
1、 什么是InfluxDB
具体请看[时序数据库InfluxDB介绍](https://blog.csdn.net/m0_46577050/article/details/123221935)
2、InfluxDB数据库操作
用户操作
显示用户
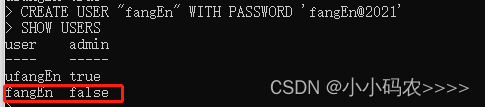
SHOW USERS

创建用户
CREATE USER “fangEn” WITH PASSWORD ‘fangEn@2021’
赋予用户管理员权限
GRANT ALL PRIVILEGES TO fangEn

创建管理员权限的用户
CREATE USER “fangEn” WITH PASSWORD ‘fangEn@2021’ WITH ALL PRIVILEGES
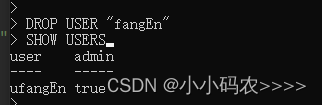
删除用户
DROP USER “fangEn”
显示数据库
使用命令 influx进入数据库中
使用命令 show databases 显示数据库

说明:_internal数据库是用来存储InfluxDB内部的实时监控数据的。
操作数据库基本命令
create database test 创建数据库
drop database kkkkk 删除数据库
use mydb 进入指定数据库
InfluxDB操作数据库表
在 InfluxDB 当中,并没有表(table)这个概念,取而代之的是 MEASUREMENTS,MEASUREMENTS 的功能与传统数据库中的表一致,因此我们也可以将 MEASUREMENTS 称为InfluxDB 中的表。
显示所有表
SHOW MEASUREMENTS
新建表
InfluxDB 中没有显式的新建表的语句,只能通过 insert 数据的方式来建立新表。
insert test,CO2=20,TVOC=0.1 ts=0.64;
查询表数据
select * from test

InfluxDB的time是以纳秒显示
执行 precision rfc3339 更换为国际时间,与北京时间相差8小时

在查询语句后面加上 tz(‘Asia/Shanghai’) 可以显示为北京时间

删除表
drop measurement
数据保存策略(Retention Policies)
influxDB是没有提供直接删除数据记录的方法,但是提供数据保存策略,主要用于指定数据保留时间,超过指定时间,就删除这部分数据。(设置类似于定期清理的语句)
保留策略语法
CREATE RETENTION POLICY <retention_policy_name> ON <database_name> DURATION REPLICATION [SHARD DURATION ] [DEFAULT]
<retention_policy_name>:保留策略的名称(自定义)
<database_name>:为哪个数据库创建保留策略
:该保留策略对应的数据过期时间
REPLICATION:副本因子 SHARD DURATION:分片组的默认时长
[DEFAULT]:是否为默认策略
创建数据保留策略
CREATE RETENTION POLICY “influx_retention” ON “mydb” DURATION 30d REPLICATION 1 DEFAULT
influx_retention:策略名;
mydb:具体的数据库名;
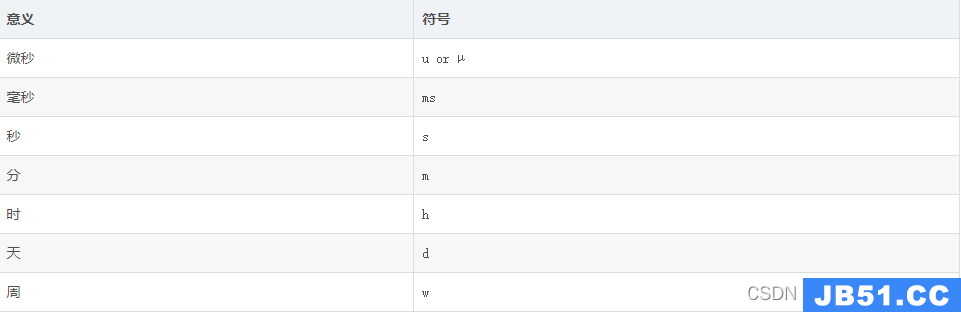
30d:保存30天,30天之前的数据将被删除,influxdb具有各种事件参数,比如:h(小时),d(天),w(星期/周);
replication 1:副本个数,一般为1就可以了;
default:设置为默认策略
查看保留期
SHOW RETENTION POLICIES ON mydb
修改保留期
ALTER RETENTION POLICY “influx_retention” ON mydb DURATION 15d
删除保留期
DROP RETENTION POLICY “influx_retention” ON mydb
连续查询
连续查询 Continuous queries(CQ) 是 InfluxQL 的一种查询类型。它会按照用户指定的查询规则,自动地、周期地查询实时数据并执行指定运算,然后将查询结果保存在一张指定的表中。
通过创建连续查询,用户可以指定InfluxDB执行连续查询的时间间隔、单次查询的时间范围以及查询规则。InfluxDB会根据用户指定的规则,定期地将过去一段时间内的原始时序数据以用户所期望的方式保存至新的结果表中,从而降低存储数据的时间精度,大大减少新表的数据量。同时,将查询结果保存在指定的数据表中,也便于用户直接查询所关心的内容,从而降低查询的运算复杂度,提升查询效率。
连续查询的使用场景
使用连续查询是最优的降低采样率的方式,连续查询和存储策略搭配使用将会大大降低InfluxDB的存储空间的占用量,使其维持在一个相对稳定的水平。而且使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了便利。
比如说,要做一个曲线图,这个曲线图需要按照秒、分、小时对收集到的测量值求平均值/最大值/最小值,查询指定时间段内的,且一查就是几百条甚至上千条,把查询出来的数据在曲线图上展示。这样的场景就特别适合连续查询
连续查询的语法
# 基本语法
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
BEGIN
<cq_query>
END
cq_name :该条连续查询的名字;database_name:连续查询所在数据库的名字;
cq_query:具体的连续查询语句,cq_query语法是InfluxQL协议格式的。
# cq_query 语法
SELECT <function[s]> INTO <destination_measurement>
FROM <measurement> [WHERE <stuff>]
GROUP BY time(<interval>)[,<tag_key[s]>]
