
上帝的磨盘转动很慢,但是却磨得很细。 ——毛姆
本文已经收录至我的GitHub,欢迎大家踊跃star 和 issues。
https://github.com/midou-tech/articles
数据结构的基本概念
数据结构
相互之间存在一种或多种特定关系的数据元素的集合,我总结一下就是描述数据关系的一种载体。
数据结构包括逻辑结构和存储结构两个层次的描述。
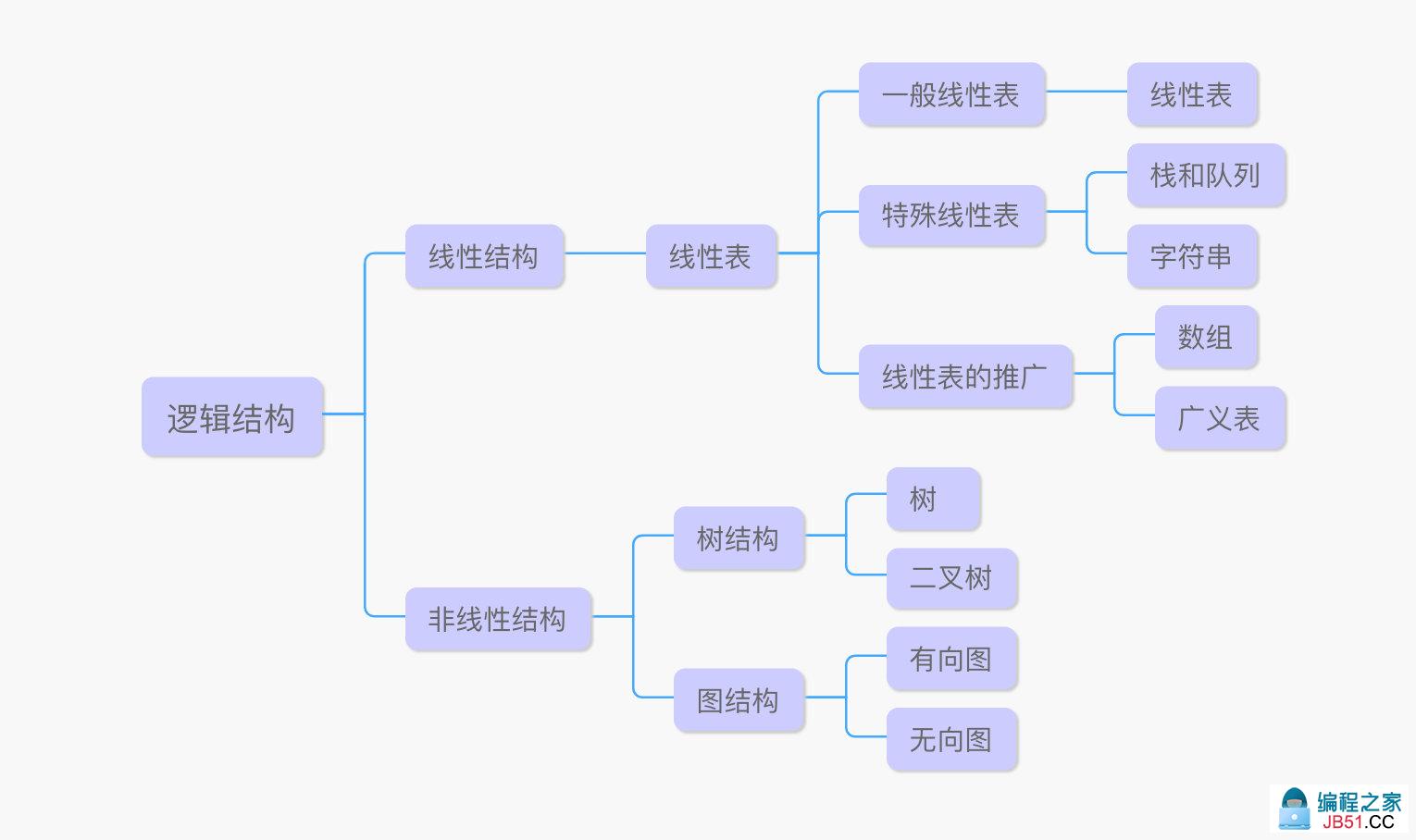
逻辑结构
描述数据逻辑关系的一种方式,与数据的存储无关。逻辑结构中数据元素之间的关系主要分为四种:集合结构、线性结构、树结构、图结构。所有的数据结构在逻辑上都可以用这四种中的一种。
存储结构
数据和数据元素逻辑关系的存储对象,也被称为物理结构。通常逻辑结构包含两种,链式存储和顺序存储。顺序存储 数据元素存储在一块连续的内存空间上,例如数组,就是一块连续的空间。链式存储 数据存储不一定在一块连续的内存空间上,例如单链表。
数据类型
是一组值的集合和定义在这个集合上的操作的总称。
抽象数据类型
由用户定义的表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称,具体包括三部分,数据对象、数据对象上关系的集合以及对数据对象基本操作的集合。
抽象数据类型有自己的定义格式:
1ADT 抽象数据对象名 {
2 数据对象:(数据对象的定义)
3 数据关系:(数据关系的定义)
4 基本操作:(基本操作的定义)
5}
算法与数据结构
算法 解决一类问题而规定的一个有限长操作序列。
算法必须满足几个特性才能称之为算法:
- 有穷性:算法执行必须是在有限的步数之后完成,执行每一步也是有限的时间。简单来说就是执行一个算法时间是有限,总不能执行一个算法和时间同步没有尽头吧。
- 确定性:算法每种执行操作都是确定的,执行结果也是确定的,没有二义性的。算法的执行者和阅读者都明确其算法含义和如何执行。
- 可行性:这个理解起来很简单,算法被设计出来是可以被计算机完成的。
- 输入&输出:一个算法一定是有输入和输出的,输入是算法执行的条件,输出是算法产生的结果。
算法优劣的评价标准
评价算法优劣的主要从以下几个方面考虑:
- 正确性:在合理的数据输入下,能够在有限的运行时间内得到正确的结果。
- 可读性:包括两个方面一个是研究算法的人们易与读写,另一个是执行算法的机器可以执行。
- 健壮性:对于非法输入,好的算法是会做相应的处理而不是产生一些奇怪的结果。
- 高效性:高效性包括时间和空间两个方面,在保证算法结果正确的情况下,时间上花费的越少,空间上花费的越少,算法就很高效。现实中往往是二者不可兼得,很多算法都是时间上优越,空间上浪费,还有很多算法反正。
时间复杂度
用算法中的"基本语句" 的执行次数来度量算法的工作量。正常状态下一般用循环或者递归的运行次数。
在某些算法中算法的时间复杂度会根据算法的初始状态决定,这种时候需要计算出算法的最好时间复杂度、最坏时间复杂度和平均时间复杂度。比如常见的排序算法就有最好最坏和平均时间复杂度。
空间复杂度
