
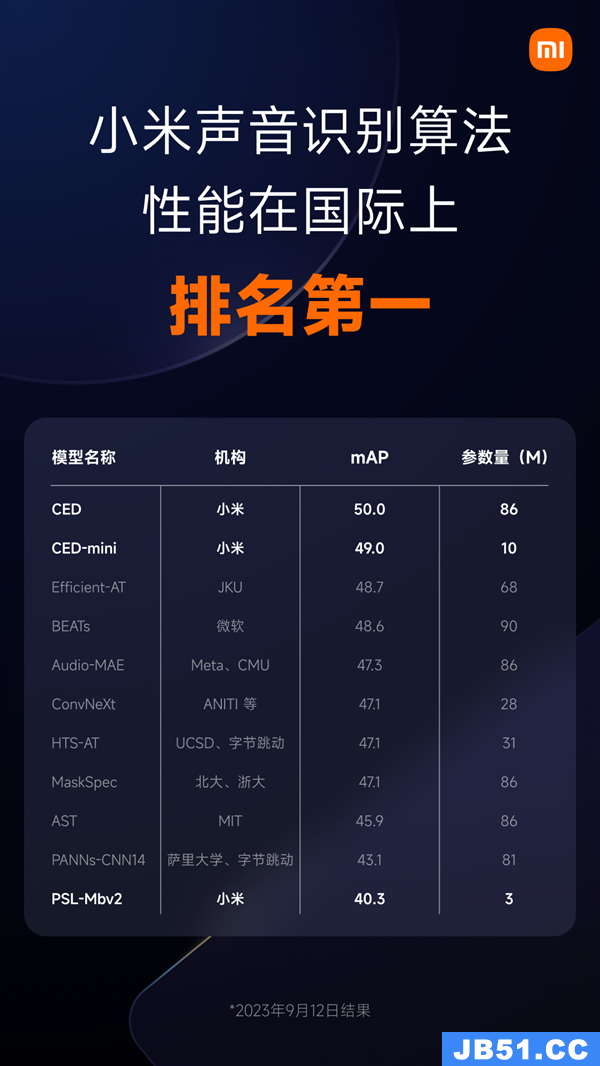
小米自研声音识别算法在音频标记(Audio Tagging)任务中取得重要进展。
以公开数据集AudioSet-2M的音频数据作为训练集的音频标记模型,首次突破50 mAP的分数,此项突破标志着小米声音识别算法已在国际上性能排名第一。

据了解,Google将AudioSet数据集分为三个子集,前两个子集用于训练,被合并称为 “AudioSet-2M”。正是在这个合并后的训练集中,小米的声音识别算法模型首次在业界突破了50 mAP,刷新了音频标记技术指标,成为截至目前性能最好的模型。
此外,小米还发布了一个Mini版模型,适合资源受限的场景。该模型的参数量被压缩到了原模型的约九分之一,远小于其他机构的模型,但性能却优于其他所有机构。

这项技术的突破意味着小米的声音识别算法能力再次精进,小米的众多智能硬件设备应用此项技术后,可以更敏锐地捕捉和识别环境声音,大幅提升硬件的智能化程度,从而为用户创造更加便捷的智能生活体验。
小米此次精进后的声音识别算法,具有极高的应用价值。它能够广泛应用于小米的智能设备中,大幅提升用户的智能生活体验。具体来说,音频标记算法能够识别广泛的环境声音,比如婴儿的啼哭声、动物叫声、汽车引擎声、爆炸声、烟雾警报、门铃声、水流声等,并让环境中的声音以文字等模态表达。
此外,这项算法技术还广泛应用于小米机器人的研发中,大幅提升了机器人的感知能力。人形机器人CyberOne可以识别85种环境声音,能够通过听觉感知6类、45种人类情绪。而小米第二代仿生四足机器人CyberDog 2则可以识别38种环境声音,实现更强大的动态响应能力。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。