function[s]:要查询的字段及数据处理的内置函数,可以是聚合函数,也可以是选择函数,看业务需要;
destination_measurement:保存查询结果的目标表;若目标表不存在,InfluxDB自动创建;目标表不可重复,否则会报错;
measurement:连续查询语句所查询的目标表;
stuff:具体的查询条件,可选参数;
interval:连续查询语句执行的时间间隔与查询的时间范围;
tag_key[s]:归类的标签字段,可选参数。
# 高级语法
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
RESAMPLE EVERY <interval> FOR <interval>
BEGIN
<cq_query>
END
RESAMPLE EVERY :采样执行频次。如RESAMPLE EVERY 30m:表示30分钟执行一次。RESAMPLE FOR :采样时间范围。如RESAMPLE FOR 60m:时间范围 = now() - for间隔(60m)。RESAMPLE EVERY 30m FOR 60m:表示每30分钟执行一次60分钟内的数据计算。
如果 FOR 间隔小于执行的时间间隔,就会报错;所以必须大于等于时间间隔。
实例
注意一定要有数据才能创建出来,不然执行成功也不会创建。
连续查询(电量表小时最大值)
CREATE CONTINUOUS QUERY "cq_h_ammeter_colln_data" ON "fangendb"
RESAMPLE EVERY 1h FOR 90m
BEGIN
SELECT max("energy") as "energy" INTO "ammeter_colln_h_data" FROM "ammeterCollnData" GROUP BY time(1h),"name"
END
CREATE CONTINUOUS QUERY "cq_h_ammeter_data" ON "fangendb"
RESAMPLE EVERY 1h FOR 90m
BEGIN
SELECT DIFFERENCE(max("energy")) as "energy" ,DIFFERENCE(min("energy")) as "energy1" INTO "ammeter_h_data" FROM "ammeterCollnData" GROUP BY time(1h),"name"
END
-----DIFFERENCE()函数下文有解释
influxDb常用函数
Aggregations 集合
COUNT() 计数
DISTINCT() 返回唯一字段列表
INTEGRAL() 返回曲线阴影面积
MEAN() 返回数学平均值
MEDIAN() 返回中间值
MODE() 返回出现频率最高的值
SPREAD() 返回最大最小之间的差
STDDEV() 返回标准差
SUM() 总和
Selectors 选择
BOTTOM() 返回最小的N个数,按时间排序
FIRST() 返回第一个
LAST() 返回最后一个
MAX() 返回最大值
MIN() 返回最小值
PERCENTILE() 返回百分比的值 0%等于MIN(),50%等于MEDIAN(),100%等于MAX()
SAMPLE() 返回N个随机点
TOP() 返回最大的N个数,按时间排序
Transformations 转换
ABS() 返回绝对值
ACOS() 返回反余弦 -1 到 1 之间
ASIN() 返回反正弦 -1 到 1 之间
ATAN() 返回反正切 -1 到 1 之间
ATAN2() 返回以弧度为单位的y / x的反正切值。
CEIL() 返回四舍五入的值
COS() 返回余弦值
CUMULATIVE_SUM() 后续结果累加
DERIVATIVE() 计算后续结果的变化量
DIFFERENCE() 返回相减的结果 后-前一个字段中连续的时间值之间的差异,字段类型必须是长整型或float64。
ELAPSED() 返回后续时间差
EXP() 返回指数
FLOOR() 去除小数
HISTOGRAM() 直方图,暂不支持
LN() 返回自然对数
LOG() 返回第二个变量为底的对数
LOG2() 范围以2为底的对数
LOG10() 返回以10为底的对数
MOVING_AVERAGE() 返回后续字段的滚动平均值
NON_NEGATIVE_DERIVATIVE() 返回后续结果的非负变化率
NON_NEGATIVE_DIFFERENCE() 返回后续结果相减的非负数
POW() 返回 第二个参数作为幂的值
ROUND() 和四舍五入还未区分清楚
SIN() 返回正弦值
SQRT() 返回平方根
TAN() 返回正切值
Predictors 分析预判
HOLT_WINTERS() 霍尔特-温特(Holt-Winters)时间序列分析和预报方法
SELECT HOLT_WINTERS[_WITH-FIT](<function>(<field_key>),<N>,<S>) [INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
influxDb查询操作
#----综合使用
书写顺序
select distinct * from '表名' where '限制条件' group by '分组依据' having '过滤条件' order by limit '展示条数'
执行顺序
from -- 查询
where -- 限制条件
group by -- 分组
having -- 过滤条件
order by -- 排序
limit -- 展示条数
distinct -- 去重
select -- 查询的结果
时间查询
查询某个范围内最大值,平均值,最小值
写总结还是有好处的 在这发现可以使用多个函数,而我代码里面写了三条sql 对自己无语了。
SELECT max(temperature) as "max",MEAN(temperature) as "MEAN",min(temperature) as "min",time as created_time FROM "airDevDatadb" WHERE time >= '2022-12-31T16:00:00Z' AND time <= '2023-12-30T16:00:00Z'
