
栈
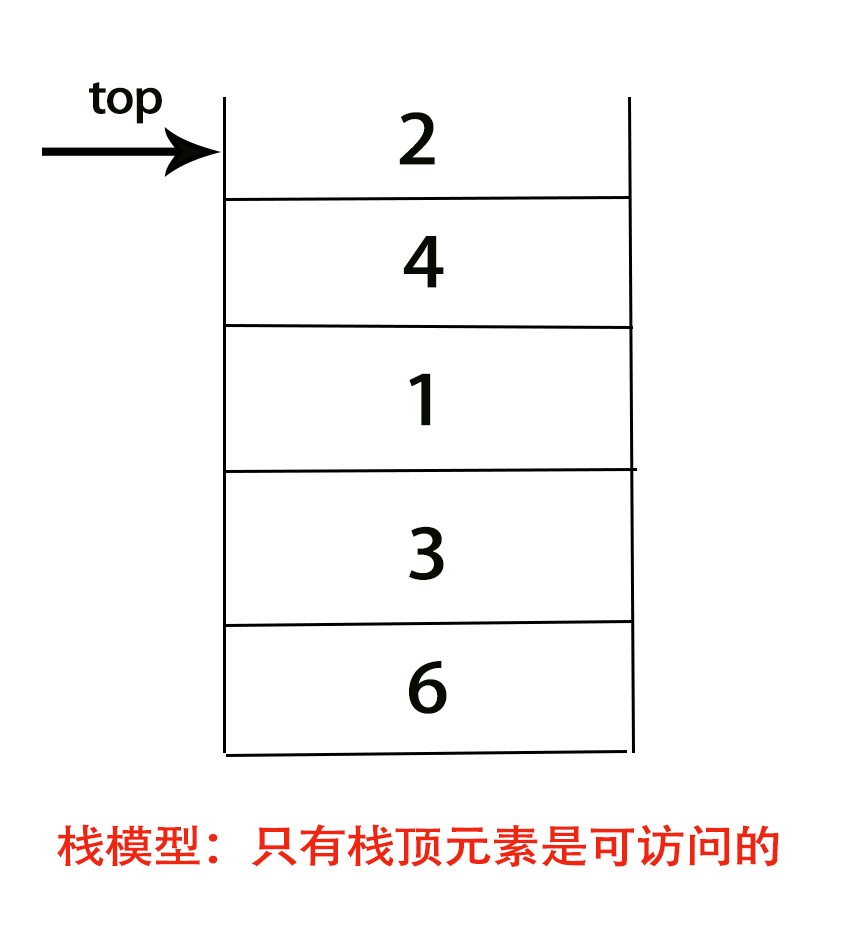
栈模型
栈(stack)是限制对元素的插入(push)和删除(pop)只能在一个位置上进行的表,该位置是表的末端,叫做栈的栈顶(top)。
栈的基本操作只有两种,压入栈(push)和弹出栈顶(pop),且只能作用于栈顶。(只有栈顶元素是可访问的

你可以把栈结构理解成一个底部封闭,顶部打开的桶。最先进去的元素一定是最后才能取出,最晚进去的元素一定是最先取出。
因此栈又叫做LIFO(后进先出,Last In First Out)表。

栈的优势
栈的操作是常数时间的,而且是以非常快的常数时间。在某些机器上,push和pop都可以写成一条机器指令,现代计算机把栈操作作为它指令的一部分。因此栈是在计算机科学中继数组之后最基本的数据结构。
栈的实现
栈的实现分为数组实现和链表实现。
-
链表实现
这里我们使用单链表来实现,定义一个first指针指向栈顶,栈的链表实现实际上是简化了单链表实现,具体实现看以下代码。
1public class StackImplementByLinklist<AnyType> {
2 public Node<AnyType> first;
3 int size;
4 //内部类定义node
5 Node<AnyType>{
6 AnyType data;
7 Node<AnyType> next;
8 }
9 //初始化
10 public void stack(){
11 first=null;
12 size=0;
13 }
14
15 push(AnyType a){
16 Node oldNode=first;
17 first=new Node();
18 first.data=a;
19 first.next=oldNode;
20 size++;
21 }
22
23 public AnyType pop24 AnyType a=first.data;
25 first=first.next;
26 size--;
27 return a;
28 }
29
30 public boolean isEmpty31 return size==32 }
33
34 int size35 return size;
36 }
37}
-
数组实现
相比于链表实现,数组实现栈更加的常用。因为数组操作的常数时间极短,而且实现起来更加简单。
StackImplementByArray<AnyType> {
2 AnyType[] arr;
4 (int capacity){
5 arr=(AnyType[])new Object[capacity];
6 size= 7 }
8 9 if(size==arr.length){
10 changeArray(2*size+1);
11 }
12 arr[size]=a;
13 size++;
14 }
16 if(size==0){
17 System.out.println("栈顶为空");
18 System.exit(0);
19 }
20 AnyType a=arr[size-1];
