
小编给大家分享一下Apache Phoenix for CDH的示例分析,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
Cloudera正式宣布在CDH中支持Apache Phoenix,同时也会集成到未来的Cloudera Data Platform中。
Cloudera的CDH发行版其实一直包含Apache HBase服务,它为希望利用大数据功能的客户的操作型应用程序提供了一个灵活的NoSQL数据库。这些应用程序已经发展成为重要且核心的应用程序,可以推动收入和利润的增长。这些应用程序包括面向客户的应用程序,电子商务平台,银行的风控和反欺诈,或为应用程序提供AI/ML模型,以及根据实际结果进一步加强训练。
但是,对于许多客户来说,使用HBase其实很抗拒,因为:
1.HBase的数据模型是一张大宽表,支持上百万个column,但却不支持join
2.使用Java APIs而不是ANSI SQL
他们要求能够使用类似于Oracle或MySQL提供的更传统的schema设计,并且愿意在灵活性方面做出一些权衡,例如:
1.他们愿意使用提供的数据类型,而不是定义自己的数据类型
2.他们愿意放弃灵活性,让单个column具有多种类型,具体取决于行,以换取单行中的单个类型
为了使客户轻松拥有Apache HBase的其它优势(无限扩展,数百万行,模式演变等),同时提供类似RDBMS的功能(ANSI SQL,简单join,开箱即用的数据类型等),我们在CDH上引入了对Apache Phoenix的支持。
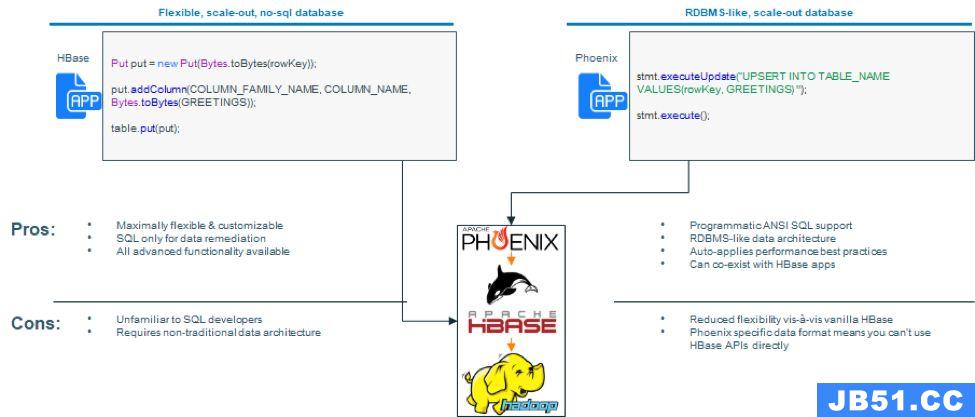
如果优化HBase,基于Phoenix的应用程序同样也会受益,从而获得更好的性能。例如Phoenix实现了主键的加盐 - 因此HBase用户不用考虑Rowkey的设计。
此外,基于Phoenix的应用程序可以与HBase应用程序共存 - 这意味着您可以使用单个HBase集群来支持这两者。使用Phoenix,客户可以继续使用他们喜欢的BI和仪表盘工具,就像以前使用Hive和Impala一样。
在CDH中从安全和治理角度,Phoenix使用HBase ACLs来实现Phoenix表的基于角色访问控制。同时Cloudera Navigatior也会捕获Phoenix的审计信息。
现在,Cloudera发布的主要是基于CDH5.16.2的Phoenix4.14.1 Parcel包,不久之后我们将会发布CDH6.2的Phoenix5.0的Parcel包,因为C6中的HBase已经是2.x,所以会不一样。
已有的HDP客户其实一直可以享有Apache Phoenix的技术支持,使用HDP的HBase的用户几乎有一半正在使用Phoenix,同时Phoenix在HBase的用户社区也很受欢迎。
使用Apache Phoenix构建核心应用程序,请点击以下链接下载Phoenix:
https://www.cloudera.com/downloads/phoenix.html
Q)Phoenix适用于什么样的工作负载
Phoenix支持与HBase相同的用例场景,主要是低延迟,高并发的工作负载。但是,Phoenix还可以更轻松地利用底层数据进行仪表板和BI应用。
Q) Phoenix的授权机制是什么?
Phoenix依赖于HBase的授权机制,对于CDH客户,可以使用HBase ACL。对于HDP客户,可以使用Ranger。
Q) Phoenix的可扩展性怎样?已知的最大的集群是哪个?
Phoenix可以扩展到数百TB的数据。最大的客户拥有超过0.5 PB的数据,由Phoenix管理。该用例的详细信息可以在PhoenixCon archives找到:
https://phoenix.apache.org/phoenixcon-archives.html
也可以在今年早些时候用户自己的视频中 NoSQL day videos查看:
https://www.youtube.com/playlist?list=PLSAiKuajRe2l6If7Az2PHIDG8vsJly9CH
Q) Phoenix是否支持地理空间二级索引?支持什么级别的空间数据?
它对地理空间(geo-spatial)数据的支持有限。GeoMesa在HBase上提供了一个geospatial层,可以支持这种需求并与客户应用程序集成。Phoenix,GeoMesa以及JanusGraph和OpenTSDB都可以共存于一个HBase集群中。
Q) 如何创建和使用索引?
有关索引的详细信息,请参阅Phoenix Secondary Indexing页面。
https://phoenix.apache.org/secondary_indexing.html
从Phoenix 4.8.0开始,使用本地索引不需要进行任何配置。
Q) 做索引的column数量有限制吗?
与RDBMS一样,HBase的二级索引其实就是使用另一张索引表来实现的,这张表包含索引和源数据的链接。如果你对所有column都进行索引,你的维护成本会大大上升。对于索引的选择你还同时需要考虑读多写少可以考虑Global indexes(全局索引),如果写多读少,则可以考虑Local indexes(本地索引)。
看完了这篇文章,相信你对“Apache Phoenix for CDH的示例分析”有了一定的了解,如果想了解更多相关知识,欢迎关注编程之家行业资讯频道,感谢各位的阅读!
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。