查询一天内每小时最大,平均,最小值。可以把时间转换为北京时间(tz(‘Asia/Shanghai’))
SELECT max(temperature) as "highest",MEAN(temperature) as "average",min(temperature) as "minimum",time FROM "airDevDatadb" WHERE time >= '2023-07-18 00:00:00' GROUP BY time(1h) tz('Asia/Shanghai')
查询最近一条非空值
SELECT last(CO2) as CO2,last(PM25) as PM25,last(TVOC) as TVOC,last(temperature) as temperature,last(humidity) as humidity FROM "airDevDatadb"
查询一年内每月最大,平均,最小值
SELECT max(temperature) as "highest",time FROM "airDevDatadb" WHERE time >= '2022-12-31T16:00:00Z' AND time <= '2023-12-30T16:00:00Z' GROUP BY time(30d) tz('Asia/Shanghai')
这里显示每个月的日期不是当月的第一天,暂时还没有找到好办法。
3、代码实操
引入依赖
<dependency>
<groupId>plus.ojbk</groupId>
<artifactId>influxdb-spring-boot-starter</artifactId>
<version>1.0.2</version>
</dependency>
数据源
influx:
url: http://127.0.0.1:8086
user: admin
password: 123456
database: fangendb # 数据库名
retention_policy: default
retention_policy_time: 36500d
mapper-location: com.fangen.influxdb.maper
创建实体类
@Measurement(name = “device”)对应表名
时间必须使用LocalDateTime 使用date类型会报错 我这里没有用时间类型
@Data
@Measurement(name = "airDevDatadb")
public class AirDevData {
/** 网关 */
private String sn;
/** 设备名称*/
@Tag
private String name;
/** 设备id*/
private String id;
/** 上报实际戳 */
private Long ts;
/** 设备编号 */
private String dev;
/** 温度 */
private Double temperature;
/** 湿度 */
private Double humidity;
/** PM25 */
private Double PM25;
/** TVOC */
private Double TVOC;
/** CO2 */
private Double CO2;
/** 湿度 */
private String pKey;
private String ver;
private Long eq_id;
private String created_time;
/**
* 位置id
*/
private String locationId;
}
写控制类
public class AirDevController extends BaseController
{
@Autowired
private IAirDevService airDevService;
@Autowired
private InfluxDbService influxDbService;
/**
*
* 查询2小时实时查询列表
*/
//@PreAuthorize"@ss.hasPermi('air_quality:空气质量:list')")
@GetMapping("/list")
public R<List<AirDevData>> list(){
String sql = " SELECT * FROM \"airDevDatadb\" WHERE time >= now()-2h ";
List<AirDevData> list = influxDbService.query(AirDevData.class,sql);
return R.ok(list);
}
}
创建InfluxDbService实现类 经常用到的方法都在这
@Service
@Slf4j
public class InfluxDbServiceImpl implements InfluxDbService {
@Autowired
private InfluxDB influxDB;
@Autowired
private InfluxProperty influxProperty;
@Override
public Boolean ping() {
boolean isConnected = false;
Pong pong;
try {
pong = influxDB.ping();
if (pong != null) {
isConnected = true;
}
} catch (Exception e) {
e.printStackTrace();
}
return isConnected;
}
@Override
public void createDataBase(String... dataBaseName) {
if (dataBaseName.length > 0) {
influxDB.createDatabase(dataBaseName[0]);
return;
}
if (influxProperty.getDatabase() == null) {