算法在运行过程中占用的辅助空间大小,被称作该算法的空间复杂度。
时间复杂度和空间复杂度都是用大写的 "O" 表示。对于一个算法,其时间复杂度和空间复杂度往往是相互影响的,当追求一个较好的时间复杂度时, 可能会导致占用较多的存储空间, 即可能会使空间复杂度的性能变差, 反之亦然。不过, 通常情况下, 鉴于运算空间较为充足, 人们都以算法的时间复杂度作为算法优劣的衡址指标。
自己在写算法时一定要可以去留意算法的效率问题,不然你写出来的算法虽然满足可行性、确定性、健壮性,也会是一个很烂的算法。时间复杂度是我们日常编程设计考虑最多的。
在学习算法效率的时候一般会把O(3N)≈O(N),N的常数倍都直接约等于O(N)。这也是约等于,不是完全相等。实际编程设计时特别是在一些效率要求较高的程序设计一定要考虑进去,不能约等于。在高并发的请求下,O(3N)和O(N)是有着天壤之别的。
我在工作中遇到的一个实例,差点背了事故。一个高并发的场景下(qps在5k左右),我写了一个O(3N)的程序,测试时逻辑没问题,结果没问题,没有对该场景进行高并发压测,就上线了。上线之后不到十分钟我收到短信报警,多台机器CPU打满了,内存也在飙升(32C—124G的服务器)。此时的我吓坏了,意识到我刚刚发布了,肯定和我发布有关。保证线上优先,立马把刚上线的服务下掉,别影响其他业务正常。下掉我的服务,CPU资源报警解除了。
经过一番review代码,各种测试,最终定位到两个问题。一个是我代码里面有一处内存泄漏导致内存飙升了,还有一处就是时间复杂度的问题。错误的把O(3N)=O(N)的算法上线了。把算法优化为O(N)之后,经过一番压力测试完全没问题。这次事件对我一个很大的启示是,高并发的场景下,O(3N)≠O(N),一定不能等于。
高并发场景下算法的效率尤为重要,此时时间和空间的平衡关系一定要充分考虑。
总结
概念性的东西一般在实际工作中不会去过多纠结,很多工作很久的同学完全不记得这些概念的文字却依然可以轻松愉快的完成相应知识的工作。是的,不拘泥于概念,却熟练运用概念对应的知识是我们的目的。这样说并不是概念不重要,完全不需要看概念。概念是认识一个事物的开始,他表示一个事物是什么,后面的做什么,为什么,都是建立在是什么的基础上的,所以概念一定要理解,而不是背书。
在学校的同学会养成一种很不好的习惯,就是必须去记这些概念。为什么呢?因为考试会考。是的,我在大学的时候也会去记这些概念的文字应付考试。比如下面这些考题就曾经出现在考卷中
-
简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、
抽象数据类型。
不要慌,理解记忆这些概念。既能应付考试,又能很好的理解知识。你需要记住考试好不代表你对知识掌握的好,掌握是指的能把这些知识运用在实际工作和生活应用中。
下一篇文章会写数据结构一种非常重要的数据结构——线性表。记得关注我,精彩内容不错过喔。
微信搜索 龙跃十二 即可订阅,微信更新会早于博客喔。

版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。