

selenium版本安装后启动Firefox出现异常:'geckodriver' executable needs to be in PATH
selenium默默的升级到了3.0,然而网上的教程都是基于selenium2的,最近有不少小伙伴踩坑了,决定有必要出这一篇,帮助刚入门的小伙伴们解决好环境问题。
selenium+python环境搭配:
selenium2+firefox46以下版本(无需驱动包,firefox喜欢偷偷升级,你懂的)
selenium3+firefix47以上版本(必须下载驱动:geckodriver.exe,且添加到环境变量)
一、遇到异常
1.安装完selenium后,再cmd进入python环境
2.从selenium导入webdriver
3.启动Firefox浏览器
>>python
>>from selenium import webdriver
>>webdriver.Firefox()
然后出现以下异常:'geckodriver' executable needs to be in PATH

二、解决方案
1.'geckodriver' executable needs to be in PATH,这句话意思就是说,geckodriver.exe的驱动文件需要添加到环境变量下,
selenium2是默认支持firefox的,不需要驱动包,但是,selenium3需要驱动包的支持了,于是就有了上面的问题
2.解决办法一:继续使用selenium3,去下载驱动包,然后加到环境变量下(不推荐此办法,因为解决完这个问题后,后面还会接着有其它问题)
3.解决办法二:selenium3降级到selenium2(接下来会介绍)
三、检查pip环境
1.打开cmd,输入pip,检查pip环境是否正常
>>pip

2.如果输入pip出现提示:Did not provide a command 说明pip环境有问题,临时解决办法,输入pip时候加上后缀pip.exe就可以了,具体原因看下一篇解决办法。
四、pip查看selenium版本号
1.打开cmd,输入pip show selenium
>>pip show selenium
2.看红色区域位置版本号显示:2.53.0,显示的就是当前使用的版本号
(如果你这里显示的是3.0开头,就需要接下来步骤了)

五、pip降级selenium
1.为了避免与之前安装的selenium版本冲突,先找到selenium3.0目录:python\Lib\site-packages目录
把里面selenium开头的文件全部删除就可以了。python所有的第三方包都在这个目录下面。
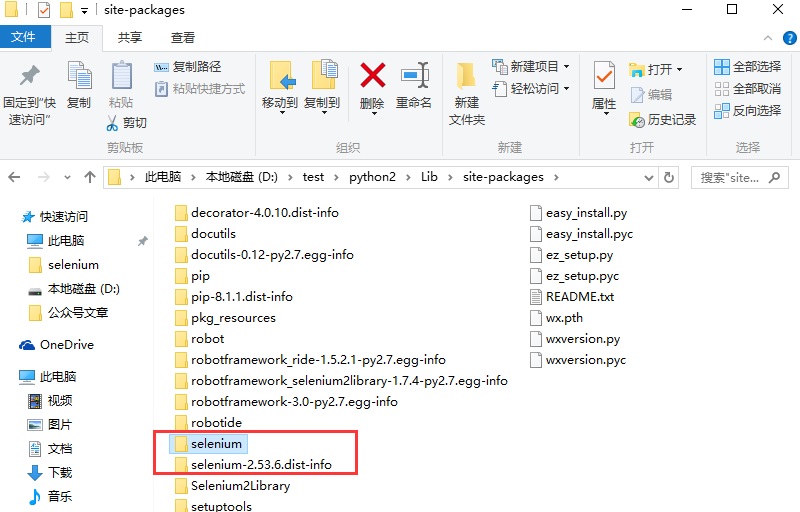
2.打开cmd,输入pip install selenium==2.53.6(注意是两个==,中间不要留空格,这里推荐2.53.6的版本)
>>pip install selenium==2.53.6

六、升级pip版本
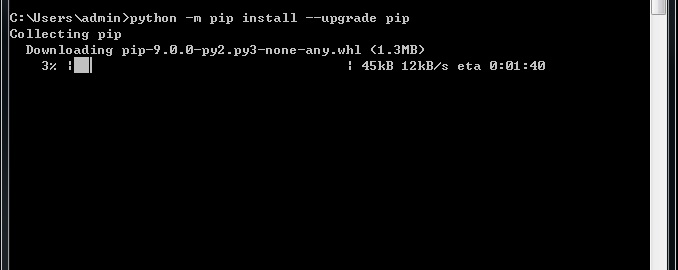
1.在使用pip过程中如果出现下方红色区域字样,就是说pip版本过低了,建议升级
2.如何升级pip呢?看最后一句话:python -m pip install --upgrade pip

3.把上面对应的提示照着敲一遍就可以了
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。