//log.error("如参数不指定数据库名,配置文件 spring.influx.dataBaseName 必须指定");
return;
}
influxDB.createDatabase(influxProperty.getDatabase());
}
@Override
public void deleteDataBase(String... dataBaseName) {
if (dataBaseName.length > 0) {
influxDB.deleteDatabase(dataBaseName[0]);
return;
}
if (influxProperty.getDatabase() == null) {
//log.error("如参数不指定数据库名,配置文件 spring.influx.dataBaseName 必须指定");
return;
}
influxDB.deleteDatabase(influxProperty.getDatabase());
}
/**
* 删除表数据
* @param sql
*/
@Override
public void deleteTableDate(String sql) {
QueryResult results = influxDB.query(new Query(sql,influxProperty.getDatabase()));
//System.out.println("dddddddddddddddddddd"+results.getError());
}
@Override
public <T> void insert(T object) {
// 构建一个Entity
Object first = Lang.first(object);
Class clazz = first.getClass();
// 表名
Boolean isAnnot = clazz.isAnnotationPresent(Measurement.class);
if (!isAnnot) {
// log.error("插入的数据对应实体类需要@Measurement注解");
return;
}
Measurement annotation = (Measurement) clazz.getAnnotation(Measurement.class);
// 表名
String measurement = annotation.name();
Field[] arrfield = clazz.getDeclaredFields();
// 数据长度
int size = Lang.eleSize(object);
String tagField = ReflectUtils.getField(object,Tag.class);
if (tagField == null) {
// log.error("插入多条数据需对应实体类字段有@Tag注解");
return;
}
BatchPoints batchPoints = BatchPoints
.database(influxProperty.getDatabase())
// 一致性
.consistency(ConsistencyLevel.ALL)
.build();
for (int i = 0; i < size; i++) {
Map<String,Object> map = new HashMap<>();
Builder builder = Point.measurement(measurement);
for (Field field : arrfield) {
// 私有属性需要开启
field.setAccessible(true);
Object result = first;
try {
if (size > 1) {
List objects = (List) (object);
result = objects.get(i);
}
if (field.getName().equals(tagField)) {
builder.tag(tagField,field.get(result).toString());
} else {
map.put(field.getName(),field.get(result));
}
} catch (IllegalAccessException e) {
// log.error("实体转换出错");
e.printStackTrace();
}
}
builder.fields(map);
batchPoints.point(builder.build());
}
influxDB.write(batchPoints);
}
@Override
public <T> void insertSubid(T object,String id) {
// 构建一个Entity
Object first = Lang.first(object);
Class clazz = first.getClass();
// 表名
Boolean isAnnot = clazz.isAnnotationPresent(Measurement.class);
if (!isAnnot) {
// log.error("插入的数据对应实体类需要@Measurement注解");
return;
}
Measurement annotation = (Measurement) clazz.getAnnotation(Measurement.class);
// 表名
String measurement = annotation.name()+"_"+id;
Field[] arrfield = clazz.getDeclaredFields();
// 数据长度
int size = Lang.eleSize(object);
String tagField = ReflectUtils.getField(object,Tag.class);
if (tagField == null) {
// log.error("插入多条数据需对应实体类字段有@Tag注解");