21 arr[size-1]=null;
22 size--;
23 24 }
25 26 27 }
28 29 30 }
31
32 //由于数组大小是要先确定的,因此当数组满了后要扩大数组容量
33 changeArrayint newCapacity){
34 AnyType[] newArr=(AnyType[])new Object[newCapacity];
for(int i=0;i<arr.length;i++){
36 newArr[i]=arr[i];
37 }
38 arr=newArr;
39 }
40
41}
栈的应用
- 平衡符号的检测
编译器检查程序符号的语法错误,常常就是通过栈来实现的。
在编程时,我们经常会用到“ ( ),[ ],{ }," " ”这些符号,当这些符号不是配对出现的,编译器就会报错,编译就无法通过。
那么,编译器是怎么知道这些符号有没有配对出现的呢?它通常是这么处理的。
当遇到左符号,如“( [ { " ”这些,就把它压入一个准备好的栈;否则就弹出栈顶,检测当前符号是否与栈顶元素配对。一旦不能配对,直接退出报错。
- 算术表达式的求值
队列
队列模型
wiki: 队列,又称为伫列(queue),是先进先出(FIFO,First-In-First-Out)的线性表。在具体应用中通常用链表或者数组来实现。队列只允许在后端(称为rear)进行插入操作,在前端(称为front)进行删除操作。队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加。
队列模型就相当于我们日常生活的排队,在队伍的后面入队,在队伍的前端出队。

多种队列
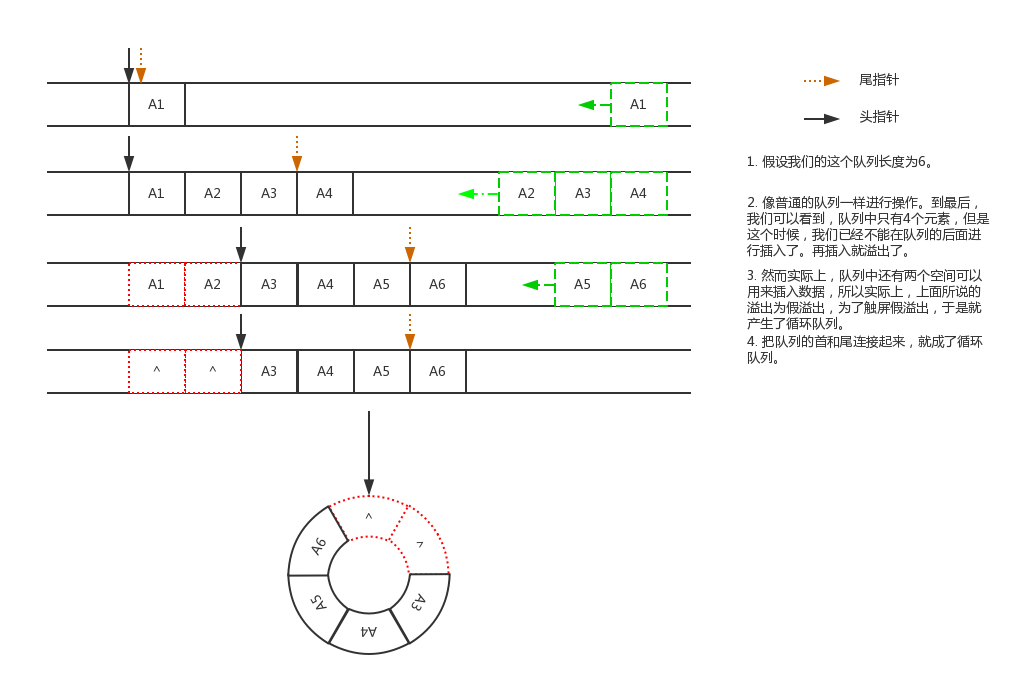
队列一般分为普通的数组队列,链表队列和循环队列。
链表队列:长度一般是无限的,一般不存在溢出的可能性,用完就销毁,不会浪费内存空间。
普通的数组队列:长度一般是有限的,即数组长度。由于元素出队后其位置的内存空间并不会释放,因此会浪费大量的内存空间。

循环队列:特殊的数组队列,由于普通的数组的队列会浪费大量的内存空间,因此出现了循环队列。当循环队列的队尾指针到达数组末尾后,会重新回到数组起始位置,实现了对内存的重复利用。
队列的实现
1.链表队列
QueueImplementByLinkList<AnyType> {
2 Node first;//队首
3 Node last;//队尾
4 Node{
7 Node next;
8 public Node(AnyType data,Node next){
9 this.data=data;
10 this.next=next;
12 }
13
14 //初始化队列
initqueue16 first=new Node(null,null);
17 last=first;
18 size=19 }
20
21 //入队
22 enqueue24 last.data=a;
25 size++;
26 return;
27 }
28 Node oldlast=last;
