
分而治之(又称D&C)
书中举了一个例子,假设你是农场主,有一块土地,如图所示:
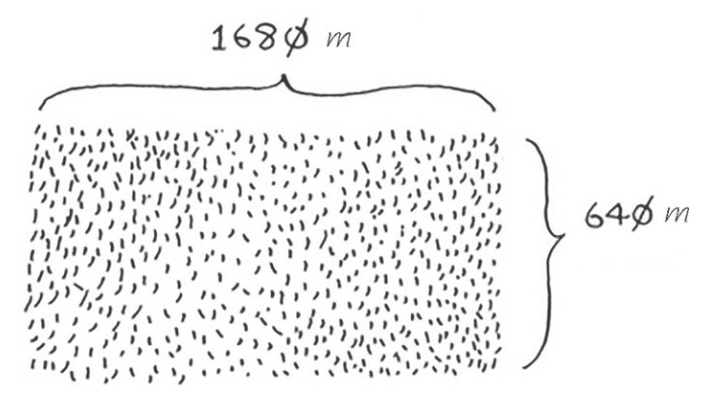
你要将这块地均匀分成方块,且分出的方块要尽可能大。
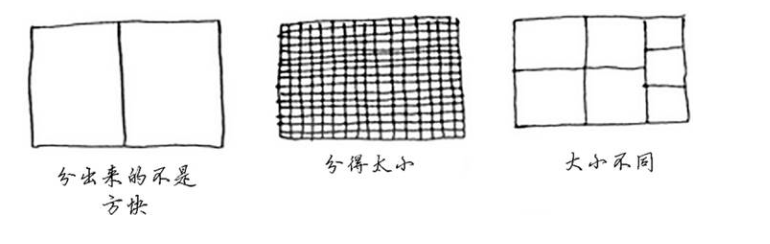
从图上看,显然是不符合预期结果的。
那么如何将一块地均匀分成方块,并确保分出的方块是最大的呢?使用D&C策略。
(1)D&C算法是递归的;
(2)使用D&C解决问题的过程包括两个步骤:
a.找出基线条件,这种条件必须尽可能简单;
b.不断将问题分解(或者说缩小规模),直到符合基线条件;
就如何保证分出的方块是最大的呢?《算法图解》中的快速排序一章提到了欧几里得算法。
什么是欧几里得算法?
欧几里得算法又称辗转相除法,是指用于计算两个正整数a,b的最大公约数。
应用领域有数学和计算机两个方面。
举个代码例子说一下欧几里得算法:
package cn.pratice.simple; public class Euclid { static void main(String[] args) { int m = 63; int n = 18int remainer = 0while(n!=) { remainer = m % n; m = n; n = remainer; } System.out.println(m); } }
最终的结果是9,正好63和18的最大公因数也是9.
其中也体现着分而治之的思想。记住,分而治之并非可用于解决问题的算法而是一种解决问题的思路。
再举个例子说明,如图所示:
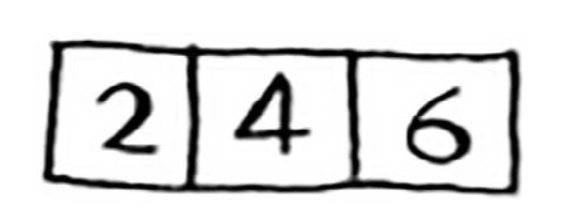
需要将这些数字相加,并返回结果,使用循环很容易完成这种任务,以Java为例:
int []num = new int[] {2,4,1)">6}; int total = for (int i = 0; i < num.length; i++) { total += num[i]; } System..println(total); } }
快速排序
快速排序是一种常用的排序算法,比选择排序快的多。
代码示例如下(快速排序):
QuickSort { //声明静态的 getMiddle() 方法,该方法需要返回一个 int 类型的参数值,在该方法中传入 3 个参数 int getMiddle(int[] list,int low,1)">int high) { int tmp = list[low];数组的第一个值作为中轴(分界点或关键数据) while(low<high) { while(low<high && list[high]>tmp) { high--; } list[low] = list[high];比中轴小的记录移到低端 while(low<high&&list[low]<tmp) { low++; } list[high]=list[low];比中轴大的记录移到高端 } list[low] = tmp;中轴记录到尾 return low; } 创建静态的 unckSort() 方法,在该方法中判断 low 参数是否小于 high 参数,如果是则调用 getMiddle() 方法,将数组一分为二,并且调用自身的方法进行递归排序 void unckSort(if(low<int middle = getMiddle(list,low,high);将list数组一分为二 unckSort(list,middle-1);对低字表进行递归排序 unckSort(list,middle+1,1)">对高字表进行递归排序 } } 声明静态的 quick() 方法,在该方法中判断传入的数组是否为空,如果不为空,则调用 unckSort() 方法进行排序 void quick([] str) { if(str.length>) { 查看数组是否为空 unckSort(str,1)">0,str.length-1); } } 测试 main(String[] args) { int[] number = {13,1)">15,1)">24,1)">99,1)">14,1)">11,1)">3}; System.out.println("排序前:"); i : number) { System.out.print(i+" ); } quick(number); System.\r排序后:); } } }
此示例来自Java数组排序:Java快速排序(Quicksort)法
没有什么比代码示例来的直接痛快。
再谈大O表示法
快速排序的独特之处在于,其速度取决于选择的基准值。
常见的大O运行时间图,如下:

上述图表中的时间是基于每秒执行10次操作计算得到的。这些数据并不准确,这里提供它们只是想让你对这些运行时间的差别有大致认识。实际上,计算机每秒执行的操作远远不止10次。 在该节中,作者说合并排序比选择排序要快的多。合并排序,用数学公式表示为O(n log n),而选择排序为O(n的2次方)。
合并代码排序例子如下:
package cn.pratice.simple; import java.util.Arrays; MergeSort { private void mergeSort([] original) { if (original == nullthrow new NullPointerException(The array can not be null !!!); } int length = original.length; if (length > int middle = length / 2; int partitionA[] = Arrays.copyOfRange(original,middle); 拆分问题规模 int partitionB[] = Arrays.copyOfRange(original,middle,length); 递归调用 mergeSort(partitionA); mergeSort(partitionB); sort(partitionA,partitionB,original); } } void sort(int[] partitionA,1)">int[] partitionB,1)">int j = int k = while (i < partitionA.length && j < partitionB.length) { if (partitionA[i] <= partitionB[j]) { original[k] = partitionA[i]; i++; } else { original[k] = partitionB[j]; j++; } k++; } if (i == partitionA.length) { while (k < original.length) { original[k] = partitionB[j]; k++; j++; } } else if (j == partitionA[i]; k++; i++; } } } void print([] array) { if (array == ); } StringBuilder sb = new StringBuilder([ element : array) { sb.append(element + ,); } sb.replace(sb.length() - ]); System..println(sb.toString()); } long startTime = System.currentTimeMillis(); 获取开始时间 int original[] = int[] { }; 0; i < original.length; i++) { System.out.print(original[i]+); } mergeSort(original); print(original); long endTime = System.currentTimeMillis(); 获取结束时间 System.程序运行时间:" + (endTime - startTime) + ms"); 输出程序运行时间 } }
此示例来自
java实现合并排序算法
比较快速排序与合并排序
还是以上面的代码例子为例:
快速排序代码例子,如下:
int[] number = { 3,1)">32,1)">4321,1)">432,1)">153,1)">23,1)">42,1)">12,1)">34,1)">312,1)">43,1)">3214,1)">43214,1)">2432,1)">4532,1)">1234}; quick(number); } }
输出结果,如图:
半天看不到输出结果,而程序仍在运行中。如果将数组中的元素还原为原来那几个,则很快看到结果。
合并代码例子,如下:
}
}
输出结果,如图:

通过两者对比,我们很容易得出合并排序比快速排序快。
参考这个合并排序和快速排序执行时间比较
作者通过实验得出一个结论:当数据量较小的时候,快速排序比合并排序运行时间要短,运行时间短就表示快,但是当数据量大的时候,合并排序比快速排序运行时间要短。
由此通过我上述的代码实验和该文章作者试验,可证实这个结论。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。