
在前面的文章中我们进行学习了Spring Cloud的使用,那么我们对各个组件的使用是不是还不够深入,那么从今天开始我们将逐一进行学习Spring Cloud Netflix中所提供的组件。今天我们现看下服务注册与发现Eureka。
在看Eureka之前我们先看下简略版的服务注册与发现的机制
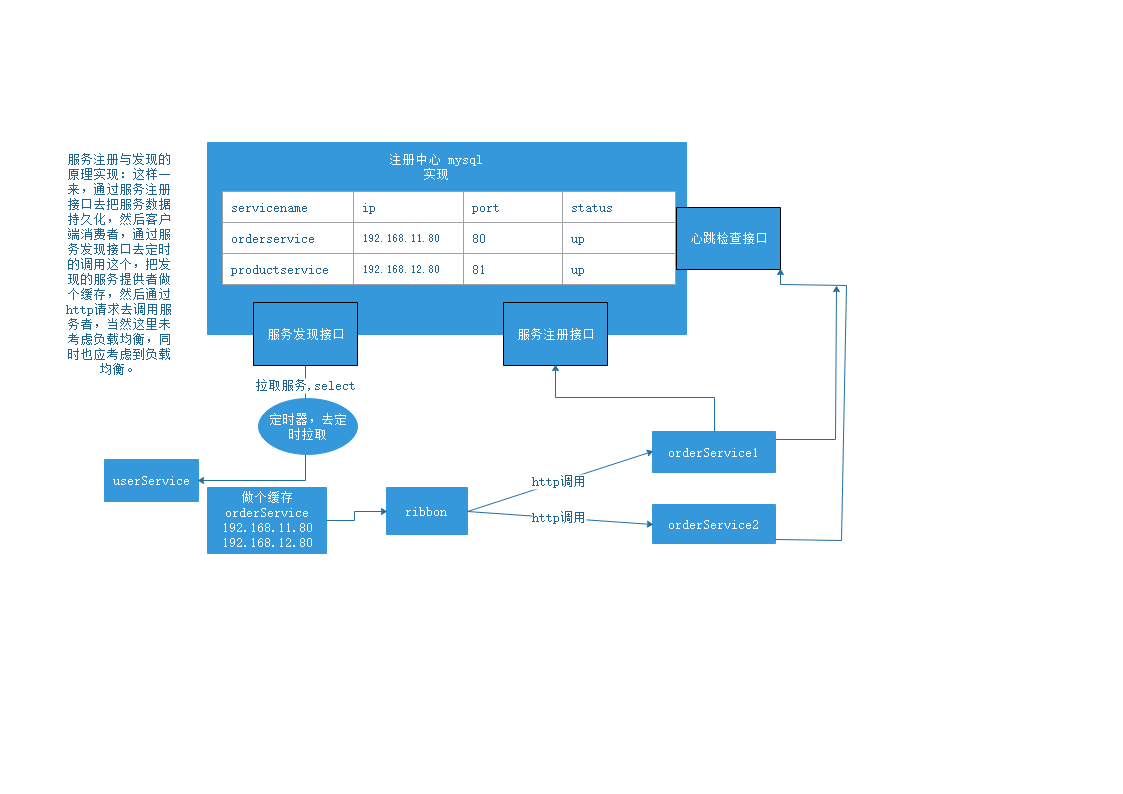 ](https://imgchr.com/i/dO4A81)
](https://imgchr.com/i/dO4A81)
服务发现接口:客户端调用时通过这个接口时,去数据库中查询到这个服务的状态,
服务注册接口:当服务提供者进行发布时通过服务注册接口进行把服务信息保存到数据库中,供服务发现接口调用。
心跳检测接口:定时的检测服务是否可用,不可用时将信息告诉服务提供者,令其再次发布,更新数据库中的服务状态。
当服务进行发布的时候通过服务注册接口去把服务信息持久话到数据库,客服端消费者通过服务发现接口去定时的取数据库中查询,看看服务提供者是否在线。如果在线则进行调用,在服务提供者通过服务注册接口去保存数据库的同时,需要调用心跳检查接口,如果掉线从新写入数据库,更改其状态。
Eureka
Eureka是一项基于REST(代表性状态转移)的服务,主要在AWS云中用于查找服务,以实现负载均衡和中间层服务器的故障转移。 我们称此服务为Eureka服务器服务注册与发现。 Eureka还带有一个基于Java的客户端组件Eureka Client,它使与服务的交互变得更加容易。 客户端还具有一个内置的负载平衡器,可以执行基本的循环负载平衡。 Netflix使用更复杂的负载均衡器将Eureka包装起来,以基于流量,资源使用,错误条件等多种因素提供加权负载均衡,以提供出色的弹性.
原理:主管服务注册与发现,也就是微服务的名称注册到Eureka,就可以通过Eureka找到微服务,而不需要修改服务调用的配置文件。
分析:Spring Cloud封装了Netflix公司开发的Eureka模块来实现服务的注册与发现,采用的c-s的设计架构,Eureka Server作为服务注册功能的服务器,他是服务注册中心。而系统的其他微服务,使用Eureka的客户端连接到Eureka Server并维持心跳。这样系统的维护人员可以通过Eureka Server来监控系统中的各个微服务是否正常运行。Spring Cloud的一些其他模块(比如Zuul)就可以通过Eureka Server来发现系统其他的微服务,并执行相关逻辑。
Eureka Server
Eureka Server提供服务注册服务,各个节点启动后,会在Eureka Server中进行注册, 这样Eureka Server中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。
Eureka Client
Eureka Client是一个Java客户端, 用于简化Eureka Server的交互,客户端同时也具备一个内置的、 使用轮询(round-robin)负载算法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳(默认周期为30秒),以证明当前服务是可用状态 (30秒发送一次心跳更新租约。 如果客户端几次无法续签租约)。 如果Eureka Server在一定的时间(默认90秒)未收到客户端的心跳,Eureka Server将会从服务注册表中把这个服务节点移除。 任何区域的客户端都可以查找注册表信息(每30秒发生一次)以查找其服务(可能在任何区域)并进行远程调用。
Eureka Server的自我保护机制
如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像ZooKeeper那样使整个注册服务瘫痪。
Eureka和ZooKeeper对比
著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性 Consistency)、A(可用性 Availability)和P(分区容错性 Partition tolerance)。由于分区容错性在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。
ZooKeeper保证CP(一致性和分区容错性)
ZooKeeper是一个开源的分布式应用程序协调服务,提供的功能包括命名服务、配置管理、集群管理、分布式锁。
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是ZooKeeper会出现这样一种情况,当Master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。
问题在于,选举leader的时间太长,30 ~ 120s,且选举期间整个ZooKeeper集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得ZooKeeper集群失去Master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。zk选举机制必须是过半机制。
Eureka保证AP(可用性和分区容错性)
Eureka在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。
参考:https://www.jianshu.com/p/6a3db6939fb0
原文地址:https://blog.csdn.net/qq_37256896/article/details/112430946
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。