return;
}
BatchPoints batchPoints = BatchPoints
.database(influxProperty.getDatabase())
// 一致性
.consistency(ConsistencyLevel.ALL)
.build();
for (int i = 0; i < size; i++) {
Map<String,field.get(result));
}
} catch (IllegalAccessException e) {
// log.error("实体转换出错");
e.printStackTrace();
}
}
builder.fields(map);
batchPoints.point(builder.build());
}
influxDB.write(batchPoints);
}
@Override
public <T> void insertL(T object,Map<String,Object> mapin) {
// 构建一个Entity
Object first = Lang.first(object);
Class clazz = first.getClass();
// 表名
Boolean isAnnot = clazz.isAnnotationPresent(Measurement.class);
if (!isAnnot) {
// log.error("插入的数据对应实体类需要@Measurement注解");
return;
}
Measurement annotation = (Measurement) clazz.getAnnotation(Measurement.class);
// 表名
String measurement = annotation.name();
Field[] arrfield = clazz.getDeclaredFields();
// 数据长度
int size = Lang.eleSize(object);
String tagField = ReflectUtils.getField(object,Tag.class);
if (tagField == null) {
// log.error("插入多条数据需对应实体类字段有@Tag注解");
return;
}
BatchPoints batchPoints = BatchPoints
.database(influxProperty.getDatabase())
// 一致性
.consistency(ConsistencyLevel.ALL)
.build();
Map<String,Object> map = new HashMap<>();
Builder builder = Point.measurement(measurement);
for (int i = 0; i < size; i++) {
for (Field field : arrfield) {
// 私有属性需要开启
field.setAccessible(true);
Object result = first;
try {
if (size > 1) {
List objects = (List) (object);
result = objects.get(i);
}
if (field.getName().equals(tagField)) {
builder.tag(tagField,field.get(result));
}
} catch (IllegalAccessException e) {
// log.error("实体转换出错");
e.printStackTrace();
}
}
}
if(mapin!=null){
// 3. 使用Iterator遍历
Iterator<Map.Entry<String,Object>> it = mapin.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String,Object> entry = it.next();
// System.out.println("key = " + entry.getKey() + ",value = " + entry.getValue());
map.put(entry.getKey(),entry.getValue());
}
}
builder.fields(map);
batchPoints.point(builder.build());
influxDB.write(batchPoints);
}
@Override
public <T> List<T> query(Class<T> clazz,String sql) {
if (influxProperty.getDatabase() == null) {
//log.error("查询数据时配置文件 spring.influx.dataBaseName 必须指定");
return null;
}
QueryResult results = influxDB.query(new Query(sql,influxProperty.getDatabase()));
if (results != null) {
if (results.getResults() == null) {
return null;
}
List<Object> list = new ArrayList<>();
for (Result result : results.getResults()) {
List<Series> series = result.getSeries();
if (series == null) {
list.add(null);
continue;
}
for (Series serie : series) {
List<List<Object>> values = serie.getValues();
Map<String,String> objectMap = serie.getTags();
List<String> columns = serie.getColumns();
