BitNode*)malloc(sizeof(BitNode));
//1节点的左孩子2
(*T)->lchild->data=2;
(*T)->rchild=(BitNode*)malloc(sizeof(BitNode));
//1节点的右孩子3
(*T)->rchild->data=3;
(*T)->rchild->lchild=NULL;
(*T)->rchild->rchild=NULL;
(*T)->lchild->lchild=(BitNode*)malloc(sizeof(BitNode));
//2节点的左孩子
(*T)->lchild->lchild->data=4;
(*T)->lchild->rchild=NULL;
(*T)->lchild->lchild->lchild=NULL;
(*T)->lchild->lchild->rchild=NULL;
}
int main() {
BitTree Tree;
CreateBiTree(&Tree);
printf("%d",Tree->lchild->lchild->data);
return 0;
}
文中代码均已测试,有任何意见或者建议均可联系我。欢迎学习交流!
如果觉得写的不错,请点个赞再走,谢谢!
有任何问题,均可通过公告中的二维码联系我
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。