29 last=new Node(a,1); word-spacing: 0; word-wrap: inherit !important; word-break: inherit !important">30 oldlast.next=last;
31 size++;
34 //出队
35 dequeue36 37 System.out.print("队列为空");
38 System.exit(39 }
40 AnyType a=first.data;
41 first=first.next;
42 size--;
43 44 }
45 boolean 46 47 }
48 49 50 }
51}
2.数组队列
QueueImplementByArray<AnyType> {
int first;
int last;
6 7 ininqueue 8 arr=(AnyType[]) 9 first=10 last=11 size=13 14 15 changeArray(16 }
17 arr[last++]=a;
18 size++;
20 21 22 System.out.println(23 System.24 }
25 AnyType a=arr[first++];
26 arr[first27 size--;
28 29 }
31 AnyType[] newArr=(AnyType[])32 33 newArr[i]=arr[i];
34 }
35 arr=newArr;
37 38 40 41 42 }
43
44}
- 循环队列
CycleQueue {
int[] arr;
int start;int end;int size=initqueue(int size){
8 arr=new int[size];
9 size=10 start=11 end=enqueue(int num){
if(size>arr.length){
17 System.out.println("队列已满");
18 20 if(end==arr.length){
21 end=22 }
23 arr[end++]=num;
24 size++;
25 }
26
27 dequeue(){
30 System.31 System.exit(32 }
33 if(start==arr.length){
34 start=35 }
36 size--;
37 return arr[start++];
38 }
39
isEmpty(43 size(44 45 }
46}
一点点总结
栈和队列是基本的数据结构,是对数组和链表的重新封装和扩展。由于它们的特性和执行速度,栈和队列被广泛的使用。
最后,不要为了使用数据结构而使用使用数据结构,要区分各种数据结构的使用场景,灵活地运用数据结构,可以事半功倍。
如果这篇文章对你有帮助的话,左下角给个推荐鸭,这个对我真的很重要?!
原文地址:https://www.cnblogs.com/sang-bit
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。