// 构建Bean
list.addAll(getQueryData(clazz,columns,values));
}
}
return Json.fromJsonAsList(clazz,Json.toJson(list));
}
return null;
}
@Override
public <T> List<T> query(T object,Class<T> clazz,String sql) {
if (influxProperty.getDatabase() == null) {
//log.error("查询数据时配置文件 spring.influx.dataBaseName 必须指定");
return null;
}
String tagField = ReflectUtils.getField(object,Tag.class);
QueryResult results = influxDB.query(new Query(sql,values,objectMap,tagField));
}
}
return Json.fromJsonAsList(clazz,Json.toJson(list));
}
return null;
}
/**
* 自动转换对应Pojo
*
* @param values
* @return
*/
public <T> List<T> getQueryData(Class<T> clazz,List<String> columns,List<List<Object>> values,String> tags,String tg) {
List results = new ArrayList<>();
for (List<Object> list : values) {
BeanWrapperImpl bean = null;
Object result = null;
try {
result = clazz.newInstance();
bean = new BeanWrapperImpl(result);
bean.setPropertyValue(tg,tags.get(tg));
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}catch (Exception e){
e.printStackTrace();
}
for (int i = 0; i < list.size(); i++) {
// 字段名
String filedName = columns.get(i);
if (filedName.equals("Tag")) {
continue;
}
try {
Field field = clazz.getDeclaredField(filedName);
} catch (NoSuchFieldException e) {
continue;
}
// 值
Object value = list.get(i);
bean.setPropertyValue(filedName,value);
}
results.add(result);
}
return results;
}
/**
* 自动转换对应Pojo
*
* @param values
* @return
*/
public <T> List<T> getQueryData(Class<T> clazz,List<List<Object>> values) {
List results = new ArrayList<>();
for (List<Object> list : values) {
BeanWrapperImpl bean = null;
Object result = null;
try {
result = clazz.newInstance();
bean = new BeanWrapperImpl(result);
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
for (int i = 0; i < list.size(); i++) {
// 字段名
String filedName = columns.get(i);
if (filedName.equals("Tag")) {
continue;
}
try {
Field field = clazz.getDeclaredField(filedName);
} catch (NoSuchFieldException e) {
continue;
}
// 值
Object value = list.get(i);
bean.setPropertyValue(filedName,value);
}
results.add(result);
}
return results;
}
}
@Configuration
@Data
public class InfluxProperty {
@Value("${spring.influx.url}")
private String url;
@Value("${spring.influx.user}")
private String user;
@Value("${spring.influx.password}")
private String password;
@Value("${spring.influx.database}")
private String database;
@Value("${spring.influx.retention_policy}")
private String retentionPolicy;
@Value("${spring.influx.retention_policy_time}")
private String retentionPolicyTime;
}
原文地址:https://blog.csdn.net/weixin_44831330/article/details/131782086
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。